
zookeeper簡介及叢集搭建步驟
1、zookeeper概念
- zookeeper是一個分散式協調服務
- zookeeper是為別的分散式程式服務的
- zookeeper本身就是一個分散式程式(只要半數以上節點存活,zookeeper就能正常服務。)
- zookeeper的服務範圍:主從協調、伺服器節點動態上下線、統一配置管理、分散式共享鎖、統一名稱服務……
- zookeeper底層其實只提供了兩個功能:
a.管理(儲存、讀取)使用者程式提交的資料
b.為使用者程式提交資料節點監聽服務
2、zookeeper叢集機制
半數機制:
3、zookeeper特性
- Zookeeper:一個leader,多個follower組成的叢集
- 全域性資料一致:每個server儲存一份相同的資料副本,client無論連線到哪個server,資料都是一致的
- 分散式讀寫,更新請求轉發,由leader實施
- 更新請求順序進行,來自同一個client的更新請求按其傳送順序依次執行
- 資料更新原子性,一次資料更新要麼成功,要麼失敗
- 實時性,在一定時間範圍內,client能讀到最新資料
4、zookeeper資料結構
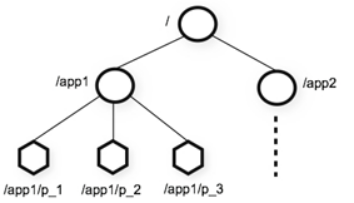
- 層次化的目錄結構,命名符合常規檔案系統規範(見下圖)
- 每個節點在zookeeper中叫做Znode,並且其有一個唯一的路徑標識
- 節點Znode可以包含資料和子節點(但是EPHEMERAL型別的節點不能有子節點)
- 客戶端應用可以在節點上設定監視器
- 節點型別:
1、Znode有兩種型別:
短暫(ephemeral)(斷開連線自己刪除)
持久(persistent)(斷開連線不刪除)
2、Znode有四種形式的目錄節點(預設是persistent )
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019 )
EPHEMERAL
EPHEMERAL_SEQUENTIAL
3、建立znode時設定順序標識,znode名稱後會附加一個值,順序號是一個單調遞增的計數器,由父節點維護
4、在分散式系統中,順序號可以被用於為所有的事件進行全域性排序,這樣客戶端可以通過順序號推斷事件的順序
5、zookeeper原理及內部選舉機制
原理:zookeeper在配置檔案中並沒有指定master和slave,但是,zookeeper在工作時,只有一個節點為leader,其餘節點為follower,leader是通過內部的選舉機制臨時產生的。
選舉機制:(兩種情況)
(1)全新叢集paxos
假設有五臺伺服器組成的zookeeper叢集,它們的id從1-5,同時它們都是最新啟動的,也就是沒有歷史資料,在存放資料量這一點上,都是一樣的.假設這些伺服器依序啟動,來看看會發生什麼.
1) 伺服器1啟動,此時只有它一臺伺服器啟動了,它發出去的報沒有任何響應,所以它的選舉狀態一直是LOOKING狀態
2) 伺服器2啟動,它與最開始啟動的伺服器1進行通訊,互相交換自己的選舉結果,由於兩者都沒有歷史資料,所以id值較大的 伺服器2勝出,但是由於沒有達到超過半數以上的伺服器都同意選舉它(這個例子中的半數以上是3),所以伺服器1,2還是繼續 保持LOOKING狀態.
3) 伺服器3啟動,根據前面的理論分析,伺服器3成為伺服器1,2,3中的老大,而與上面不同的是,此時有三臺伺服器選舉了它,所以 它成為了這次選舉的leader.
4) 伺服器4啟動,根據前面的分析,理論上伺服器4應該是伺服器1,2,3,4中最大的,但是由於前面已經有半數以上的伺服器選舉 了伺服器3,所以它只能接收當小弟的命了.
5) 伺服器5啟動,同4一樣,當小弟.
(2)非全新叢集(資料恢復)
初始化的時候,是按照上述的說明進行選舉的,但是當zookeeper運行了一段時間之後,有機器down掉,重新選舉時,選舉過程就相對複雜了,需要加入資料id、leader id和邏輯時鐘
資料id:資料新的id就大,資料每次更新都會更新id。
Leader id:就是我們配置的myid中的值,每個機器一個。
邏輯時鐘:這個值從0開始遞增,每次選舉對應一個值,也就是說: 如果在同一次選舉中,那麼這個值應該是一致的; 邏輯時鐘 值越大,說明這一次選舉leader的程序更新.
選舉的標準就變成:
1、邏輯時鐘小的選舉結果被忽略,重新投票
2、統一邏輯時鐘後,資料id大的勝出
3、資料id相同的情況下,leader id大的勝出,根據這個規則選出leader。
6、zookeeper叢集搭建
1.準備三臺機器,分別安裝JDK1.8;
2.下載zookeeper
http://zookeeper.apache.org/releases.html
3. 解壓 tar -zxvf /usr/local/zookeeper-3.4.13.tar.gz
4 .配置zookeeper環境變數
目的:每次啟動服務就不需要定位到Zookeeper的bin目錄了
vi /etc/profile
在最後加上:
#zookeeper
export ZK_HOME=/usr/local/zookeeper-3.4.11
export PATH=$ZK_HOME/bin:$PATH
重新整理環境變數:
source /etc/profile
5 配置zookeeper的配置檔案
進入zookeeper的conf目錄,修改配置檔名
cp zoo_sample.cfg zoo.cfg 開啟:zoo.cfg
tickTime=2000
dataDir=/usr/local/zk/data
dataLogDir=/usr/local/zk/dataLog
clientPort=2181
server.0=192.168.192.128:2888:3888
server.1=192.168.192.129:2888:3888
server.2=192.168.192.130:2888:3888
說明:
server.X=A:B:C
X-代表伺服器編號
A-代表ip
B和C-代表埠,這個埠用來系統之間通訊
7.根據dataDir進行X的配置
建立dataDir目錄data,並且在data資料夾下面建立一個檔案,叫myid,並且在檔案裡寫入server.X對應的X
8.修改防火牆
[[email protected] zookeeper-3.4.11]# firewall-cmd --zone=public --add-port=2888/tcp --permanent
success
[[email protected] zookeeper-3.4.11]# firewall-cmd --zone=public --add-port=3888/tcp --permanent
success
[[email protected] zookeeper-3.4.11]# systemctl restart firewalld 9.啟動
./zkServer.sh start
10.檢視狀態
./zkServer.sh status
另:機器的免密登入與防火牆
設定對映檔案:
vi /etc/hosts
192.168.192.128 hadoop1
192.168.192.129 hadoop2
192.168.192.130 hadoop3
設定三個機器的本機免密登入(三臺機器配置一樣):
ssh-keygen -t rsa ---一直回車即可
cd /root/.ssh/ ---生成了公鑰和私鑰
cat id_rsa.pub >> authorized_keys ---將公鑰追加到授權檔案中
more authorized_keys ---可以檢視到裡面追加的公鑰
ssh hadoop1
配置兩兩之間的免密登入:
將hadoop1中的公鑰複製到hadoop2中ssh-copy-id -i hadoop2 驗證一下:ssh hadoop2
將hadoop3中的公鑰複製到hadoop2中ssh-copy-id -i hadoop2 驗證一下:ssh hadoop2
這樣hadoop2中的授權檔案就有三個機器的公鑰,再把hadoop2中的授權檔案複製給hadoop1和hadoop3
scp /root/.ssh/authorized_keys hadoop1:/root/.ssh/
cp /root/.ssh/authorized_keys hadoop3:/root/.ssh/
將三臺機器的防火牆關閉掉
service iptables stop ,
檢視防火牆
service iptables status