
kettle抓取網頁上的資料儲存到資料表中
今天做一個利用kettle抓取網頁資料儲存到資料表中的demo,如抓取AA市的空氣質量AQI
1.檢視網頁資訊
2.按下開發者工具,檢視虎丘空氣質量日報的請求


3.弄懂了網頁請求,並通過檢視資料格式,可以在資料庫中建表,表格如下

4.接下來就是在kettle中進行操作了
kettle的整體流程如下:
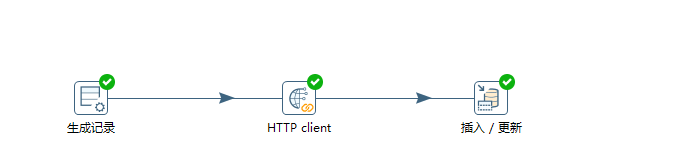
下面進行分級講解,首先新建轉換,然後建立資料庫連線,這些我就不詳細貼圖講解了,不懂者可以去看我前面關於kettl的部落格。然後新建生成記錄的輸入,生成記錄的詳情如下圖

其中的url就是前面檢視得到的url請求,station就是後面拿來做where條件匹配所用。
然後新建一個Http Client的查詢,詳情如下

然後新建一個插入更新的輸出,首先資料插入表,詳情如下

如果以上步驟全部正確,點選執行即可得到資料,資料庫表資料如下
![]()
以上就把網頁中的資料抓取到自己的資料庫中了。
相關推薦
kettle抓取網頁上的資料儲存到資料表中
今天做一個利用kettle抓取網頁資料儲存到資料表中的demo,如抓取AA市的空氣質量AQI 1.檢視網頁資訊 2.按下開發者工具,檢視虎丘空氣質量日報的請求 3.弄懂了網頁請求,並通過檢視資料格式,可以在資料庫中建表,表格如下 4.接下來就是在kettle中進行操
Fiddler抓取手機上的網路資料包
配置步驟: Fiddler關於上圖1,2配置 Fiddler-Tools-Options-HTTPS Fiddler-Tools-Options-CONNECTIONS 模擬
利用正則表示式抓取網頁上郵箱的小程式
使用方法:把自己在網上儲存下來含有郵箱的網頁所在硬碟的路徑,拷到對應位置即可,此程式用eclipse-luna-64位測試已通過 程式最終來源為馬上兵老師釋出的視訊及原始碼,本人是用來學習,並和大家分享 視訊連結:http://pan.baidu.com/s/1jIE5qC
C# 正則表示式抓取網頁上某個標籤的內容,並替換連結地址和圖片地址
#region 獲取第三方網站內容 //獲取其他網站網頁內容的關鍵程式碼 WebRequest request = WebRequest.Create(第三方的網站地址); WebResponse response = requ
Python爬蟲學習,抓取網頁上的天氣資訊
今天學習了使用python編寫爬蟲程式,從中國天氣網爬取杭州的天氣。使用到了urllib庫和bs4。bs4提供了專門針對html的解析功能,比用RE方便許多。 # coding : UTF-8 import sys reload(sys) sys.setdef
Python爬蟲 BeautifulSoup抓取網頁資料 並儲存到資料庫MySQL
最近剛學習Python,做了個簡單的爬蟲,作為一個簡單的demo希望幫助和我一樣的初學者 程式碼使用python2.7做的爬蟲 抓取51job上面的職位名,公司名,薪資,釋出時間等等 直接上程式碼,程式碼中註釋還算比較清楚 ,沒有安裝mysql需要遮蔽掉相關程式碼:#!/u
php抓取網頁內容,獲取網頁資料
php通過simple_html_dom實現抓取網頁內容,獲取核心網頁資料,將網頁資料寫入本地 xxx.json 檔案 其程式碼實現邏輯: 1. 引入simple_html_dom.php檔案 require_once 'simple_ht
有搜尋條件根據url抓取網頁資料(java爬取網頁資料)
最近有一個任務抓取如下圖的網頁資料 要獲取前一天的資料進行翻頁抓取資料並存入資料庫 如果就只是抓取當前頁的資料 沒有條件和翻頁資料 這個就比較簡單了 但是要選取前一天的資料,還有分頁資料 一開始的思路就想錯了(開始想的是觸發查詢按鈕和
python抓取網頁資料處理後視覺化
抓取文章的連結,訪問量儲存到本地 1 #coding=utf-8 2 import requests as req 3 import re 4 import urllib 5 from bs4 import BeautifulSoup 6 import sys 7 import code
c# 抓取網頁驗證碼並post資料
如果想開發半自動的註冊機程式,那麼把驗證碼讀取到winform裡面,然後提交資料是必須的流程,這篇博文記錄一下如何抓取網頁上面的驗證碼,注意不是驗證碼識別。有的網站會驗證Cookie,有的不會,本文包含Cookie讀取提交。 首先生命一個全域性的Cookie變數 priva
Python抓取網頁動態資料——selenium webdriver的使用
文章目的 當我們使用Python爬取網頁資料時,往往用的是urllib模組,通過呼叫urllib模組的urlopen(url)方法返回網頁物件,並使用read()方法獲得url的html內容,然後使用BeautifulSoup抓取某個標籤內容,結合正則表示式過濾。但是,用u
Python抓取網頁資料的終極辦法
假設你在網上搜索某個專案所需的原始資料,但壞訊息是資料存在於網頁中,並且沒有可用於獲取原始資料的API。 所以現在你必須浪費30分鐘寫指令碼來獲取資料(最後花費 2小時)。 這不難但是很浪費時間。 Pandas庫有一種內建的方法,可以從名為re
python的BeautifulSoup實現抓取網頁資料
1環境:pycharm,python3.4 2.原始碼解析 import requests import re from bs4 import BeautifulSoup #通過requests.get獲取整個網頁的資料 def getHtmlText(url):
Java抓取網頁資料(原網頁+Javascript返回資料)
轉載請註明出處! 有時候由於種種原因,我們需要採集某個網站的資料,但由於不同網站對資料的顯示方式略有不同! 本文就用Java給大家演示如何抓取網站的資料:(1)抓取原網頁資料;(2)抓取網頁Jav
抓取網頁資料 A標籤的HREF 值
在工作中,我們有時候需要從特定的網頁中抓取我們想要的資料,由於工作的需要,我給大家推薦一個專門的抓取類:Winista.HtmlParser.dll 當我們需要從有規律的網頁中提取資料時,如table tr td; ul li之類的,如果用正則表示式,或者做字串的處理,會非常
如何抓取網頁中的實時監測資料進行分析
使用wpf做了窗體,跟Silverlight開發環境一樣,將前臺設計與後臺開發邏輯分離開來,抓取南京市九個PM 2.5監測站點的資料 前臺程式碼: <Grid> <Button Content="資料獲取" Heigh
node.js 小爬蟲抓取網頁資料(2)
node.js 小爬蟲抓取網頁資料 在原來的基礎上,採用了promise的模組,使其可以一次性多頁面的爬取網頁資料。 var http = require('http') var Promise = require('promise') var cheerio = re
抓取網頁資料並解析Android
這天遇到這樣一個需求:這種頁面資料可以抓取嗎? 隨後提供了賬號、密碼和網站地址: 帳號:kytj1 密碼:****************** 登陸地址:http://student.tiaoji.kaoyan.com/tjadm 主要思路: 1、使用F
goLang 多執行緒抓取網頁資料
突然有個想法想用goLang快速的抓取網頁資料,於是想到了 多執行緒進行頁面抓取 package main import ( "fmt" "log" "net/http" "os" "st
【php網頁爬蟲】php抓取網頁資料
外掛介紹: PHP Simple HTML DOM解析類:Simple HTML DOM parser 幫我們很好地解決了使用 php html 解析 問題。可以通過這個php類來解析html文件,對其中的html元素進行操作 (PHP5+以上版本)。 使用方法: 1