
企業資料爬蟲專案
阿新 • • 發佈:2018-11-09
企業資料爬蟲專案(豔輝VIP專案)
第一天:下載解析網站頁面
以爬取某電影網上的電影資訊為例,通過xpath,regex獲取網頁上的欄位。通過三大sevice,下載網頁service,解析網頁service和資料儲存service,全面爬取網站上的資訊。
爬蟲開始——>下載網頁——>解析網頁——>存數資料
三步走,分成三大service,例如存數資料,可以用jdbcService,也可以用hbaseService,這樣方便擴充套件業務。
/** * 開啟一個爬蟲入口 */ public void startSpider(){ while(true){ //從佇列中提取需要解析的url String url = urlQueue.poll(); //判斷url是否為空 if(StringUtils.isNotBlank(url)){ //下載 Page page = this.downloadPage(url); //解析 this.processPage(page); List<String> urlList = page.getUrlList(); for(String eachurl : urlList){ this.urlQueue.add(eachurl); } //if(page.getUrl().startsWith("http://list.youku.com/show_page")){ //儲存資料 this.storePageInfo(page); //} }else{ System.out.println("url解析完畢!"); } try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } }
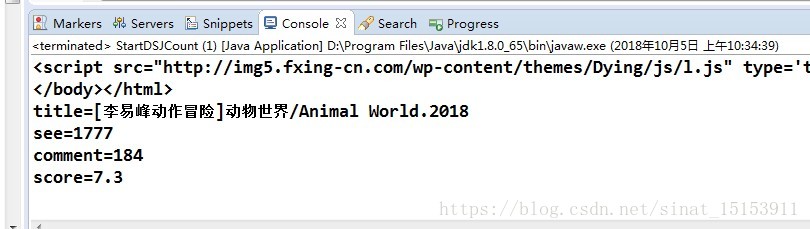
先爬取電影的標題,電影訪問的次數,評論的人數,電影豆瓣的評分等資訊。
String seeNum = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("seeXpath"), LoadPropertyUtil.getYOUKU("seeRegex")); page.setSeeNum(seeNum); // 獲取評論數 String commentNum = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("commentXpath"), LoadPropertyUtil.getYOUKU("commentRegex")); page.setCommentNum(commentNum); // 獲取豆瓣評分 String score = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("scoreXpath"), LoadPropertyUtil.getYOUKU("scoreRegex")); page.setScore(score); String title = HtmlUtil.getFieldByRegex2(rootNode, LoadPropertyUtil.getYOUKU("titleXpath"), LoadPropertyUtil.getYOUKU("titleRegex")); page.setTitle(title);
需要下載原始碼可點選 豔學網
下載原始碼後,記住分享喲!
第一步:微信關注公眾號豔學網!
第二步:關注後開啟選單“豔輝福利”——“java福利”,轉發文章至朋友圈。
長按自動識別二維碼,即可關注微信公眾號“豔學網”
