筆記︱風控分類模型種類(決策、排序)比較與模型評估體系(ROC/gini/KS/lift)
轉載自素質雲部落格。本筆記源於CDA-DSC課程,由常國珍老師主講。該訓練營第一期為風控主題,培訓內容十分緊湊,非常好,推薦:CDA資料科學家訓練營
——————————————————————————————————————————
一、風控建模流程以及分類模型建設
1、建模流程
該圖源自課程講義。主要將建模過程分為了五類。資料準備、變數粗篩、變數清洗、變數細篩、建模與實施。

2、分類模型種類與區別
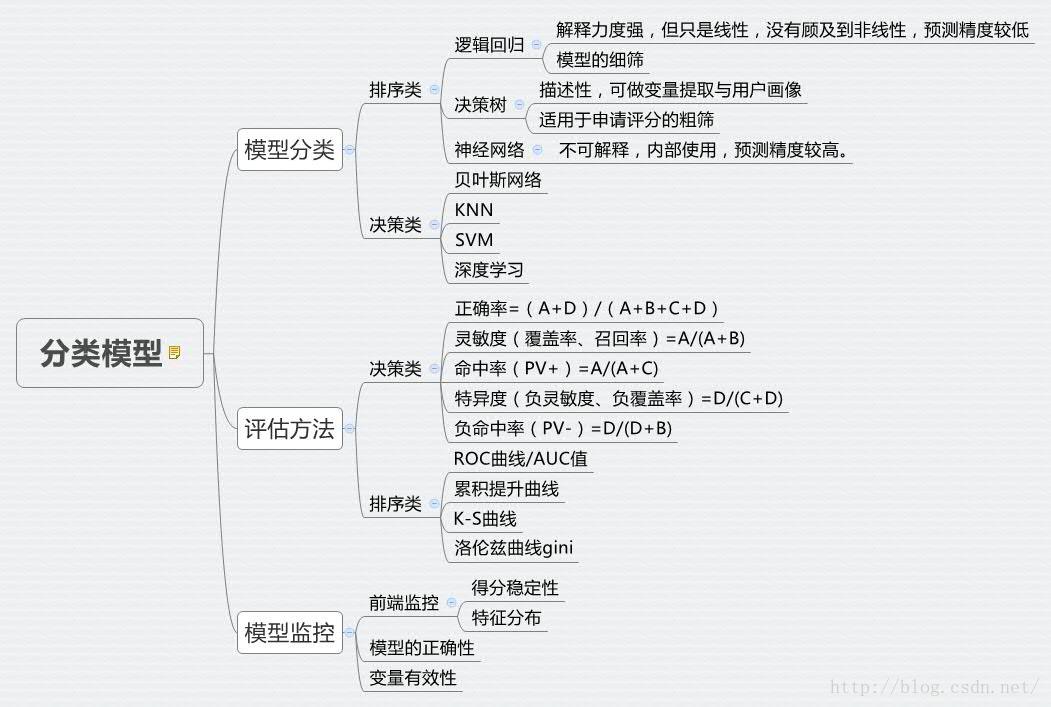
風控與其他領域一樣,分類模型主要分為兩大類:排序類、決策類、標註類(文字、自然語言處理)。
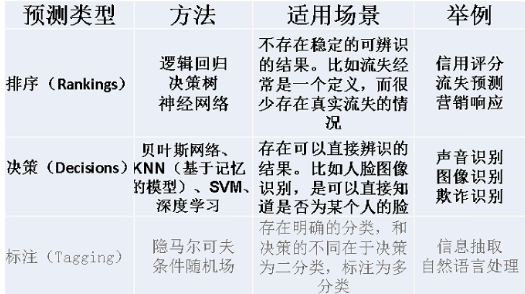
一般來說風控領域在意的是前兩個模型種類,排序類以及決策類。
其中:巴塞爾協議定義了金融風險型別:市場風險、作業風險、信用風險。信用風險ABC模型有進件申請評分、行為評分、催收評分。
| 模型 | 解釋 | 複雜度 | 應用場景 |
| Logistics迴歸 | 影響程度大小與顯著性,解釋力度強,但只是線性,沒有顧及到非線性,預測精度較低 | |
申請評分、流失預測 |
| 決策樹 |
1、描述性,重建使用者場景,可做變數提取與使用者畫像 | 葉子的數量 | 流失模式識別 |
| 2、樹的結構不穩定,可以得出變數重要性,可以作為變數篩選 | |||
| 隨機森林 | 隨機森林比決策樹在變數篩選中,變數排序比較優秀 | |
|
| 神經網路 | 1、不可解釋,內部使用,預測精度較高。可以作為初始模型的金模型(用以評估在給定資料條件下,邏輯迴歸可達到的最精確程度) 2、線性(邏輯迴歸)+非線性關係,可用於行為評分的預測模型(行為評分對模型可解釋性不強),可用於申請評分的金模型 3、使用場景:先做一個神經網路,讓預測精度(AUC)達到最大時,再用邏輯迴歸 |
迭代次數 | 申請評分的金模型; 行為評分的預測模型 |
(1)信用風險——申請信用評分
申請評分可以將神經網路+邏輯迴歸聯合使用。
《公平信用報告法》制約,強調評分卡的可解釋性。所以初始評分(申請評分)一般用迴歸,迴歸是解釋力度最大的。
神經網路可用於銀行行為評級以及不受該法制約監管的業務(P2P)。其次,神經也可以作為申請信用評分的金模型。
金模型的使用:一般會先做一個神經網路,讓預測精度(AUC)達到最大時,再用邏輯迴歸。
建模大致流程:
一批訓練集+測試集+一批欄位——神經網路建模看AUC——如果額定的AUC在85%,沒超過則返回重新篩選訓練、測試集以及欄位;
超過則,可以後續做邏輯迴歸。
(2)信用風險——行為評分
行為評分建模:行為信用評級不需要解釋性,所以可以用非線性的神經網路。
——————————————————————————————————————————
二、分類模型評估體系
上述將分類模型做了歸納,不同的分類模型所採用的評估體系不同。
決策類:準確率/誤分率、利潤/成本
排序類:ROC指標(一致性)、Gini指數、KS統計量、提升度
1、決策類評估——混淆矩陣指標
混淆矩陣,如圖:其中這些指標名稱在不同行業有不同的名稱解釋
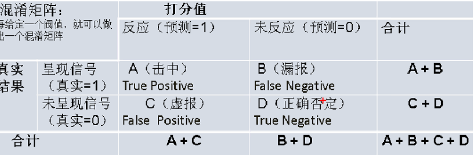
正確率=(A+D)/(A+B+C+D)
靈敏度(覆蓋率、召回率)=A/(A+B)
命中率(PV+)=A/(A+C)
特異度(負靈敏度、負覆蓋率)=D/(C+D)
負命中率(PV-)=D/(D+B)
在以上幾個指標中不同行業看中不同的指標:
(1)靈敏度/召回率/覆蓋率(——相對於命中率)
譬如靈敏度(召回率)這一指標就比正確率要重要,覆蓋率(Recall)這個詞比較直觀,在資料探勘領域常用。因為感興趣的是正例(positive),比如在信用卡欺詐建模中,我們感興趣的是有高欺詐傾向的客戶,那麼我們最高興看到的就是,用模型正確預測出來的欺詐客戶(True Positive)cover到了大多數的實際上的欺詐客戶,覆蓋率,自然就是一個非常重要的指標。
(2)命中率(——相對於覆蓋率)
欺詐分析中,命中率(不低於20%),看模型預測識別的能力。
在資料庫營銷裡,你預測到b+d個客戶是正例,就給他們郵寄傳單發郵件,但只有其中d個會給你反饋(這d個客戶才是真正會響應的正例),這樣,命中率就是一個非常有價值的指標。 以後提到這個概念,就表示為PV+(命中率,Positive Predicted Value)*。
2、排序類指標評估
ROC指標(一致性)、Gini指數(洛倫茲曲線)、KS統計量、提升度四類指標。
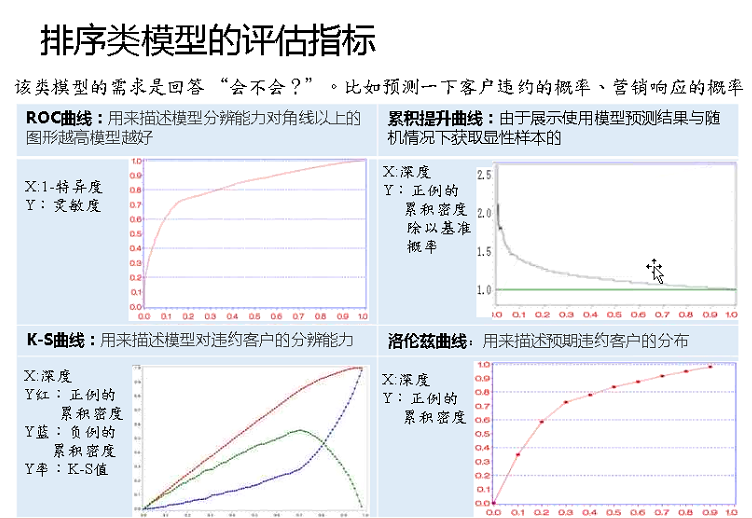
(1)ROC曲線
對角線模型,最差,風控喜歡的指標。由決策類指標的靈敏度(召回率/覆蓋率)與特異度(負靈敏度、負召回率)來構造。
求覆蓋率等指標,需要指定一個閾值(threshold)。隨著閾值的減小,靈敏度和1-特異度也相應增加(也即特異度相應減少)。
把基於不同的閾值而產生的一系列靈敏度和特異度描繪到直角座標上,就能更清楚地看到它們的對應關係。把sensitivity和1-Specificity描繪到同一個圖中,它們的對應關係,就是傳說中的ROC曲線,全稱是receiver operating characteristic curve,中文叫“接受者操作特性曲線”。
AUC值,為了更好的衡量ROC所表達結果的好壞,Area Under Curve(AUC)被提了出來,簡單來說就是曲線右下角部分佔正方形格子的面積比例。該比例代表著分類器預測精度。(R語言︱ROC曲線——分類器的效能表現評價)
(2)累積提升曲線
營銷最好的圖,很簡單。它衡量的是,與不利用模型相比,模型的預測能力“變好”了多少(分類模型評估——混淆矩陣、ROC、Lift等)。
將概率從大到小鋪開x,提升度可以有一些“忽悠”的成本,哈哈~可以微調,可以自己調節提升度的區間
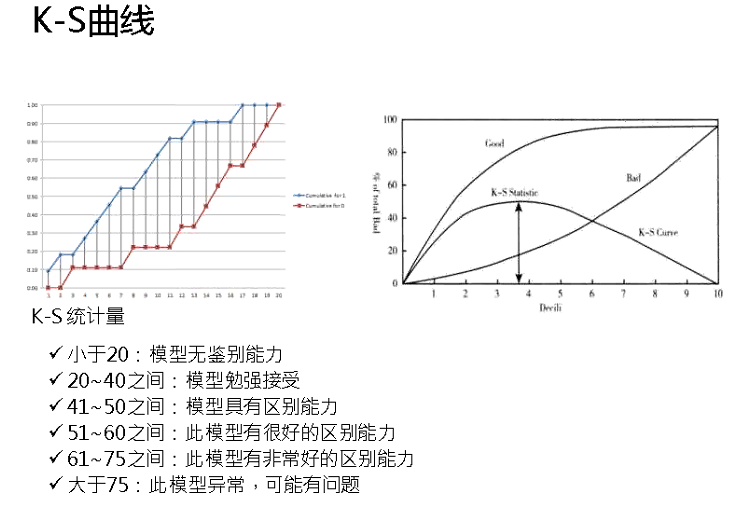
(3)K-S曲線
風控喜歡的指標。K-S曲線的最大值代表K-S統計量。
(4)洛倫茲曲線gini
風控喜歡的指標,TP率給了一個累積比,跟提升度差不多。
——————————————————————————————————————————
三、信用風險模型檢測
監測可以分為前端、後端監控。
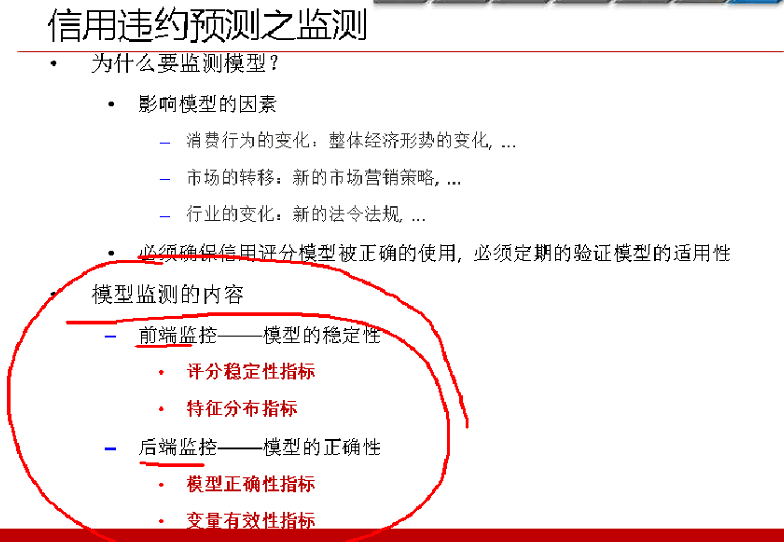
前端監控,授信之前,別的客戶來了,這個模型能不能用?
後端監控,建模授信之後,打了分數,看看一年之後,分數是否發生了改變。
1、前端監控
長期使用的模型,其中的變數一定不能波動性較大。比如,收入這個指標,雖然很重要,但是波動性很大,不適合用在長期建模過程中。
如果硬要把收入放到模型之中,要放入收入的百分位制(排名)。
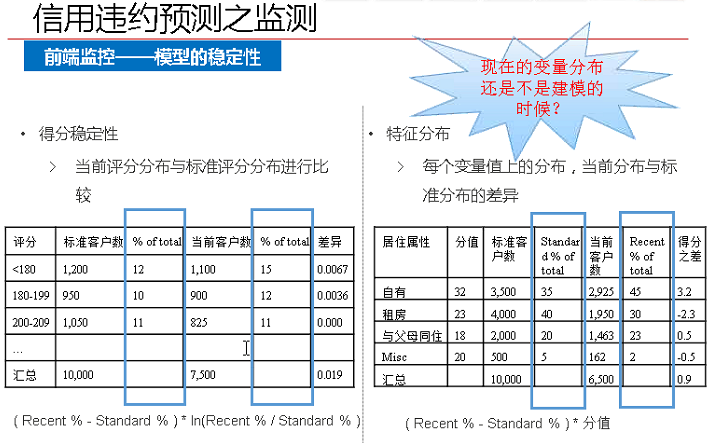
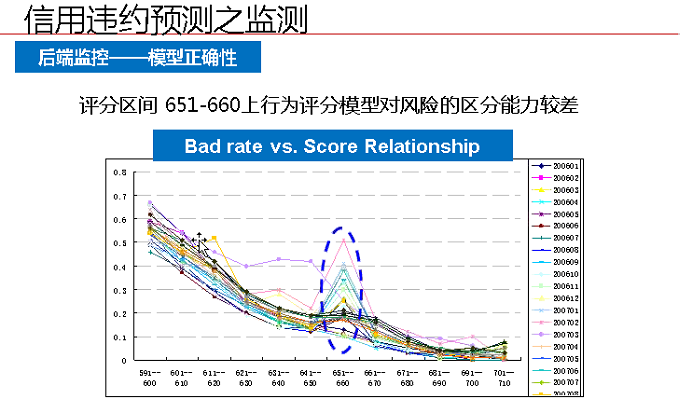
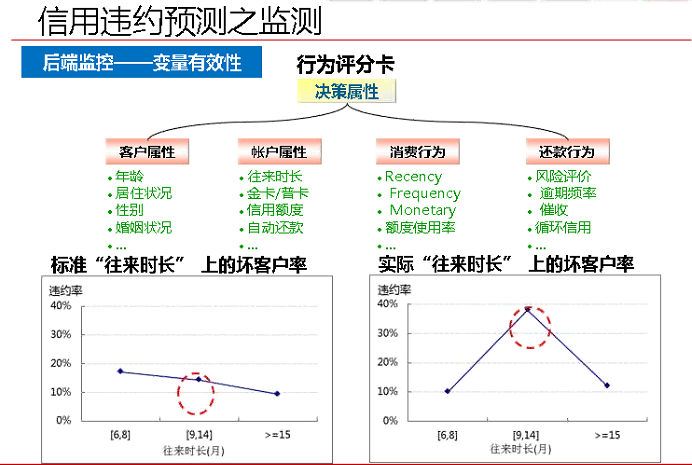
2、後端監控
主要監控模型的正確性以及變數選擇的有效性。出現了不平滑的問題,需要重新考慮