
一次 HashSet 所引起的並發問題
上午剛到公司,準備開始一天的摸魚之旅時突然收到了一封監控中心的郵件。
心中暗道不好,因為監控系統從來不會告訴我應用完美無 bug,其實系統挺猥瑣。
打開郵件一看,果然告知我有一個應用的線程池隊列達到閾值觸發了報警。
由於這個應用出問題非常影響用戶體驗;於是立馬讓運維保留現場 dump 線程和內存同時重啟應用,還好重啟之後恢復正常。於是開始著手排查問題。
分析
首先了解下這個應用大概是做什麽的。
簡單來說就是從 MQ 中取出數據然後丟到後面的業務線程池中做具體的業務處理。
而報警的隊列正好就是這個線程池的隊列。
跟蹤代碼發現構建線程池的方式如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(coreSize, maxSize, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());; put(poolName,executor);
采用的是默認的 LinkedBlockingQueue 並沒有指定大小(這也是個坑),於是這個隊列的默認大小為 Integer.MAX_VALUE。
由於應用已經重啟,只能從僅存的線程快照和內存快照進行分析。
內存分析
先利用 MAT 分析了內存,的到了如下報告。
一次 HashSet 所引起的並發問題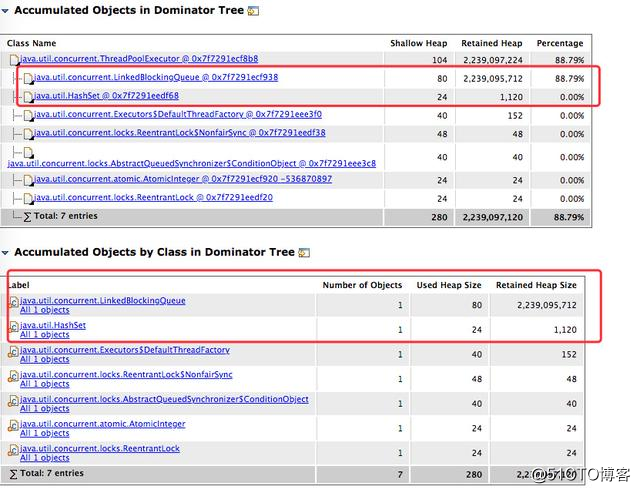
其中有兩個比較大的對象,一個就是之前線程池存放任務的 LinkedBlockingQueue,還有一個則是 HashSet。
當然其中隊列占用了大量的內存,所以優先查看,HashSet 一會兒再看。
由於隊列的大小給的夠大,所以結合目前的情況來看應當是線程池裏的任務處理較慢,導致隊列的任務越堆越多,至少這是目前可以得出的結論。
再來看看線程的分析,這裏利用 fastthread.io 這個網站進行線程分析。
因為從表現來看線程池裏的任務遲遲沒有執行完畢,所以主要看看它們在幹嘛。
正好他們都處於 RUNNABLE 狀態,同時堆棧如下:
發現正好就是在處理上文提到的 HashSet,看這個堆棧是在查詢 key 是否存在。通過查看 312 行的業務代碼確實也是如此。
這裏的線程名字也是個坑,讓我找了好久。
定位
分析了內存和線程的堆棧之後其實已經大概猜出一些問題了。
這裏其實有一個前提忘記講到:
這個告警是淩晨三點發出的郵件,但並沒有電話提醒之類的,所以大家都不知道。
到了早上上班時才發現並立即 dump 了上面的證據。
所有有一個很重要的事實:這幾個業務線程在查詢 HashSet 的時候運行了 6 7 個小時都沒有返回。
通過之前的監控曲線圖也可以看出: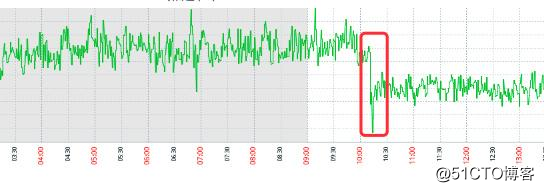
操作系統在之前一直處於高負載中,直到我們早上看到報警重啟之後才降低。
同時發現這個應用生產上運行的是 JDK1.7 ,所以我初步認為應該是在查詢 key 的時候進入了 HashMap 的環形鏈表導致 CPU 高負載同時也進入了死循環。
為了驗證這個問題再次 review 了代碼。
整理之後的偽代碼如下:
//線程池
private ExecutorService executor;
private Set<String> set = new hashSet();
private void execute(){
while(true){
//從 MQ 中獲取數據
String key = subMQ();
executor.excute(new Worker(key)) ;
}
}
public class Worker extends Thread{
private String key ;
public Worker(String key){
this.key = key;}
@Override
br/>}
@Override
if(!set.contains(key)){
//數據庫查詢
if(queryDB(key)){
set.add(key);
return;
}
}
//達到某種條件時清空 set
if(flag){
set = null ;
}
}
}
大致的流程如下:
源源不斷的從 MQ 中獲取數據。
將數據丟到業務線程池中。
判斷數據是否已經寫入了 Set。
沒有則查詢數據庫。
之後寫入到 Set 中。
這裏有一個很明顯的問題,那就是作為共享資源的 Set 並沒有做任何的同步處理。
這裏會有多個線程並發的操作,由於 HashSet 其實本質上就是 HashMap,所以它肯定是線程不安全的,所以會出現兩個問題:
Set 中的數據在並發寫入時被覆蓋導致數據不準確。
會在擴容的時候形成環形鏈表。
第一個問題相對於第二個還能接受。
通過上文的內存分析我們已經知道這個 set 中的數據已經不少了。同時由於初始化時並沒有指定大小,僅僅只是默認值,所以在大量的並發寫入時候會導致頻繁的擴容,而在 1.7 的條件下又可能會形成環形鏈表。
不巧的是代碼中也有查詢操作(contains()),觀察上文的堆棧情況:
發現是運行在 HashMap 的 465 行,來看看 1.7 中那裏具體在做什麽: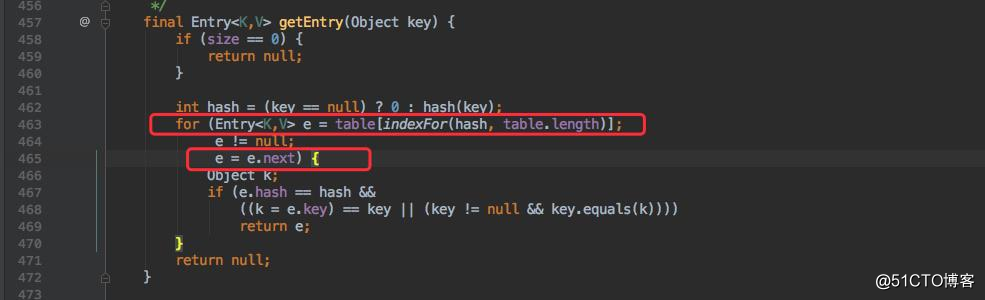
已經很明顯了。這裏在遍歷鏈表,同時由於形成了環形鏈表導致這個 e.next 永遠不為空,所以這個循環也不會退出了。
到這裏其實已經找到問題了,但還有一個疑問是為什麽線程池裏的任務隊列會越堆越多。我第一直覺是任務執行太慢導致的。
仔細查看了代碼發現只有一個地方可能會慢:也就是有一個數據庫的查詢。
把這個 SQL 拿到生產環境執行發現確實不快,查看索引發現都有命中。
但我一看表中的數據發現已經快有 7000W 的數據了。同時經過運維得知 MySQL 那臺服務器的 IO 壓力也比較大。
所以這個原因也比較明顯了:
由於每消費一條數據都要去查詢一次數據庫,MySQL 本身壓力就比較大,加上數據量也很高所以導致這個 IO 響應較慢,導致整個任務處理的就比較慢了。
但還有一個原因也不能忽視;由於所有的業務線程在某個時間點都進入了死循環,根本沒有執行完任務的機會,而後面的數據還在源源不斷的進入,所以這個隊列只會越堆越多!
這其實是一個老應用了,可能會有人問為什麽之前沒出現問題。
這是因為之前數據量都比較少,即使是並發寫入也沒有出現並發擴容形成環形鏈表的情況。這段時間業務量的暴增正好把這個隱藏的雷給揪出來了。所以還是得信墨菲他老人家的話。
總結
至此整個排查結束,而我們後續的調整措施大概如下:
HashSet 不是線程安全的,換為 ConcurrentHashMap同時把 value 寫死一樣可以達到 set 的效果。
根據我們後面的監控,初始化 ConcurrentHashMap 的大小盡量大一些,避免頻繁的擴容。
MySQL 中很多數據都已經不用了,進行冷熱處理。盡量降低單表數據量。同時後期考慮分表。
查數據那裏調整為查緩存,提高查詢效率。
線程池的名稱一定得取的有意義,不然是自己給自己增加難度。
根據監控將線程池的隊列大小調整為一個具體值,並且要有拒絕策略。
升級到 JDK1.8。
再一個是報警郵件酌情考慮為電話通知。
HashMap 的死循環問題在網上層出不窮,沒想到還真被我遇到了。現在要滿足這個條件還是挺少見的,比如 1.8 以下的 JDK 這一條可能大多數人就碰不到,正好又證實了一次墨菲定律。
一次 HashSet 所引起的並發問題