
JAVA實現圖的廣度優先遍歷
阿新 • • 發佈:2018-11-09
一:廣度優先遍歷介紹.
廣度優先遍歷(BFS),廣度優先遍歷是儘可能的更多的把相鄰的元素都遍歷了,然後在訪問外層的,有點像中心開花由內到外.
從圖中任選一個頂點v,作為起始頂點.例如下圖:BFS的遍歷順序是首先是V,然後是W1,W2,Y11,Y12,Y21,Y22.總是第一層訪問完了,才訪問第二層的,這就是二叉樹的層序訪問嘛.
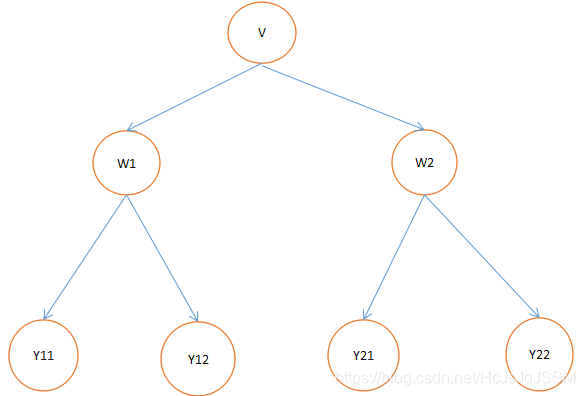
二:廣度優先遍歷的實現.使用佇列實現.

BFS的遍歷序列如下:沒有確定起始點就不唯一.這裡是A是起點.
import java.util.LinkedList; import java.util.Queue; /** * title: com.lx.algorithm.graph * @author: lixing * date: 2018/10/31 17:57 * description:廣度優先遍歷使用佇列實現,(無向非連通圖)非遞迴實現. */ public class BFSTest { /** * 儲存節點資訊 */ private char[] vertices; /** * 儲存邊資訊(鄰接矩陣) */ private int[][] arcs; /** * 圖的節點數 */ private int vexnum; /** * 記錄節點是否已被遍歷 */ private boolean[] visited; /** * 初始化 */ public BFSTest(int n) { vexnum = n; vertices = new char[n]; arcs = new int[n][n]; visited = new boolean[n]; for (int i = 0; i < vexnum; i++) { for (int j = 0; j < vexnum; j++) { arcs[i][j] = 0; } } } /** * 新增邊 */ public void addEdge(int i, int j) { if (i == j) { return; } arcs[i][j] = 1; arcs[j][i] = 1; } /** * 設定節點集 */ public void setVertices(char[] vertices) { this.vertices = vertices; } /** * 設定節點訪問標記 */ public void setVisited(boolean[] visited) { this.visited = visited; } /** * 列印遍歷節點 */ public void visit(int i) { System.out.print(vertices[i] + " "); } /** * 輸出鄰接矩陣 */ public void pritf(int[][] arcs){ for(int i=0;i<arcs.length;i++){ for(int j=0;j<arcs[0].length;j++){ System.out.print(arcs[i][j]+ "\t"); } System.out.println(); } } /** * 實現廣度優先遍歷 */ public void bfs() { // 初始化所有的節點的訪問標誌 for (int v = 0; v < visited.length; v++) { visited[v] = false; } Queue<Integer> queue = new LinkedList<Integer>(); for (int i = 0; i < vexnum; i++) { if (visited[i] == false) { visited[i] = true; // 列印當前已經遍歷的節點 visit(i); // 新增到佇列裡面 queue.add(i); // 只要佇列不為空 while (!queue.isEmpty()) { // 出隊節點,也就是這一層的節點. int k = queue.poll(); // 遍歷所有未被訪問的鄰接節點,放入佇列 for (int j = 0; j < vexnum; j++) { // 也就是訪問這一層剩下的未被訪問的節點 if (arcs[k][j] == 1 && visited[j] == false) { visited[j] = true; visit(j); queue.add(j); } } } } } System.out.println(); pritf(arcs); } public static void main(String[] args) { BFSTest g = new BFSTest(9); char[] vertices = {'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'}; // 設定頂點集 g.setVertices(vertices); // 新增邊 g.addEdge(0, 1); g.addEdge(0, 5); g.addEdge(1, 0); g.addEdge(1, 2); g.addEdge(1, 6); g.addEdge(1, 8); g.addEdge(2, 1); g.addEdge(2, 3); g.addEdge(2, 8); g.addEdge(3, 2); g.addEdge(3, 4); g.addEdge(3, 6); g.addEdge(3, 7); g.addEdge(3, 8); g.addEdge(4, 3); g.addEdge(4, 5); g.addEdge(4, 7); g.addEdge(5, 0); g.addEdge(5, 4); g.addEdge(5, 6); g.addEdge(6, 1); g.addEdge(6, 3); g.addEdge(6, 5); g.addEdge(6, 7); g.addEdge(7, 3); g.addEdge(7, 4); g.addEdge(7, 6); g.addEdge(8, 1); g.addEdge(8, 2); g.addEdge(8, 3); System.out.print("廣度優先遍歷(佇列):"); g.bfs(); } }
執行結果:

三:深度優先對比廣度優先遍歷.
1. 兩種演算法的時間複雜度都是一樣的.
2. 深度優先遍歷涉及的輔助資料結構是棧,廣度優先遍歷涉及的佇列.
3. 廣度優先遍歷佔用的記憶體比較多是橫向元素入隊的,如果這一層元素比較多,那麼隊內的元素就比較多,而深度優先遍歷的棧內元素是深入棧的,每一條路徑不會儲存太對的元素,棧內元素依次出棧,佔用記憶體減少.