
簡單瞭解,使用oracle中的索引,表分割槽
索引的分類
如下:
| 物理分類 | 邏輯分類 |
| 分割槽或非分割槽索引 | 單列或組合索引 |
| B樹索引(標準索引) | 唯一或非唯一索引 |
| 正常或反向鍵索引 | 基於函式索引 |
| 點陣圖索引 |
B樹索引
b樹索引通常也稱為標準索引,索引的頂部為根,其中包含指向索引中下一級的項,下一級為分支塊,分支塊又指向索引中下一級的塊.最低階為葉節點
,其中包含指向錶行的索引項.葉塊為雙向連結,有助於按關鍵字值的升序和降序掃描索引
要深入瞭解B樹索引可以去這裡:
建立普通索引的語法如下
CREATE [UNIQUE] INDEX inde_name ON table_name(column_list)
[tablespace. _name];
在語法中
- UNIQUE:用於指定唯一索引, 預設情況下為非唯一索引。
- index_ name : 指所建立索引的名稱。
- table_ name:表示為之建立索引的表名。
- column list:在其上建立索引的列名的列表,可以基於多列建立索引
- tablespace. _name;為索引指定表空間。2.唯一索引和非唯一索引
- 唯一索引:定義索引的列中任何兩行都沒有重複值。唯一索引中的索引關鍵字只能指向表中的一行。在建立主鍵約束和建立唯一約束時都會建立一個與之對應的唯一索引。
- 非唯一索引: 單個關鍵字可以有多個與其關聯的行。
在薪水級別(salgrade) 表中,為級別編號(grade) 列建立唯一索引, 程式碼如下。
CREATE INDEX idx_emp_department ON emp(deptno);
反向鍵索引
與常規B樹索引相反,反向鍵索引在保持列順序的同時反轉索引列的位元組。反向鍵索引通過反
分散在多專索引鍵的資料值來實現。其優點是對於連續增長的索引列,反轉索引列可以將索引資料力個索引塊間,減少1/0瓶頸的發生。
反向鍵索引通常建立在一些值連續增長的列上, 如系統生成的員工編號, 但不能執行範圍投。
反向索引程式碼如下
CREATE UNIQUE INDEX idx_empno ON emp(empno) REVERSE;
點陣圖索引
點陣圖索引的優點在於,它最適於低基數列(即該列的值是有限的,理論,上不會是無窮大)。例如,員工表中的工種(job) 列,即便是幾百萬
條員工記錄,工種也是可計算的。工種列可以作為點陣圖索31.類似的還有圖書表中的圖書類別列等。
| 值/行 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 產品經理 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 專案經理 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 程式設計師 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
原理如上 :有7條資料,和3種類型,滿足條件的就是1否則為0,如要查詢是否是專案經理時只需找出為1的即可
建立點陣圖SQL語句如下
CREATE BITMAP INDEX idx_emp_job ON emp(job);
點陣圖索引具有下列優點。
- 對於大批即時查詢,可以減少響應時間。
- 相比其他索引技術,佔用空間明顯減少。
- 即使在配置很低的終端硬體上.也能獲得顯著的效能。
點陣圖索引不應當用在頻繁發生INSERT UPDATE DLE操作的表上,這些DML操作在效能方面的代價很高。 點陣圖索引最適合於資料倉庫和決策支援系統。
其他索引
- 組合索引:在表內多列上建立。索引中的列不必與表中的列順序一致, 也不必相互鄰接,類似於SQL Server 中的複合索引,如員工表中部門和職務列上的索引。組合索引最多包含32列。
- 基於函式的索引:若使用的函式或表示式涉及正在建立索引的表中的一-列或多列,則建立基於函式的索引。可以將基於函式的索引建立為8樹或點陣圖索引。
--建立組合索引 CREATE INDEX idx_emp_name ON emp(last_name,first_name);
索引建立規則
建立索引時需遵循的原則如下:
- 頻繁搜尋的列可以作為索引。
- 經常排序、分組的列可作為索引。
- 經常用作連線的列(主鍵/外來鍵)可作為索引。
- 將索引放在一個單獨的表空間中.不要放在有回退段、臨時段和表的表空間中
- 對大型索引而言,考慮使用NOLOGGING子句建立大型索引。
- 根據業務資料發生的頻率,定期重新生成或重新組織索引,並進行碎片整理。
- 僅包含幾個不同值的列不可以建立為B樹索引,可根據需要建立點陣圖索引。
- 不要在僅包含幾行的表中建立索引。
刪除索引
--刪除索引 drop index idx_empno;
何時應刪除索引
- 應用程式不再需要索引。
- 執行批量載入前。大量載入資料前刪除索引.載入後再重建索引有以下好處,①提高加戰效能:②更有效地使用索引空間。
- 索引已損壞。
重建索引
--重建索引 把反向改為B樹索引 alter index idx_empno rebuild noreverse
何時應重建索引
- 使用者表被移動到新的表空間後,表上的索引不是自動轉移,此時需將索引移到指定表空間。
- ALTER INDEX index_ name REBUILD TABLESPACE tablespace name;
- 索引中包含很多已刪除的項。對錶進行頻繁刪除,造成索引空間浪費,可以重建索引。
- 需將現有的正常索引轉換成反向鍵索引。
所有的索引無非就是一個目的提高查詢效率,那麼oracle中如何來看呢

執行後選中查詢語句按下F5
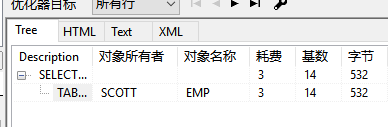
耗費消耗的越少效率越高
分割槽表
oracle可以把表中的資料分為幾個部分儲存在不同的位置,被分割槽的表叫做分割槽表
對於包含大量資料的表來說分割槽很有用,有以下優點
- 改善查詢效能,分割槽後SQL查詢時可以只訪問表中特定的區域
- 更容易管理,按分割槽載入和刪除比在表中更容易
- 便於備份和恢復,可以獨立備份和恢復每個分割槽
- 提高資料安全性,將不同的分割槽分佈在不同的磁碟,減小分割槽資料同時損壞的風險
oracle提供分割槽的方法有以下幾種
- 範圍分割槽
- 列表分割槽
- 雜湊分割槽
- 複合分割槽
- 間隔分割槽
- 虛擬分割槽
簡單瞭解下範圍和間隔分割槽
範圍分割槽
該分割槽以列的值範圍作為分區劃分的條件降級了存放到列值所在的範圍分割槽中.
/* =========================================================== || 建立範圍分割槽表 =========================================================== */ CREATE TABLE sales_range1 (sales_id NUMBER NOT NULL, product_id VARCHAR2(5), sales_date DATE, sales_cost NUMBER(10), areacode VARCHAR2(5) ) partition by range(sales_date) (partition part1 values less than (to_date('2011/01/01','yyyy/mm/dd')) TABLESPACE tp_orders, partition part2 values less than (to_date('2012/01/01','yyyy/mm/dd')), partition part3 values less than (to_date('2013/01/01','yyyy/mm/dd')), partition part4 values less than (to_date('2014/01/01','yyyy/mm/dd')) ); --查詢分割槽情況 SELECT table_name,partition_name FROM user_tab_partitions WHERE table_name=UPPER('sales_range1'); --插入資料 insert into sales_range1 values (1000,'p1',to_date('2011-01-01','yyyy-mm-dd'),1000,'A1'); --查詢資料 select * from sales_range1 PARTITION (part2);
間隔分割槽
該分割槽是範圍分割槽的一種增強功能,可以實現範圍分割槽的自動化,優點在於不需要建立表時就將所要分區劃分清楚.間隔分割槽隨著資料增長會劃分更多
分割槽,並自動建立新的分割槽
/* =========================================================== | 間隔分割槽表 ============================================================ */ CREATE TABLE sales_interval1 (sales_id NUMBER NOT NULL, product_id VARCHAR2(5), sales_date DATE, sales_cost NUMBER(10), areacode VARCHAR2(5) ) PARTITION BY RANGE(sales_date) INTERVAL(NUMTOYMINTERVAL(1,'YEAR')) (PARTITION part1 VALUES LESS THAN (to_date('2011/01/01','yyyy/mm/dd'))) --查詢分割槽情況 SELECT table_name,partition_name,tablespace_name FROM user_tab_partitions WHERE table_name=UPPER('sales_interval1'); INSERT INTO sales_interval1 VALUES (1000,'p1',SYSDATE,2000,'A2'); SELECT * FROM sales_interval1 PARTITION (SYS_P142); --現有表建立新表 CREATE TABLE sales_interval2 PARTITION BY RANGE(sales_date) INTERVAL(NUMTOYMINTERVAL(1,'YEAR')) (PARTITION part1 VALUES LESS THAN (to_date('2011/01/01','yyyy/mm/dd'))) AS SELECT * FROM sales;