
讀大型網站技術架構---第二篇---第四章---架構優化
阿新 • • 發佈:2018-11-10
此書第二章主要針對架構方面怎麼實現一些具體的優化手段,4.1節主要描述的是效能測試方面的,暫時不想去關注效能測試方面的知識。主要關注一下其他地方的優化手段。
4.2 Web前端效能優化
Web前端指網站業務邏輯之前的部分,包括瀏覽器載入,網站試圖模型,圖片服務,CND服務。
4.2.1. 瀏覽器訪問優化
- 減少http請求
HTTP協議是無狀態的應用層協議,意味著每次HTTP請求都需要建立通訊鏈路,進行資料傳輸,而在伺服器端都需要啟動獨立的執行緒去處理。
主要手段:合併CSS,合併JS,合併圖片。 - 使用瀏覽器快取
快取CSS,JS,Logo,圖片等靜態資源更新頻率不高,快取起來可以極大的改善的效能。 - 啟動壓縮
在伺服器對檔案進行壓縮,服務端進行壓縮,瀏覽器進行解壓,可以減少通訊傳輸的資料量,在伺服器資源不足的情況下進行權衡考慮。 - 減少Cookie傳輸
Cookie在每次請求和響應中,太大的Cookie會嚴重影響資料傳輸,減少Cookie中傳輸的資料量。另外對於靜態資源的訪問,沒有必要傳輸Cookie,因此需要考慮將靜態資源用獨立域名部署。
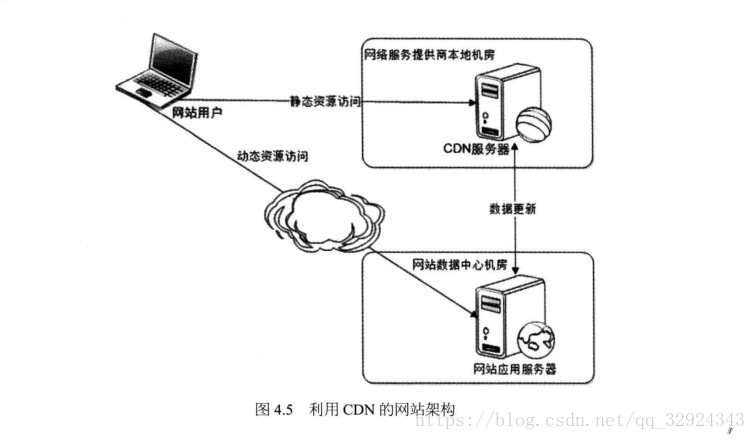
4.2.2. CDN加速
CDN手段主要減少資源訪問所經過的路徑,以最快的速度返回使用者所需的靜態資源。
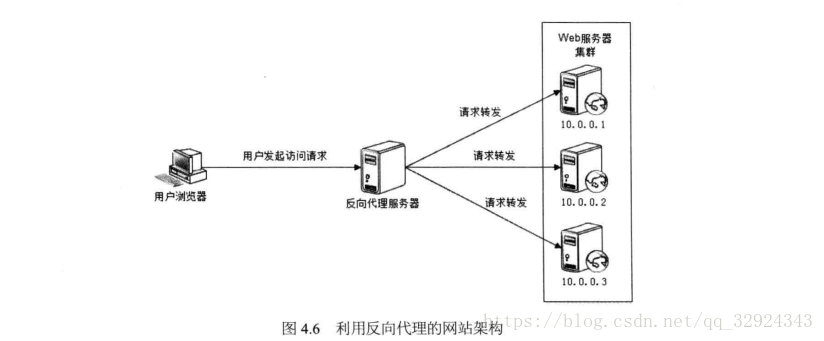
4.2.3. 反向代理
反向代理伺服器位於網站機房一側,代理網站Web伺服器接收Http請求,快取一些靜態內容,或者快取一些動態熱門內容,減輕後臺伺服器壓力。
4.3 應用伺服器效能優化
應用伺服器就是處理網站業務的伺服器,網站業務程式碼都不熟在這裡,優化主要手段有快取,叢集,非同步等。
4.3.1. 分散式快取
- 快取基本原理
Hash表,KV格式。不多做解釋。 - 合理使用快取
2.1 頻繁修改的資料:大致讀寫比例是2:1。
2.2 沒有熱點的訪問:遵循二八定律,即大部分資料訪問需要集中到小部分資料上。
2.3 資料不一致於髒讀:主要集中在資料失效時間和快取更新策略,需要根據場景來決定。
2.4 快取可用性:快取僅僅為了提高資料讀取效能的,快取資料丟失或者快取不可用不能影響應用程式的處理,不能因為快取雪崩之後導致資料庫宕機。
2.5 快取預熱:快取中存放的是熱點資料,熱點資料是快取系統利用LRU,最好是快取系統啟動時就把熱點資料載入好。
2.6 快取穿透:之前有做過這方面的研究學習,怎麼處理這種高併發的請求不存在的KV資料而導致請求壓力全部落到資料庫中。 - 分散式快取架構
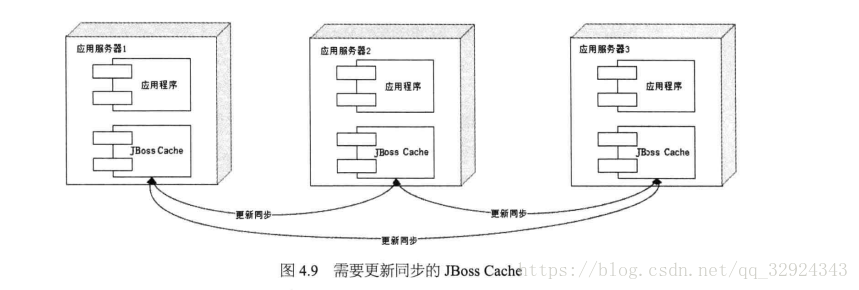
部署多個伺服器組成的叢集,主要分為兩種:以JBoss為代表的需要更新同步的分散式快取;另外一種就是Mencached為代表的不互相通訊的分散式快取。
受限的地方在於快取資料的數量受限於單一伺服器的記憶體空間,而且當叢集規模較大的時候,快取更新資訊需要同步到叢集所以機器,代價很大。因此大型網站很少採用這種方式。
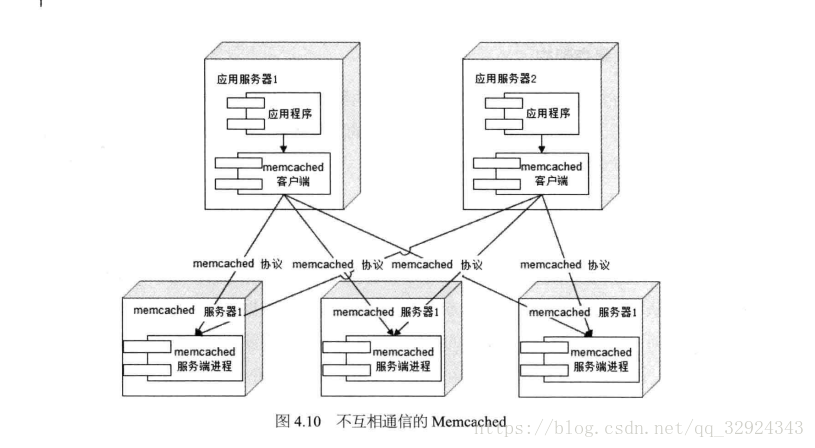
Memcached採用一種集中式的快取叢集管理。快取與應用分離部署,快取系統部署在一組專門的伺服器上,引用程式通過一致性Hash等路由演算法選擇快取伺服器遠端訪問快取資料,快取伺服器之間不通訊,叢集規模可以很容易實現擴容。
4.3.2. 非同步操作
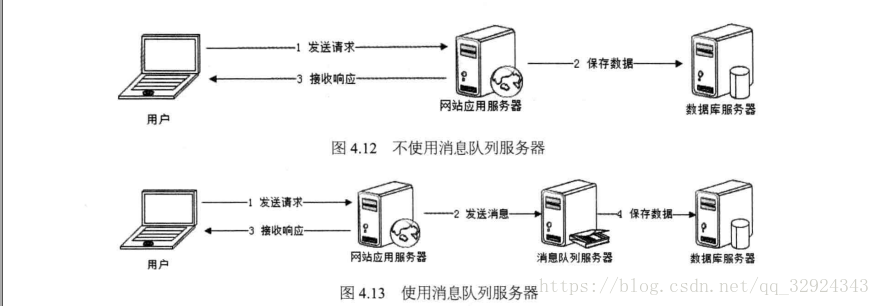
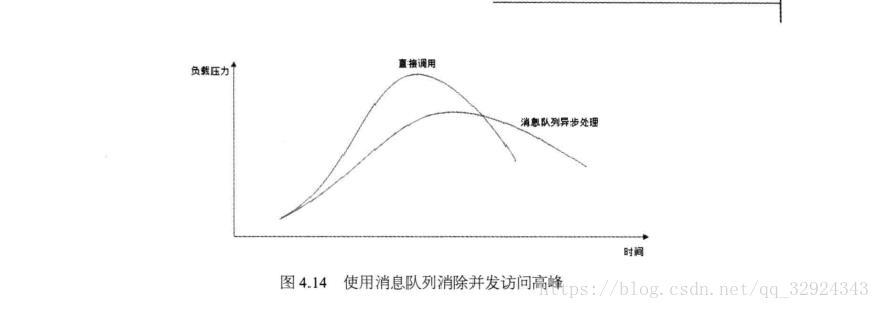
主要是可以將短時間高併發產生的事務訊息儲存在訊息佇列中,從而削平高峰期的併發事務。
典型的例如訂單系統,利用訊息佇列可以有效的減少訂單對系統的衝擊,如下圖:
訊息佇列在訂單系統中需要注意:資料寫入訊息佇列立即返回給使用者,資料在後續的業務校驗,寫資料等操作可能失敗,因此使用訊息佇列之後,需要修改業務流程進行配合,需要在訊息佇列的訂單消費者程序真正處理完該訂單,甚至商品出庫後,再去修改訂單狀態。
4.3.3. 使用叢集
略。
4.3.4. 程式碼優化
- 多執行緒
啟動執行緒數=[任務執行時間 / (任務執行時間- IO等待時間)] * CPU核心數。 - 資源複用
單例和物件池 - 資料結構
- 垃圾回收
主要針對的是JVM垃圾回收策略和垃圾回收演算法等等調優和選擇。
4.3.4. 程式碼優化
4.4 儲存效能優化
磁碟也是當前系統最嚴重的瓶頸。這邊不做過多的研究和學習。(不是當前學習的主要目的)。