
keras:3)Embedding層詳解
Embedding層
keras.layers.embeddings.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)嵌入層將正整數(下標)轉換為具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
Embedding層只能作為模型的第一層
引數
input_dim:大或等於0的整數,字典長度,即輸入資料最大下標+1
output_dim:大於0的整數,代表全連線嵌入的維度
embeddings_initializer: 嵌入矩陣的初始化方法,為預定義初始化方法名的字串,或用於初始化權重的初始化器。參考initializers
embeddings_regularizer: 嵌入矩陣的正則項,為Regularizer物件
embeddings_constraint: 嵌入矩陣的約束項,為Constraints物件
mask_zero:布林值,確定是否將輸入中的‘0’看作是應該被忽略的‘填充’(padding)值,該引數在使用遞迴層處理變長輸入時有用。設定為True的話,模型中後續的層必須都支援masking,否則會丟擲異常。如果該值為True,則下標0在字典中不可用,input_dim應設定為|vocabulary| + 2。
input_length:當輸入序列的長度固定時,該值為其長度。如果要在該層後接Flatten層,然後接Dense層,則必須指定該引數,否則Dense層的輸出維度無法自動推斷。
輸入shape
形如(samples,sequence_length)的2D張量
輸出shape
形如(samples, sequence_length, output_dim)的3D張量
較為費勁的就是第一句話:
嵌入層將正整數(下標)轉換為具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
哪到底咋轉啊,親?
這涉及到詞向量,具體看可以參考這篇文章:Word2vec 之 Skip-Gram 模型,下面只進行簡單的描述,
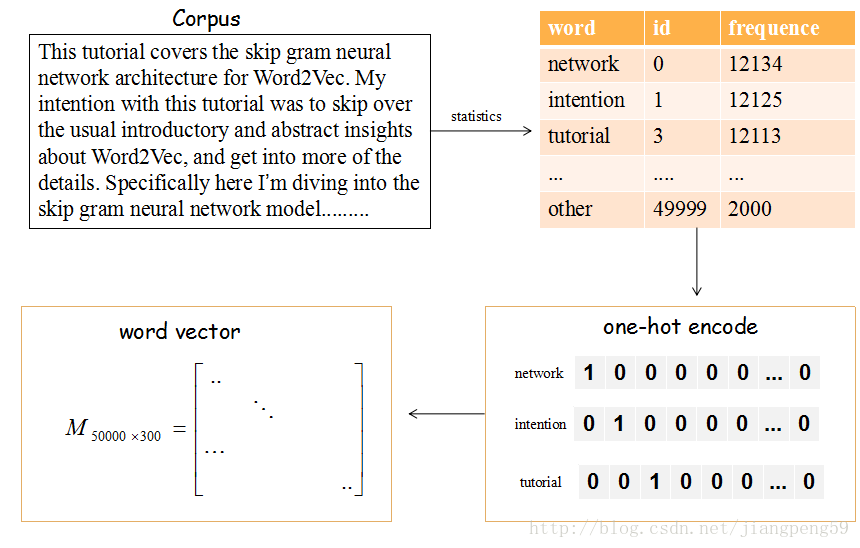
上圖的流程是把文章的單詞使用詞向量來表示。
(1)提取文章所有的單詞,把其按其出現的次數降許(這裡只取前50000個),比如單詞‘network’出現的次數最多,編號ID為0,依次類推…
(2)每個編號ID都可以使用50000維的二進位制(one-hot)表示
(3)最後,我們會生產一個矩陣M,行大小為詞的個數50000,列大小為詞向量的維度(通常取128或300),比如矩陣的第一行就是編號ID=0,即network對應的詞向量。
那這個矩陣M怎麼獲得呢?在Skip-Gram 模型中,我們會隨機初始化它,然後使用神經網路來訓練這個權重矩陣
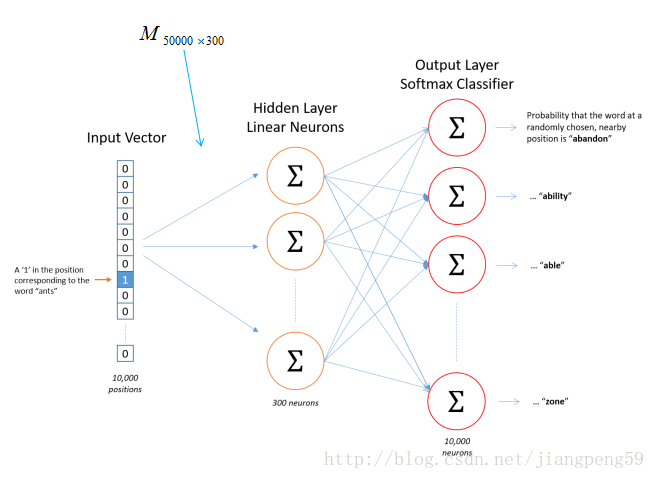
那我們的輸入資料和標籤是什麼?如下圖,輸入資料就是中間的哪個藍色的詞對應的one-hot編碼,標籤就是它附近詞的one-hot編碼(這裡windown_size=2,左右各取2個)
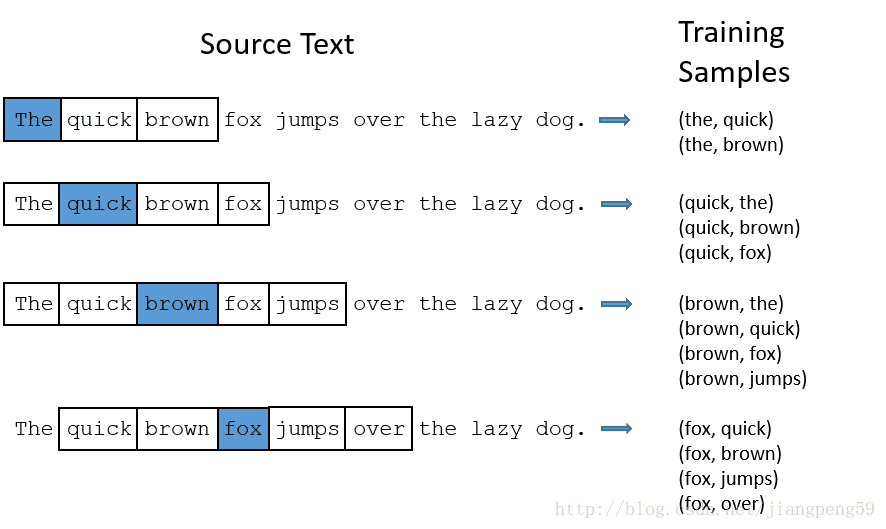
就上述的Word2Vec中的demo而言,它的單詞表大小為1000,詞向量的維度為300,所以Embedding的引數 input_dim=10000,output_dim=300
回到最初的問題:嵌入層將正整數(下標)轉換為具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
舉個栗子:假如單詞表的大小為1000,詞向量維度為2,經單詞頻數統計後,tom對應的id=4,而jerry對應的id=20,經上述的轉換後,我們會得到一個
如果輸入資料不需要詞的語義特徵語義,簡單使用Embedding層就可以得到一個對應的詞向量矩陣,但如果需要語義特徵,我們大可把以及訓練好的詞向量權重直接扔到Embedding層中即可,具體看參考keras提供的栗子:在Keras模型中使用預訓練的詞向量