python pandas高階進階
這是要匯入的模組

一、資料規整化 – 合併資料集
- pd.merge :連線dataframe的行,實現的是資料庫的連線操作
- concat: 沿一條軸將多個物件堆疊到一起
- combine_first:可以將重複資料編接在一起,用一個物件中的值填充另一個物件中的缺失值!
1.pd.merge合併資料集
(1)兩個有相同列名的dataframe
# 建立兩個dataframe
df1 = DataFrame(
{
'key':list('bbacaab'),
'data1':range(7)
} 
# merge 連線 採用的是‘inner'連線的方式,取交集部分,沒有交集的會捨棄掉
pd.merge(df1,df2)
# 預設情況下merge會將重複的列當作鍵來合併,建議使用on 來指定以什麼來合併
pd.merge(df1,df2,on='key')
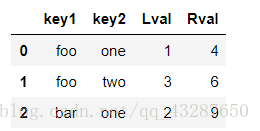
(2)兩個無相同列名的dataframe進行合併


# 進行合併,以不同的列
pd.merge(df3,df4,left_on='Lkey',right_on='Rkey')
3.pd.merge引數 how = outer 作為合併引數取並集
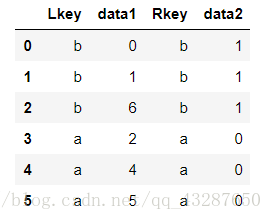
pd.merge(df1,df2,how='outer')
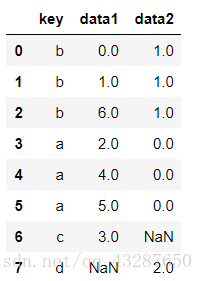
(4)pd.merge() 引數:how=‘left’ 作為合併引數,以左邊為主
pd.merge() 引數:how=‘right’ 作為合併引數,以右邊為主
(5)以多個列名進行合併

pd.merge(df_left,df_right,on=['key1','key2'],how='outer')
df_left 指定以key1進行連線,df_right指定以key2進行連線,以取並集的方式連線
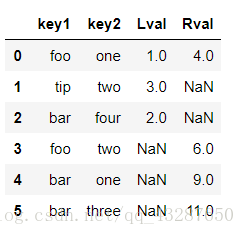
pd.merge(df_left,df_right,on=['key1','key2'],how='inner')
df_left 指定以key1進行連線,df_right指定以key2進行連線,取交集
總結:pandas.merge(df1,df2,on=’ ‘,how=’ ')
2.concat連線資料
語法:pandas.concat([s1,s2,…],axis=0或1,join=’ ',keys=[ ])
- 建立三個series,並用concat進行連線,結果是直接將之進行拼接
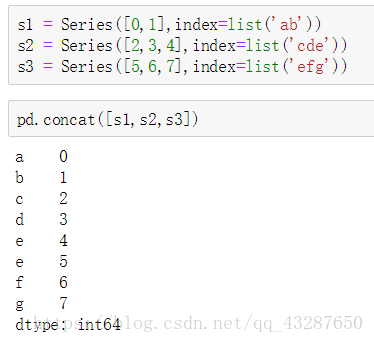
-
axis預設為0,豎著連線,資料直接拼接在後面;
-
axis=1時,橫著連線,沒有資料的顯示nan
-
引數:join=‘inner’ 交集 ; join=‘outer’ 並集

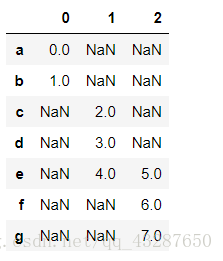
pd.concat([s1,s4],axis=1,join='outer') # 預設的連線方式,並集
pd.concat([s1,s4],axis=1,join='inner') # 交集
- 引數keys:連線時給層次索引
# 連線時給層次索引
s5 = pd.concat([s1,s2,s3],keys=['one','two','three'])

3.pd.combin_first()合併重疊資料
如果左邊有值,顯示左邊的資料;
如果左邊是nan,右邊有值,則顯示右邊的資料;
如果左邊和右邊都是nan,則顯示nan
語法:
s1.combine_first(s2)
s1 是左邊的資料集,s2是右邊的資料集。Series和Dataframe都可以使用
二、資料規整化–重塑與軸向選擇
主要用於重塑表格型資料的結構
- stack :將列旋轉為行
- unstack:將行旋轉為列
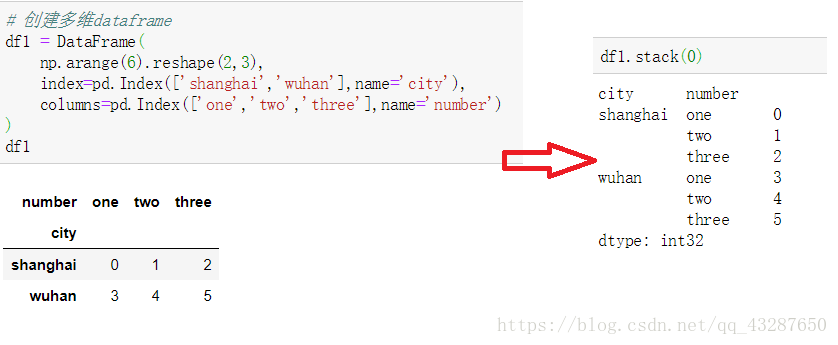
1.series和DataFrame的相互轉化
(1)對於一個層次化索引的series,可以使用unstack 將其轉化為一個dataframe:
unstack()有兩個引數:0或1
為0時:是預設的引數,將最外層的行索引轉化為列索引
為1時:將最內層的行索引轉化為列索引
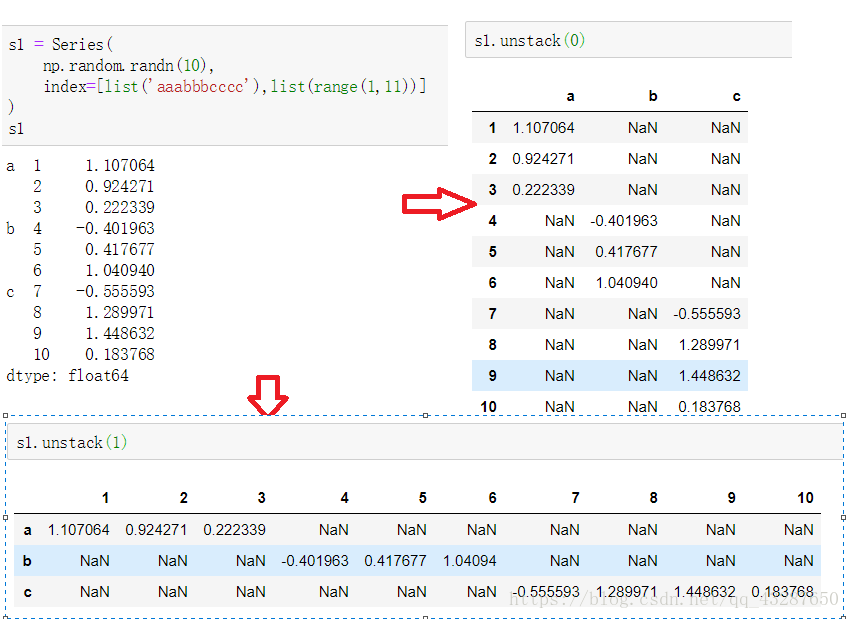
注意:unstack除了使用引數1,0來指定列,還可以通過索引的名稱來進行指定,例如:
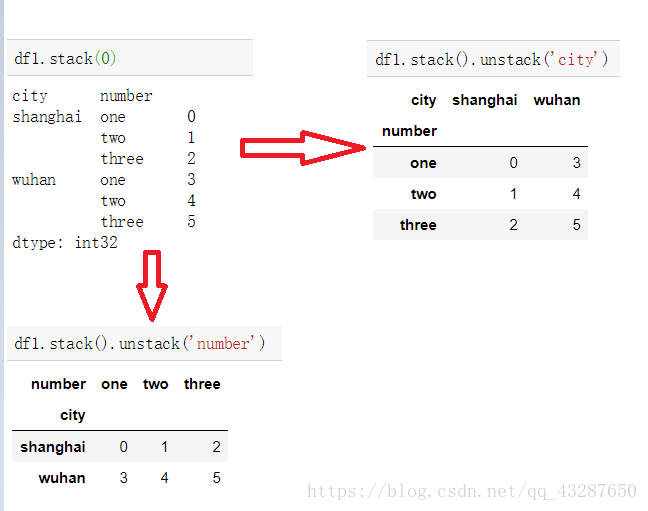
(2)對於一個多層次的DataFrame,使用df.stack()將之轉化為series
stack 沒有引數1,只有引數0
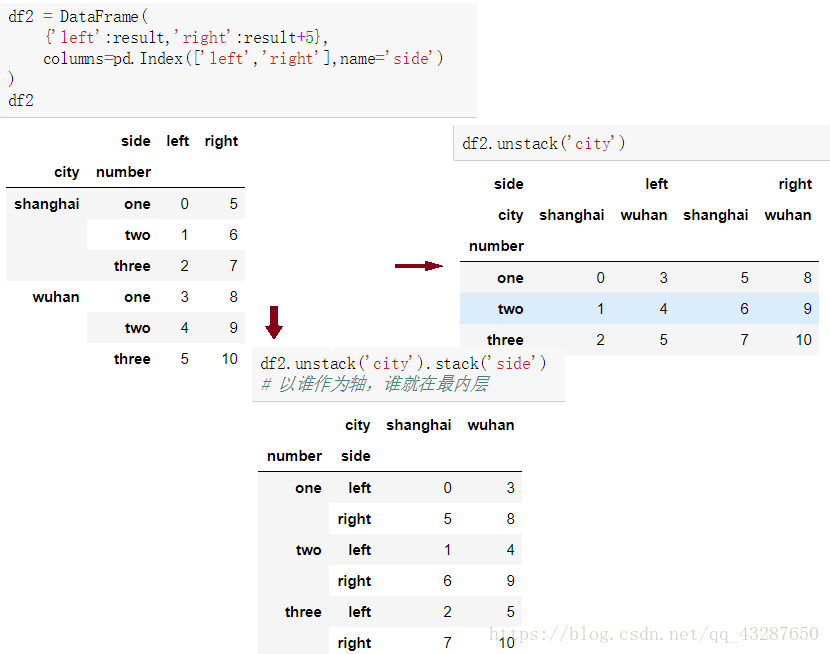
(3)對dataframe進行unstack和stack的時候,指定哪個索引名稱旋轉,哪個索引就會旋轉為最低級別。
三、資料規整化-資料轉換
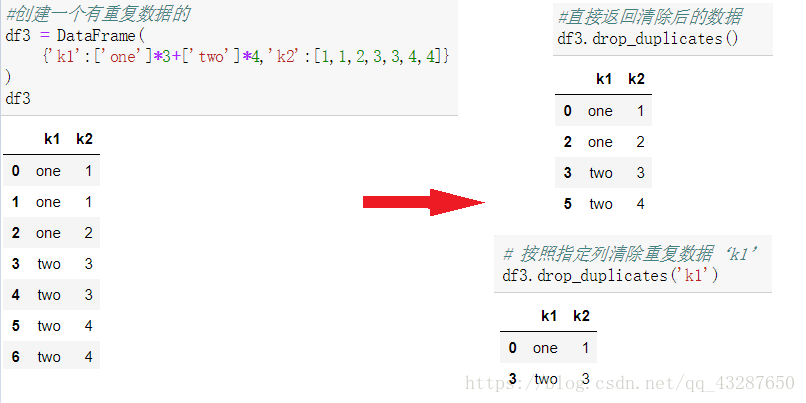
1.清除重複資料
語法:xx.drop_duplicates()
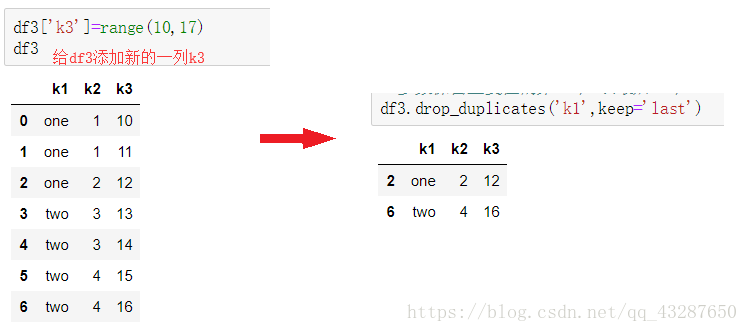
(1)按指定列清除重複資料
(2)保留重複值的第一個或最後一個。
keep=‘first’(預設) :保留重複值的第一個資料
keep=‘last’ :保留重複值的最後一個數據
2.利用函式和對映進行轉換
步驟:
1、先編寫一個對映
2、再利用map函式來進行對映
準備一個有對映的資料集:
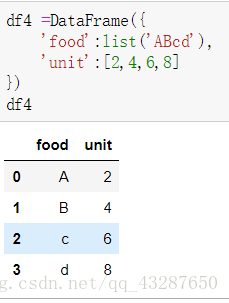
接下來我們要將以下的資料一一對映到上面的資料集中:
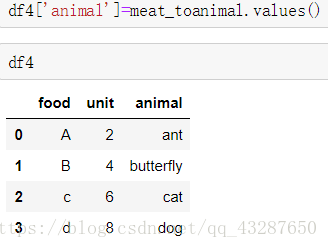
先試試直接將meat_toanimal 中的值直接新增到df4中,看似沒有問題,但實際上只是擴充套件了一列,並沒有進行一一對映。
現在,我們要來進行一一對映啦:
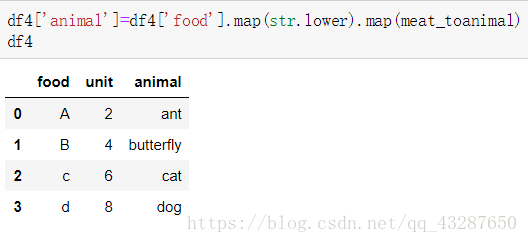
第一種方法:讀取df4中的food列,將他們全部轉化為小寫的abcd,再和meat_toanimal進行一一對映。
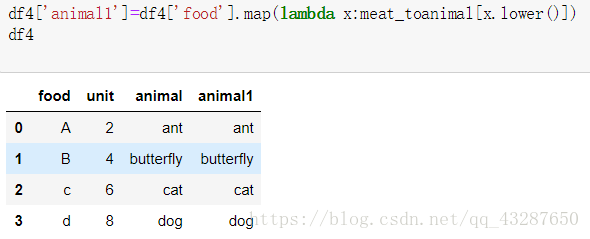
第二種方法:直接傳入一個能使用此功能的函式

3.替換值
利用fi11na方法填充缺失資料可以看做值替換的一種特殊情況。雖然前面提到的map可用於修改物件的資料子集,而 replace則提供了一種實現該功能的更簡單、更靈活的方式。
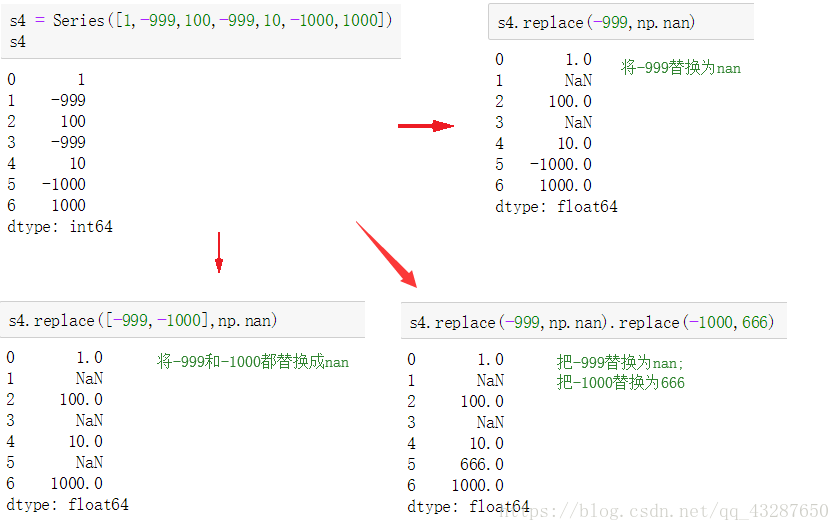
語法:xx.replace(原資料,替換的值)
注意:替換後原資料還是不變的
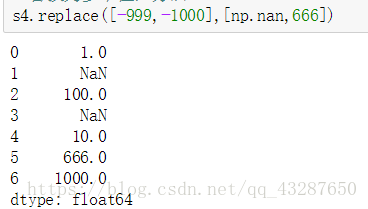
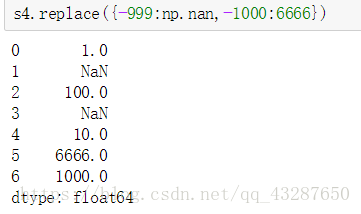
同時替換多個值的方法:
方法一:
方法二:
4.資料拆分
(1)cut:等分割槽間
語法:pandas.cut(資料,分箱,right=’ ',labels=[])
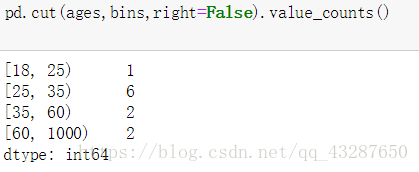
right預設為True,左閉右開,當right='False’的時候,就是左開右閉
labels:給區間取名稱
【例1】
可以看到ages 按照bins進行cut,被分成了四個區間,返回的是區間而不是值,第一個資料17因為不在任何一個區間內,因此得到的是nan
一般來說,我們都要對分箱後的結果進行統計

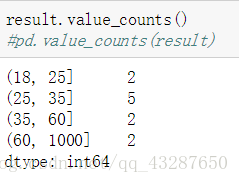
看看使用引數right的結果,right=‘False’ 區間變成左開右閉
咱們給區間取個名兒吧~ labels=[]

【例2】前面的那個例子是我們自己定義了一個bins區間,當然我們也可以寫上一個數字,表示自動將區間平均分為幾等分
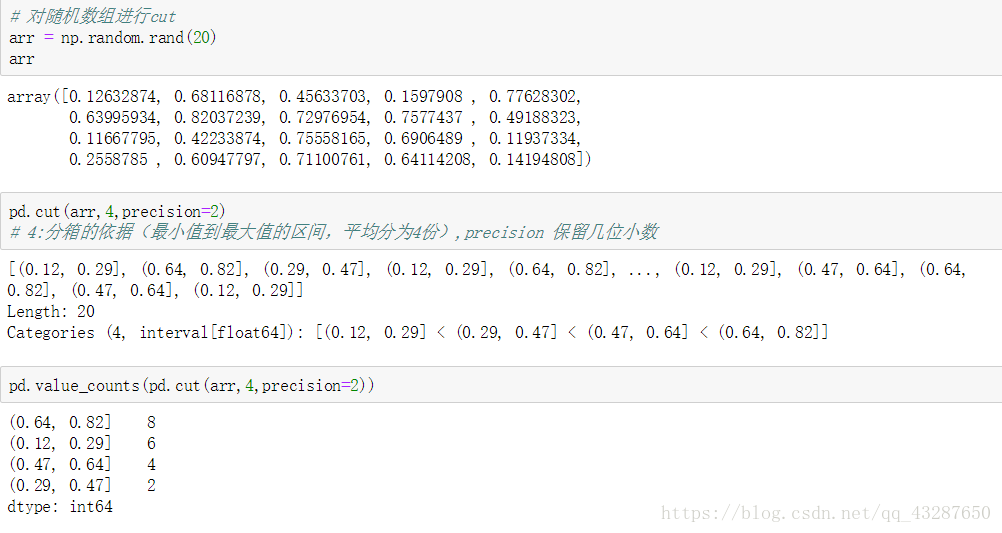
(2)qcut:等分值
如果不想等分值,可以定義份數:pd.qcut(x,q) q引數 如果是列表,範圍是在0-1之間
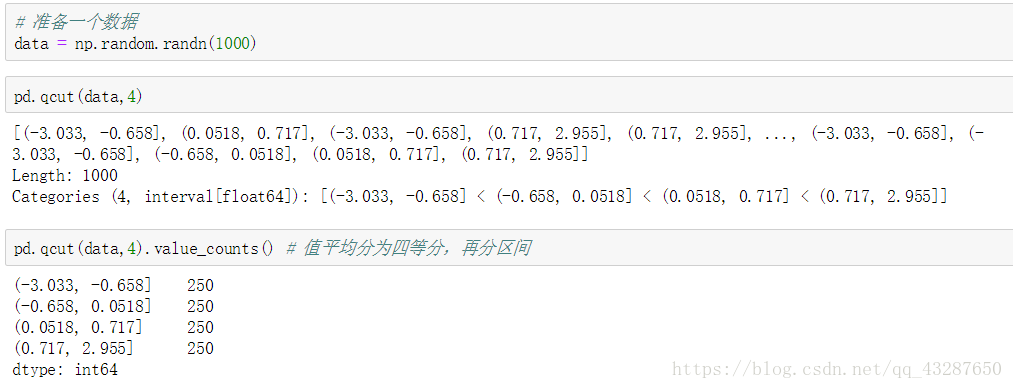
這是等分為4段的例子:

(重要)連續資料不等分 會根據 如:q=[0,0.1,0.3,0.6,1],每2個數的差值進行比例計算,把最大值和最小值插值的區間按照這個比例進行劃分
這是把值分為1份、2份、3份、4份

5.檢查和過濾異常值
異常值的過濾或變換運算在很大程度上其實就是陣列運算。
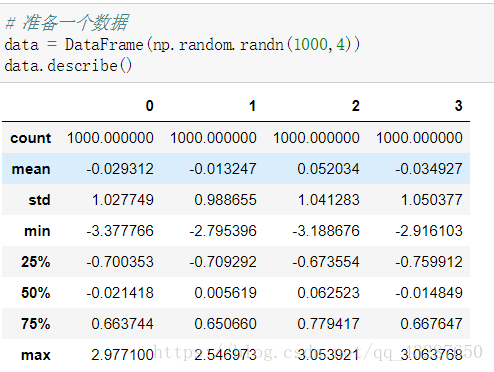
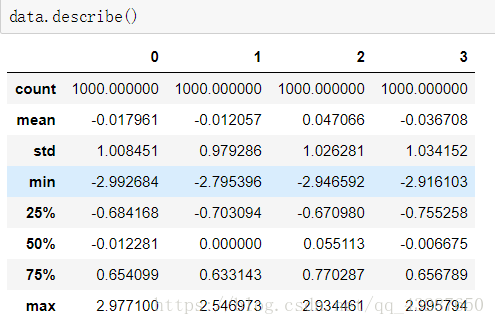
【案例】想過濾絕對值大於3的數
我們先準備一個數據集,統計看看大概情況:
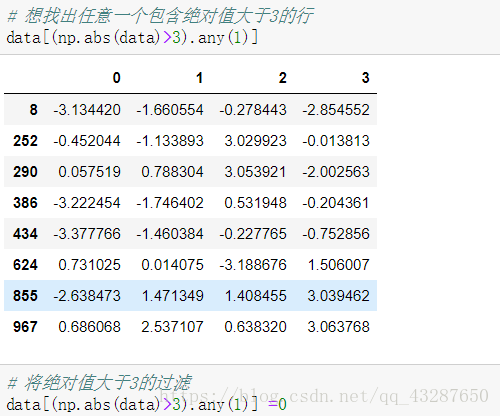
把包含絕對值大於3的行資料都過濾掉
看!最大值和最小值的絕對值都小於3了
這只是舉了一個絕對值的例子,當然要結合其他的陣列運算靈活使用哦~
四、 Pandas中的資料載入、儲存與解析

1.讀取
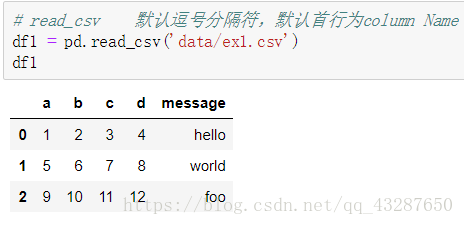
讀寫文字格式的檔案 :read_csv()
(1)直接讀取:預設分割符是‘,’,預設首行為列名
read_csv(‘文字名稱’)
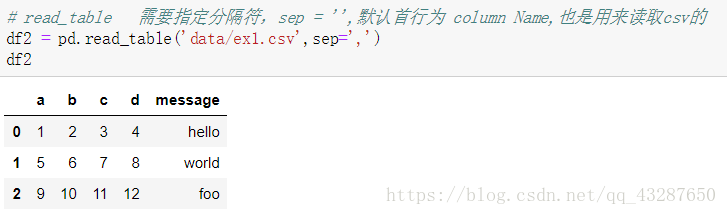
也可以用read_table進行讀取,但是需要指定分隔符
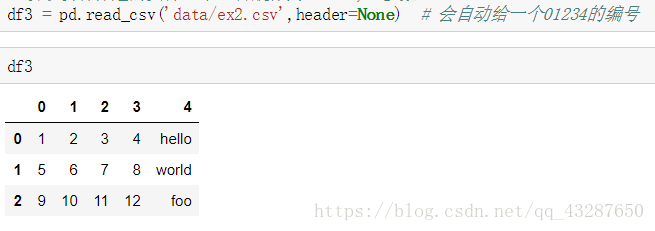
(2)讀取沒有列名的檔案,加入引數header=None
(3)給沒有列名的檔案取個列名
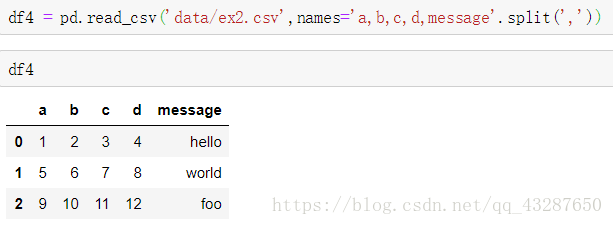
(4)給沒有列名的檔案取個列明,並將其中一個變為行索引
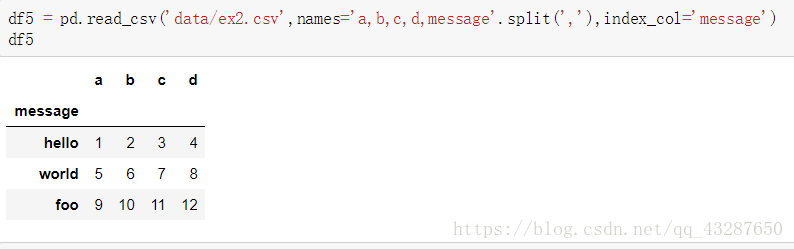
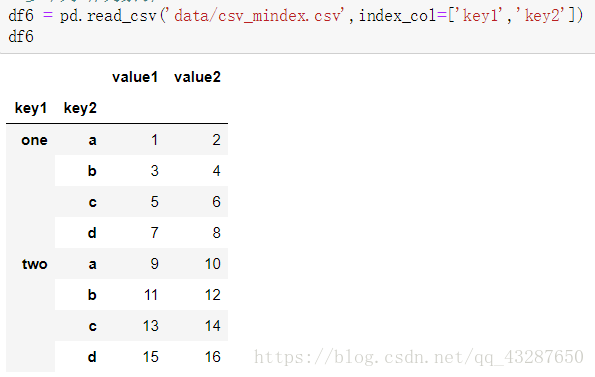
- 多個列作為行索引
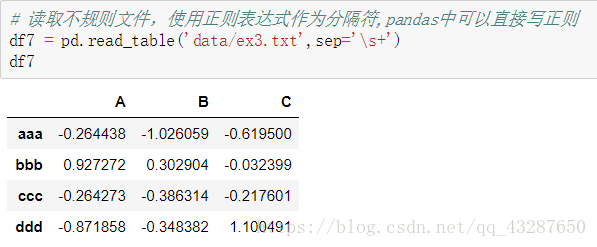
(5)讀取不規則檔案,使用正則表示式
這個檔案是中間有很多空格
(6)跳行讀取 ,skiprows引數
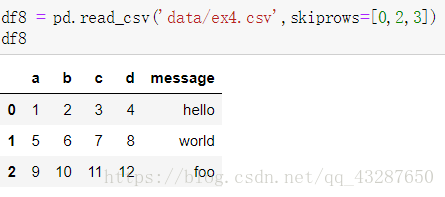
(7)讀取有缺失值的檔案,na_values = [‘null’]

2.寫入csv
語法:xx.to_csv() ,預設逗號分割
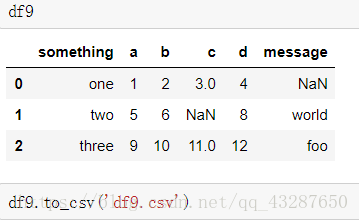
(1)直接儲存資料
將df9 直接儲存到csv檔案裡
預覽一下儲存的內容
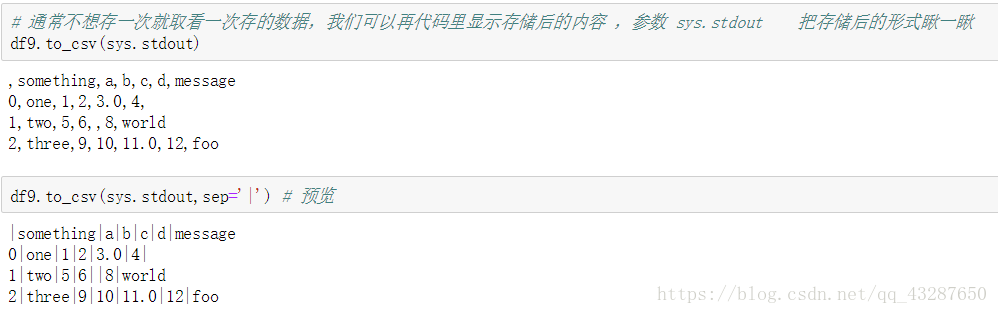
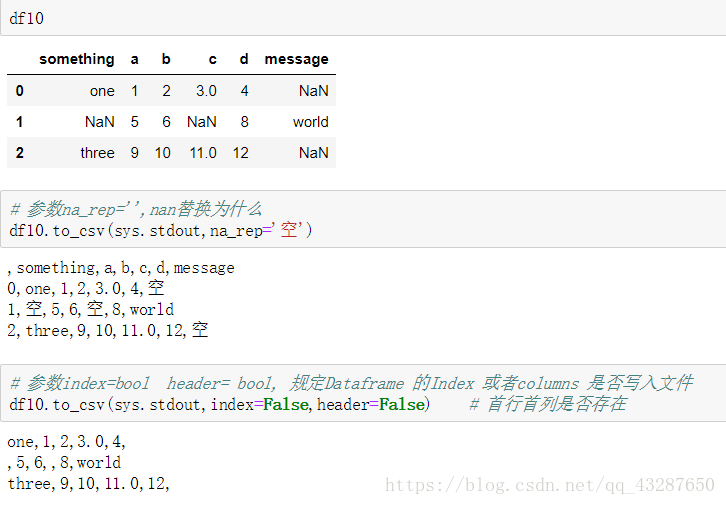
(2)to_csv()的一些引數
五、資料聚合與分組計算
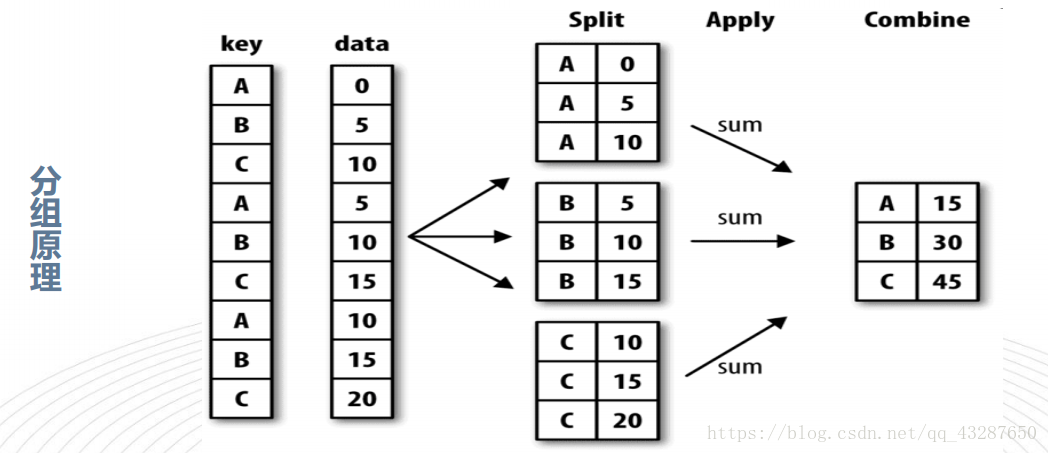
1.資料分組與聚合結合
(1)
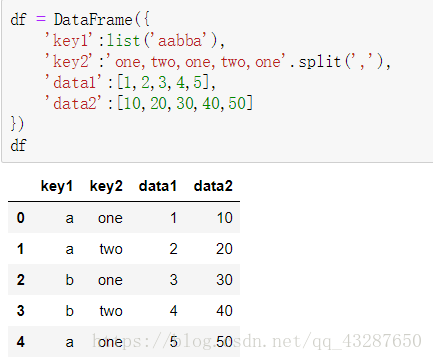
我們先看看這個具體是怎麼操作的,先準備一個數據集
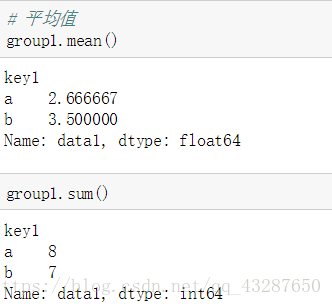
我們把data1的資料按照key1來進行分組,這一步是沒有進行任何計算的,只有分組
現在我們可以對它進行任何聚合運算了

(2)
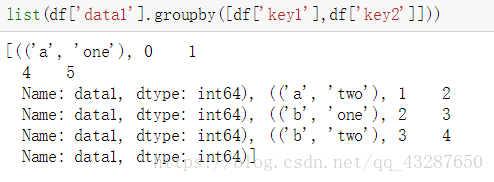
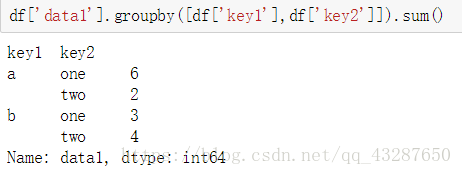
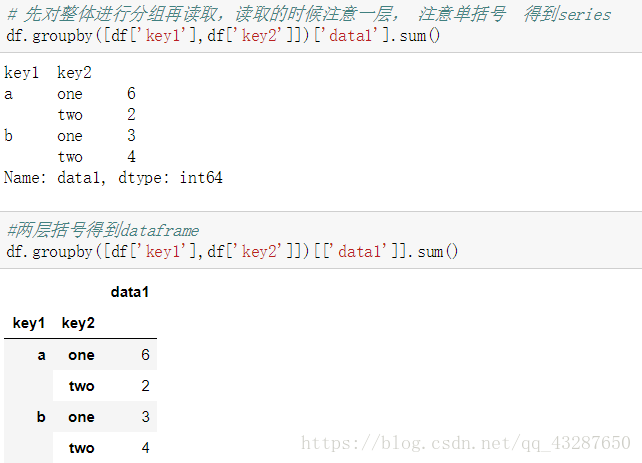
接下來,我們看看對多個條件進行分組是怎麼樣的,我們把data1按照key1和key2進行分組,得到了一個物件
轉化為列表看看是個什麼東西
a one 有兩個值 在索引為0的位置的值是1;在索引為4的位置的值是5
a two 在索引為1的位置值是2
b one 在索引為2的位置值是3
b two 在索引為3的位置值是4

下面仍然對它進行聚合
(3)以上我們都是先讀取再分組,再聚合。
當然我們也可以先分組再讀取,再聚合
(4)對分組進行迭代
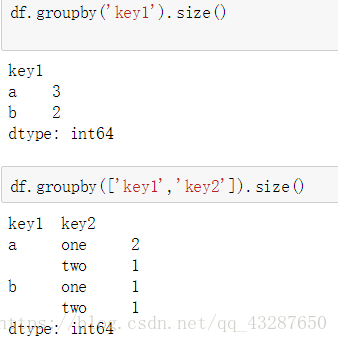
(5)size方法檢視分組資料的數量
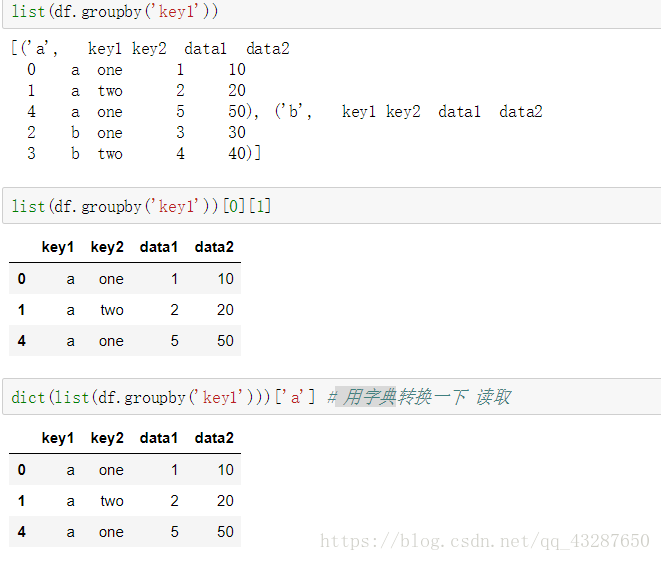
(6)讀取分組後的資料
轉換為列表或者字典進行讀取
(7)通過字典或者series進行分組
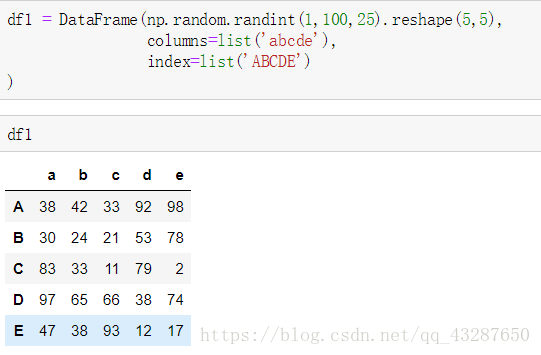
我們準備好一個數據集
①用字典進行分組
現在建一個字典,a,b,c一一對應,意思就是將abc分為一個組main,de分為1個組minor,再將之運用到df1中,按列索引進行分組。
②用series進行分組


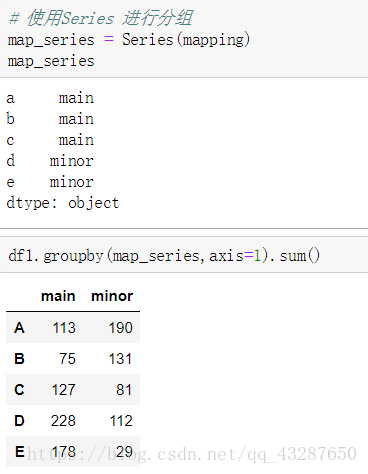
2.資料聚合
(1)自帶的聚合函式
求平均值:mean
求和:sum
求最大值:max
求最小值:min
統計:describe
計數:count
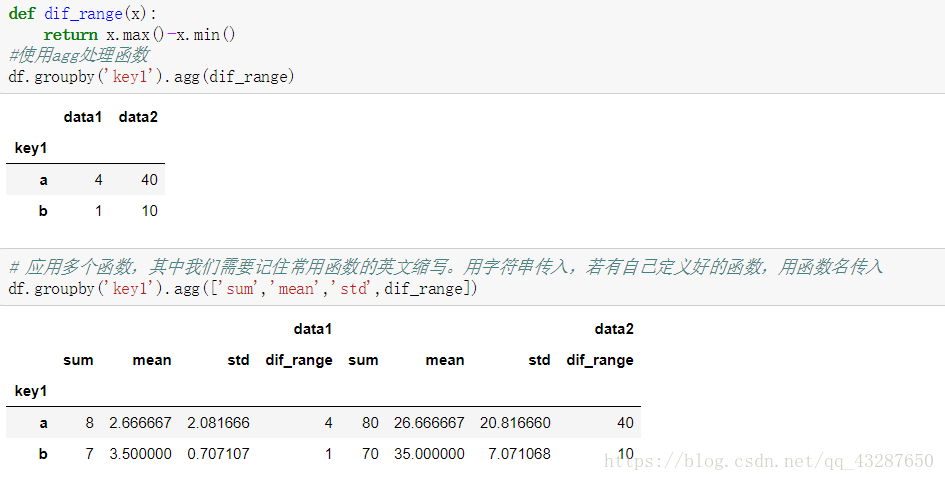
(2)自定義聚合函式
使用agg函式可以定義求哪些聚合
給列取個名字
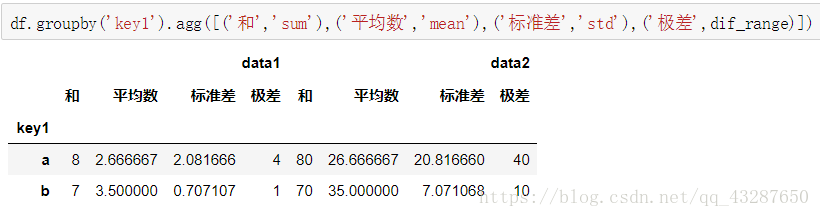
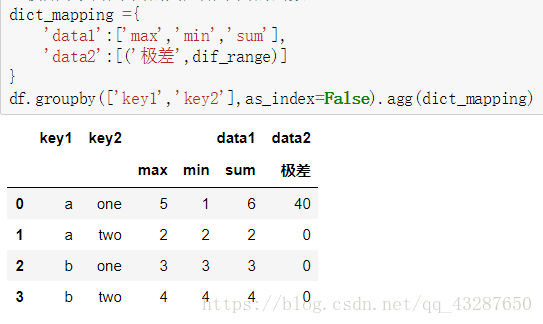
使用字典來給不同的列應用不同的函式
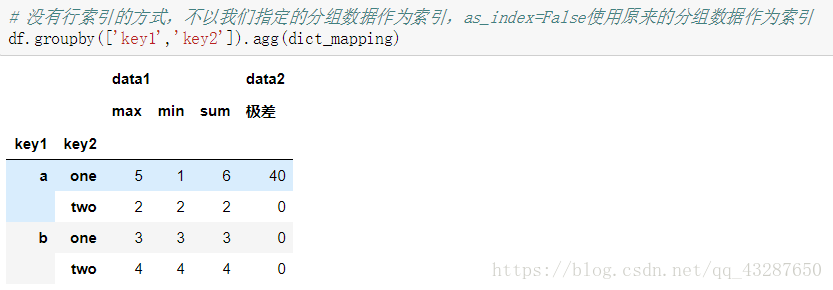
看看as_index=False有什麼作用:
3.神奇的apply
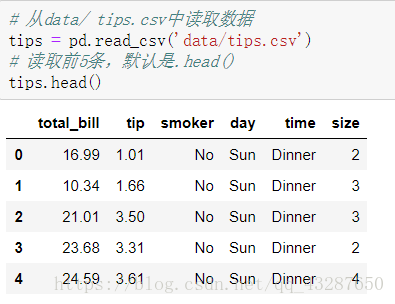
讀取一個數據,看一下它的前5條,如果想看倒數幾條的資料就用tail()
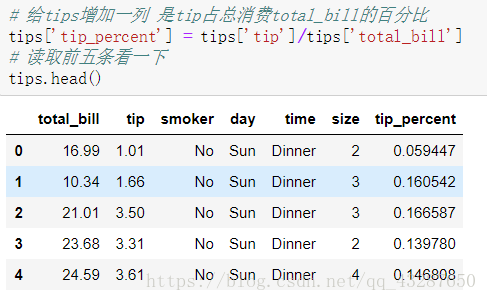
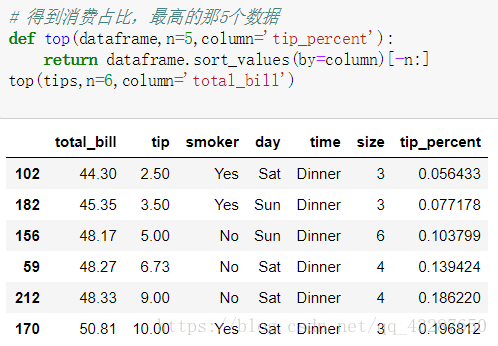
新增一列資料,消費百分比
得到消費佔比最高的6個數據
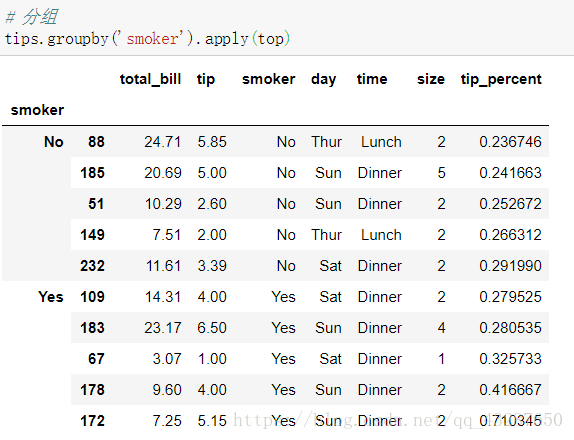
通過apply運用上面的函式,顯示的都是預設的資料
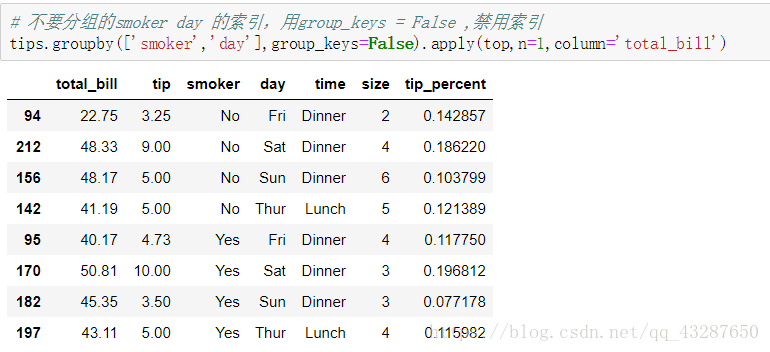
應用一些引數
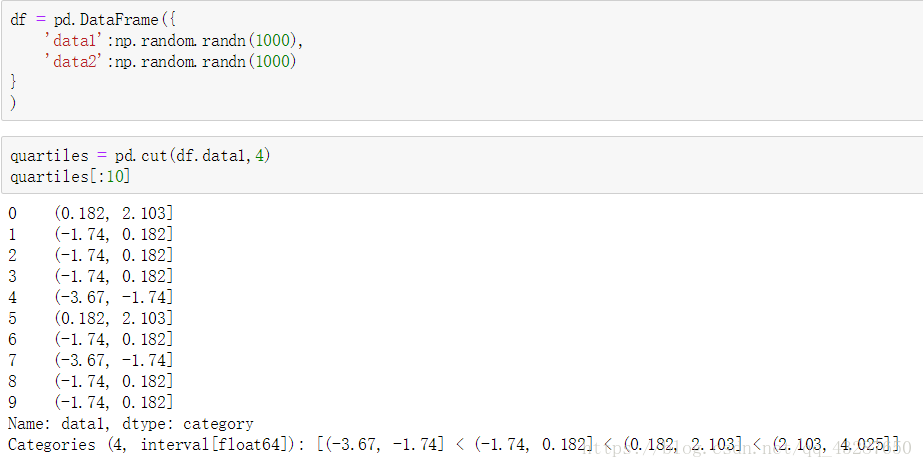
4.分位數和桶分析
準備一個數據集,拆分為區間相等的4份
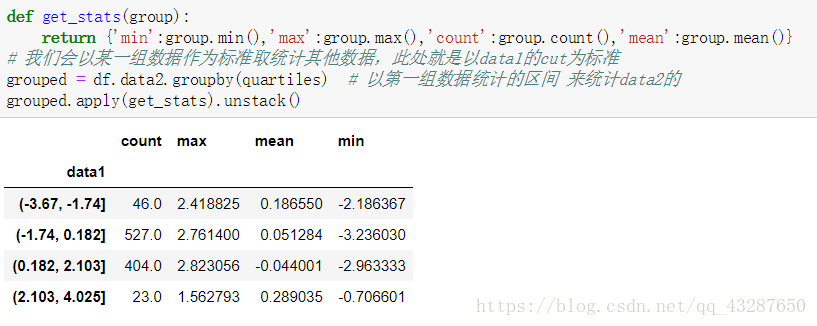
5.分組加權平均數
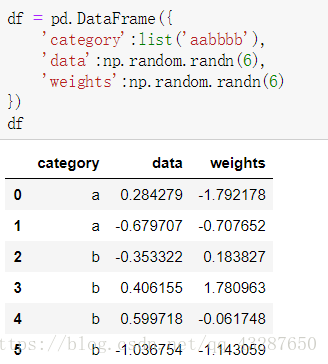
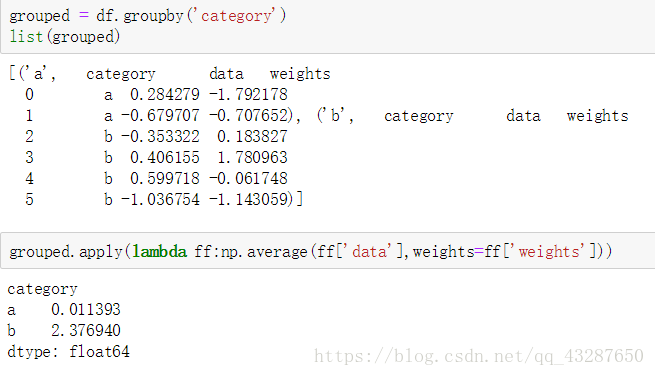
準備一個數據:
進行加權:
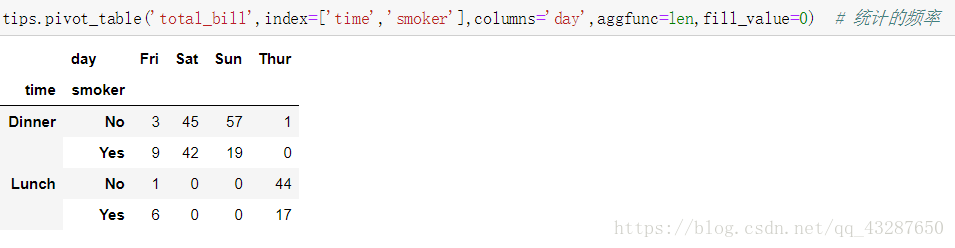
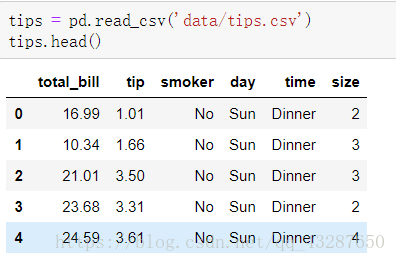
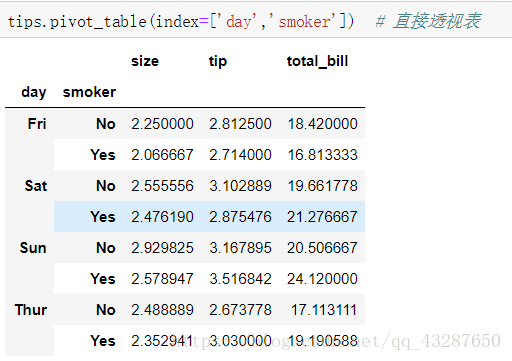
6.透視表
語法:xx.pivot_table()
讀取資料:
直接進行透視:
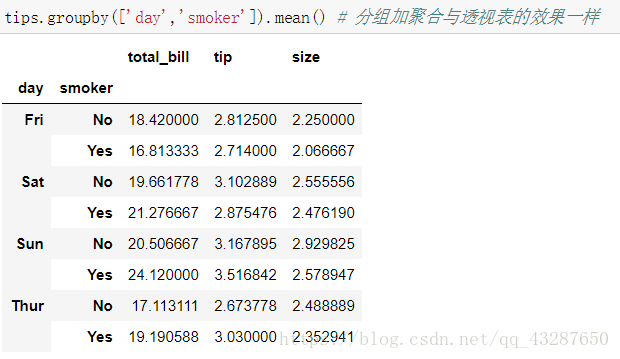
和上面效果一樣,說明預設是mean
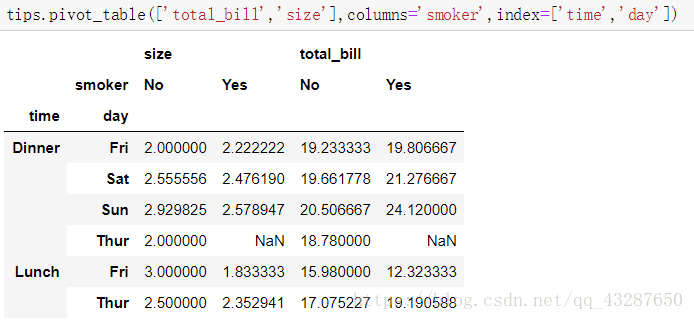
指定行和列索引
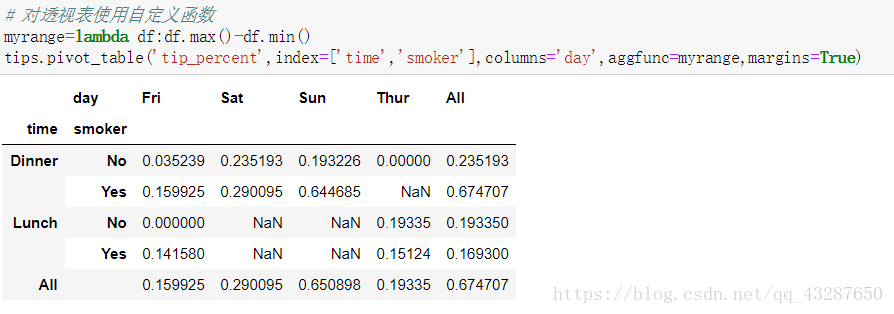
margins=True

使用aggfunc引數