
awk 幾個特殊的內建變數
1、特殊變數:
NR:讀取到所有記錄(包括多個檔案)的行數索引號(大概是Number Of Record的意思);
FNR:只的是awk所讀取到的每個檔案中的行數索引號,當檔案發生切換時候,FNR重新從1開始,大概是File Number Of Record的意思;
NF:當前行中的欄位個數(列數);
注:awk可以指定同時讀取多個檔案,按照指定的先後順序,逐個讀取。
FS:輸入欄位分隔符(預設值為空格)
OFS:輸出欄位分隔符(預設值為空格)
RS:輸入記錄分隔符(預設值為換行符)
ORS:輸出記錄分隔符(預設值為換行符)
2、NR和FNR區別:
1)對於單個檔案NR 和FNR 的 輸出結果一樣的 ,例如:
# awk '{print NR,$0}' file1
1 a b c d
2 a b d c
3 a c b d
#awk '{print FNR,$0}' file1
1 a b c d
2 a b d c
3 a c b d 2)對於多個檔案結果就不一樣了,例如:
# awk '{print NR,$0}' file1 file2 1 a b c d 2 a b d c 3 a c b d 4 aa bb cc dd 5 aa bb dd cc 6 aa cc bb dd # awk '{print FNR,$0}' file1 file2 1 a b c d 2 a b d c 3 a c b d 1 aa bb cc dd 2 aa bb dd cc 3 aa cc bb dd
3)利用NR和FNR完成兩個檔案的關聯Join:
有兩個簡單的檔案
[[email protected] tmp]$ cat a.txt
1,a-1
2,a-2
3,a-3
4,a-4
[[email protected] tmp]$ cat b.txt
2,b-2
4,b-4
5,b-5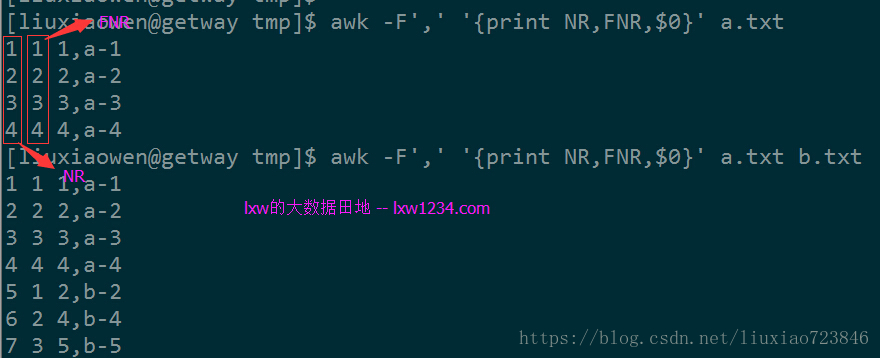
上面第一個命令中,awk只讀取一個檔案,因此NR和FNR是一樣的;第二個命令有兩個檔案,從NR=5開始讀取第二個檔案b.txt。
由這點可以得出一個規則:當NR==FNR時候,讀取到的內容為第一個檔案的內容,當NR!=FNR時候,讀取到的內容是第二個檔案的。看下面的命令:
[[email protected] tmp]$ awk -F',' 'NR==FNR{a[$1]=$2;}NR!=FNR{print $0,a[$1]}' b.txt a.txt
1,a-1
2,a-2 b-2
3,a-3
4,a-4 b-4從輸出的結果來看,已經將兩個檔案通過第一列的值join起來,準確的說是a.txt left outer join b.txt。解釋一下這個命令:
第一部分:
NR==FNR{a[$1]=$2;}a是一個數組;當NR==FNR,也就是讀取第一個檔案的內容(第一個檔案就是後面的b.txt),以b.txt中的$1作為陣列索引號,以b.txt中的$2作為陣列的值;因此,第一部分過後,有了一個數組a,具體的值為 a[2]=”b-2″, a[4]=”b-4″, a[5]=”b-5″
再看第二部分:
NR!=FNR{print $0,a[$1]}當NR!=FNR時候,也就是讀取第二個檔案的內容(a.txt),print $0(列印a.txt中的內容),以及a[$1],這裡的含義是以a.txt中的$1為索引號,去陣列a中獲取值,因為之前陣列a中的索引號有2,4,5;因此a.txt中第一列為2和4的記錄從陣列a中獲取到了值,1,3,5在陣列a中不存在。
如果是將兩個檔案做內關聯:
[[email protected] tmp]$ awk -F',' 'NR==FNR{a[$1]=$2;}NR!=FNR && a[$1] {print $0,a[$1]}' b.txt a.txt
2,a-2 b-2
4,a-4 b-4變了一個條件:NR!=FNR && a[$1]
讀取第二個檔案的內容,並且第二個檔案的$1在陣列中存在,也可以寫成 $1 in a
[[email protected] tmp]$ awk -F',' 'NR==FNR{a[$1]=$2;}NR!=FNR && $1 in a {print $0,a[$1]}' b.txt a.txt
2,a-2 b-2
4,a-4 b-4