
requests與BeautifulSoup爬取嗅事百科
阿新 • • 發佈:2018-11-10
爬取嗅事百科
今天我們利用requests和bs4來爬取嗅事百科的內容。
爬取步驟:
- 分析網頁結構
- 利用request來獲取網頁內容
- 利用bs4來篩選網頁內容
- 列印或者儲存網頁內容
接下來,我們一步一步來完成這些事
1.分析網頁結構

由此可知,段子裡面的容都是儲存在
2.利用request來獲取網頁內容
#模擬瀏覽器 headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} #獲取網頁內容 r = requests.get('http://www.qiushibaike.com', headers = headers).text
3.利用bs4來篩選網頁內容
#利用lxml解析網頁內容
soup = BeautifulSoup(r, 'lxml')
#找到所有上面的內容的標籤
divs = soup.find_all('div',attrs={'class':'content'})
4.將內容打印出來
#列印所有的內容
for div in divs:
contents = div.span.get_text()
print(contents)
#開啟檔案,寫入內容 with open('C:\\Users\\Administrator\\Desktop\\11.txt','a') as f: f.write(contents)
總程式:
import requests from bs4 import BeautifulSoup headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} r = requests.get('http://www.qiushibaike.com', headers = headers).text soup = BeautifulSoup(r, 'lxml') divs = soup.find_all('div',attrs={'class':'content'}) print(divs) for div in divs: contents = div.span.get_text() with open('C:\\Users\\Administrator\\Desktop\\11.txt','a',encoding='utf-8') as f: f.write(contents) print(contents)
我們做一個比較全面的,爬取某頁的嗅事百科
看一下這兩張圖片,就知道了區別了
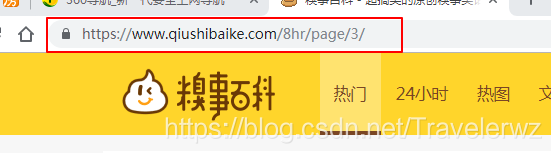
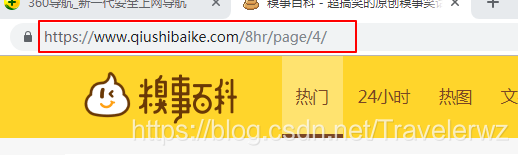
可以看出來,url的地址是不一樣的,區別就是最後這個數字,這樣我們就很好去選擇了。
程式碼:
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
#傳入引數,第幾頁的引數
def pages(num):
url = 'https://www.qiushibaike.com/8hr/page/'+'str(num)'
r = requests.get(url, headers = headers).text
soup = BeautifulSoup(r, 'lxml')
divs = soup.find_all('div',attrs={'class':'content'})
print(divs)
for div in divs:
contents = div.span.get_text()
with open('C:\\Users\\Administrator\\Desktop\\11.txt','a',encoding='utf-8') as f:
f.write(contents)
print(contents)
pages(5)