
第36天併發程式設計之程序篇
目錄:
1. 基礎概念
2. 建立程序和結束程序
3. 程序之間記憶體空間物理隔離
4. 程序的屬性方法
5. 守護程序
6. 互斥鎖
7. IPC通訊機制
8. 生產者消費者模型
一. 基礎概念
1. 什麼叫做程式,什麼叫做程序?
程式就是程式設計師寫的一堆程式碼檔案。
程序指的是程式正在執行的一個過程,是一個抽象的概念,起源於作業系統。
2. 什麼是作業系統?
作業系統是位於計算機硬體與應用程式之間的,用於協調,控制和管理計算機硬體和軟體資源的控制程式
3. 作業系統的兩大作用
(1). 將複雜醜陋的硬體操作都封裝成簡單的介面,提供給應用程式使用,大大的提高了應用程式的開發效率
(2). 把程序對硬體的競爭變得有序
4. 批處理系統
將程式設計師寫的程式攢成一堆,然後一個一個的讀到記憶體裡面進行執行。
解決了第一代作業系統一個人獨佔計算機資源的問題,雖然節省了大量的時間,但是本質上還是序列
此時已經出現了作業系統的概念,以及程序的雛形。
5. 多道技術
產生背景:在單核下實現併發的效果。
兩大核心:
空間複用:
將多個程式同時讀入到記憶體中,等待被cpu執行。此時也就出現了多程序的概念。
特點:每個程式的記憶體空間都是物理隔離的。
時間複用:
複用cpu的時間片
cpu什麼時候會切換程序的執行?
1.在遇到i/0阻塞的時候就會暫時的掛起此程序,切換到另一個程序去執行
2.正在執行的程序佔用cpu的時間過長,或者有一個優先順序更高的程序出現的時候也會切換執行
優點:大大的提高了計算機cpu的利用率,實現了併發的效果。是當代計算機作業系統的雛形。
6. 序列,並行,併發,阻塞
序列:程式從上到下依次執行。批處理系統典型的就是序列。
並行:同一時刻執行多個程式。如果只有一個核是不可能實現並行的,只有多核的時候才能真正的實現並行。
併發:同一時間段內執行多個程式,使用者看起來就像是並行一樣。
併發實現的本質:儲存當前的狀態 + cpu的切換
阻塞:遇到i/0就進入阻塞狀態。
7. 程序的屬性
pid: 用來唯一的表示一個程序,就像是身份證號。
name: 程序名稱
terminate: 殺死當前子程序
is_alive: 檢視子程序是否還活著
join: 等待子程序結束
start: 向系統傳送一個建立子程序的系統呼叫
daemon: 將子程序設定成守護程序
方法:
os.getpid() 獲得當前程序的pid
os.getppid() 獲得當前程序的父程序pid
8. 程序相關的win的命令
tasklist: 檢視當前程序資訊
taskkill /F /PID 程序號 殺死一個程序
tasklist |findstr pyth 通過管道檢視相應的值
9. 殭屍程序和孤兒程序
殭屍程序:子程序死了,但是父程序還沒有死,此時的子程序就稱之為殭屍程序。
任何程序死了之後都會回收相應的資源,但是對於一些基本的資訊是不會回收的,例如pid,name等,以被父程序所檢視,這就存在一個問題。
當父程序建立了大量的子程序,而父程序又很長的時間內不會不會死掉,對於記憶體空間的佔用倒不是很嚴重,但是會佔用大量的pid,而pid的資源是有限的。
因此我們的程式中不應該出現大量的殭屍程序,如果父程序需要執行很長的時間,我們就需要在適當的時候回收子程序的資源,防止出現大量的無用殭屍程序。
join方法就會提供回收殭屍程序的功能。
孤兒程序:父程序死了,但是子程序沒有死,這是的子程序就稱之為孤兒程序。
孤兒程序沒有害,因為孤兒程序會被init程序所接管,在一定的時間之後會被清理掉。但是程式中也不應該出現大量的孤兒程序。
二. 建立程序和結束程序
程序建立的方式
1.系統初始化,在開機的時候自動就會載入作業系統,此時就會出現一個根程序。
2.使用者的互動式請求,例如在電腦上雙擊暴風影音,就是建立了一個程序,再雙擊就又建立了一個程序。
3.一個批處理作業的初始化(專用計算機的系統載入)
4.一個程序執行的過程中通過模組重新開啟一個子程序 (我們關注的是這種方式的程序的建立)
linux: fork
在初始化的時候子程序和父程序是完全一樣的。
win:CreateProcess
初始狀態的時候子程序和父程序並不是完全一樣的。
程序的結束方式
1. 正常退出
2. 出錯退出
3. 被另一個程序殺死
第一種建立程序的方式
from multiprocessing import Process import time def task(name): print('%s is running...' %name) # 模擬子程序執行了一系列的操作 time.sleep(2) print('%s is ending...' %name) # 在windows下面必須要這樣寫 # 這是因為在win下建立一個程序的時候會重新執行一遍此模組 # 為了防止迴圈建立,所以必須要在此地方建立子程序 if __name__ == '__main__':# 建立了一個程序物件 # target代表的是子程序要執行的任務,一般是函式名稱 # args:裡面的值是給函式傳遞的引數 p = Process(target=task, args=('egon',)) # 此處並不是直接建立子程序,而是向作業系統傳送了一個系統呼叫 # 作業系統會申請一個記憶體空間,建立一個子程序 # 對於主程序而言,這行程式碼就像是平常的程式碼一樣,主程序並不會等待子程序的建立,然後就去繼續執行了 p.start() # 因此結果是先列印下面的提示資訊,之後才會去列印task函式內的東西 print('p.start()程式碼一旦執行完,我是不會等系統建立子程序的,我立馬就要執行')
第二種建立程序的方式
from multiprocessing import Process import time class MyProcess(Process): def __init__(self, name): # 重用父類的功能,然後傳遞自己函式所需要的引數 super(MyProcess, self).__init__() self.name = name # p.start()其實就是系統去呼叫run函式,因此我們將之前的內容放到run函式裡面 def run(self): print('%s is running...' %self.name) # 模擬子程序執行了一系列的操作 time.sleep(2) print('%s is ending...' %self.name) if __name__ == '__main__': p = MyProcess('egon') p.start() print('主程序')
三. 程序之間記憶體空間物理隔離
from multiprocessing import Process x = 100 def task(): global x x = 0 print('子程序結束...') if __name__ == '__main__': p = Process(target=task) p.start() # 等待子程序結束之後在去列印x的值 p.join() # 如果空間是共享的,等待子程序結束之後x的值應該是0 # 如果空間是隔離的,子程序結束之後x的值還是100 print(x)
四. 程序的屬性方法
join方法
from multiprocessing import Process import time def task(): print('子程序開始...') time.sleep(2) if __name__ == '__main__': p = Process(target=task) p.start() # 如果沒有join,就會先列印x,然後才會去執行task函式 # 有了join之後,主程序就會阻塞在這裡,等待子程序p結束之後才會列印x p.join() print('主程序.....') # 結果: # 子程序開始...


from multiprocessing import Process import time def task(n): print('%s開始...' %n) time.sleep(n) if __name__ == '__main__': start = time.time() p1 = Process(target=task, args=(1, )) # p1睡了1s p2 = Process(target=task, args=(2, )) # p2睡了2s p3 = Process(target=task, args=(3, )) # p3睡了3s p1.start() p2.start() p3.start() # 程式執行到這個地方的時候p1,p2, p3可能都已經開始執行了 # 無論主程序是在等誰,所有的子程序都是會執行的 # 也就是說在等待p1的過程中子程序p3也在執行,因此整個程式的執行時間應該是最耗時的子程序時間 # 此處也就是三秒多 p1.join() # 等待子程序1s p2.join() # 等待子程序2s p3.join() # 等待子程序3s end= time.time() print('執行時間>>', start - end) # 執行結果: # 2開始... # 1開始... # 3開始... # 執行時間>> -3.2581233978271484join容易迷惑的地方
from multiprocessing import Process import time def task(): print('子程序開始...') time.sleep(2) if __name__ == '__main__': # 如果迴圈的建立了子程序,需要等待所有程序結束我們就需要通過一個迴圈去等待 l = [] for i in range(5): p = Process(target=task) l.append(p) p.start() for p in l: p.join() print('主') # 結果: # 子程序開始... # 主程序.....join迴圈等待子程序結束
自定義檢視ppid的方法(待填)
五. 守護程序
1. 什麼是守護程序
obj = Process(target=lambda x: x + 1) # 建立一個子程序
obj.daemon = True # 當設定了此屬性之後,這個子程序就會變成一個守護程序
效果: 當主程序結束之後,守護程序就會隨著結束
2. 為什麼要有守護程序?
我們建立一個子程序就是為了併發的執行多個任務,有時候我們的子任務在主任務結束之後就沒有存在的必要了,因此,在主程式結束之後,我們往往希望可以自動的結束掉這些子程序,因此就有了守護程序。
例如:當我們通過qq在傳一個檔案的時候,qq是主程序,傳檔案是子程序,當qq退出去之後還應該會傳檔案嗎,肯定不會,所以此時就應該把傳檔案設定成一個守護程序,當qq退出去的時候自動的關掉子程序。
3. 重點
如果一個主程序中既有守護程序也有非守護程序,那麼當主程序的程式碼執行完畢以後守護程序就會死掉,並不會等到主程序清理完非守護程序之後才死掉。
例子:
from multiprocessing import Process import time def task(name): print(name, 'is running...') time.sleep(3) print("ending....") if __name__ == '__main__': p = Process(target=task, args=('egon',)) p.start() print('主程序over') # 執行結果: 只有等待子程序完全結束之後才會結束掉主程序,防止 # H:\python_study\venv\Scripts\python.exe H:/python_study/day36/部落格/守護程序.py # 主程序over # egon is running... # ending.... # # Process finished with exit code 0正常產生的主程序會等待子程序結束之後才會結束
from multiprocessing import Process import time def task(name): print(name, 'is running...') time.sleep(3) print("ending....") if __name__ == '__main__': p = Process(target=task, args=('egon',)) p.daemon = True # 將子程序變成一個殭屍程序 p.start() print('主程序over') # 結果:當主程序執行完print操作之後就直接結束了,守護程序也會隨之而結束 # H:\python_study\venv\Scripts\python.exe H:/python_study/day36/部落格/守護程序.py # 主程序over # # Process finished with exit code 0主程序結束之後守護程序也就跟著結束了
from multiprocessing import Process import time def foo(): print(123) time.sleep(0.1) print(456) def bar(): print(789) time.sleep(2) print('10002') if __name__ == '__main__': p1 = Process(target=foo) p2 = Process(target=bar) p1.daemon = True p1.start() p2.start() print('主程序.....') # 當這一行程式碼執行完畢之後,就代表著主程序相關的任務已經執行完畢,守護程序在此時就沒有守護的必要的了,因此會被幹掉 # 結果: 列印完主程序之後,p1程序作為守護程序就會被幹掉 # 主程序..... # 789 # 10002守護程序和非守護程序都存在的情況下
六. 互斥鎖
1. 什麼叫做互斥鎖
對於同一個系統資源,如果一個程序加上了互斥鎖,另一個程序也加上了同一個互斥鎖,誰先搶到誰先執行,直到釋放鎖之後,另個一程序才能夠使用此資源。
2. 互斥鎖和join的區別
原理都是一樣的,都是為了將併發變成序列,從而保證有序。
區別一:
互斥鎖:程序平等的競爭,誰先搶到誰先執行。
join: 按照人為指定的順序執行。
區別二:
互斥鎖:將一部分程式碼進行序列
join: 只能將程式碼整體
區別一:互斥鎖和join
步驟一:建立一個py程式,用來列印三個人的資訊,建立了三個函式,每個函式裡面都有一個sleep來模擬網路延遲,因此我們寫出了下面的程式碼
import time def task1(): print('task1: 名字, egon') time.sleep(0.1) print('task1: 性別, male') time.sleep(0.1) print('task1: 年齡, 13') def task2(): print('task2: 名字, alex') time.sleep(0.1) print('task2: 性別, male') time.sleep(0.1) print('task2: 年齡, 18') def task3(): print('task3: 名字, wxx') time.sleep(0.1) print('task3: 性別, male') time.sleep(0.1) print('task3: 年齡, 21') if __name__ == '__main__': task1() task2() task3()正常的列印三個人的資訊
步驟二:這樣寫雖然解決了問題,但是執行效率太慢了,完全受不了,因此想著怎麼讓三個任務進行併發,從而提高執行效率,因此我們建立了三個程序,分別用來執行三個任務,所以寫出來了下面這個程式碼
from multiprocessing import Process import time def task1(): print('task1: 名字, egon') time.sleep(0.1) print('task1: 性別, male') time.sleep(0.1) print('task1: 年齡, 13') def task2(): print('task2: 名字, alex') time.sleep(0.1) print('task2: 性別, male') time.sleep(0.1) print('task2: 年齡, 18') def task3(): print('task3: 名字, wxx') time.sleep(0.1) print('task3: 性別, male') time.sleep(0.1) print('task3: 年齡, 21') if __name__ == '__main__': p1 = Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p1.start() p2.start() p3.start()通過建立子程序的形式提高執行效率
步驟三:這樣子寫雖然是提高了執行效率,但是我們發現結果並不是我們想要的,我們希望的是無論哪個任務先執行,總是希望可以讓這個任務的資訊列印完成之後才去執行之後的任務。有兩種解決方法1, 就是jion方法,2. 就是互斥鎖,首先我們以join的方法讓當前資訊列印變得有序。

from multiprocessing import Process import time def task1(): print('task1: 名字, egon') time.sleep(0.1) print('task1: 性別, male') time.sleep(0.1) print('task1: 年齡, 13') def task2(): print('task2: 名字, alex') time.sleep(0.1) print('task2: 性別, male') time.sleep(0.1) print('task2: 年齡, 18') def task3(): print('task3: 名字, wxx') time.sleep(0.1) print('task3: 性別, male') time.sleep(0.1) print('task3: 年齡, 21') if __name__ == '__main__': p1 = Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p1.start() p1.join() # 在此處加上join方法,使得等待第一個程式執行完成之後在去執行第二個程序 p2.start() p1.join() p3.start() p1.join()join方法使得併發變得有序
步驟四:結果變得確實有序了,但是這樣寫是有問題的,1. 完全沒有併發的效果 關於這個問題我們暫時忽略,只是為了討論併發才拿出來這樣一個例子的。2. 這樣子寫其實是人為的規定了讓p1程序先執行,然後是p2程序,然後是p3程序。這樣是非常不公平的,我們的初衷並不希望人為的規定哪個子程序先進行操作,因此我們可以使用互斥鎖,這就需要引入另一個類Lock
# 鎖的使用方法,使用比較簡單,就兩個函式 mutex = Lock() # 建立一個互斥鎖 mutex.acqure() # 加鎖 。。。。這是我們希望控制的程式碼 mutex.release() # 釋放鎖
# 注意:
1. 在子程序中所使用的鎖必須是同一把鎖,就是鎖必須要在if語句中建立,並且通過引數的形式傳遞給子程序。
2. 對於同一個程序鎖只能加一次
3. 必要的程式碼執行完畢之後必須要釋放鎖
from multiprocessing import Process, Lock import time def task1(lock): lock.acquire() print('task1: 名字, egon') time.sleep(0.1) print('task1: 性別, male') time.sleep(0.1) print('task1: 年齡, 13') lock.release() def task2(lock): lock.acquire() print('task2: 名字, alex') time.sleep(0.1) print('task2: 性別, male') time.sleep(0.1) print('task2: 年齡, 18') lock.release() def task3(lock): lock.acquire() # 加鎖 print('task3: 名字, wxx') time.sleep(0.1) print('task3: 性別, male') time.sleep(0.1) print('task3: 年齡, 21') lock.release() # 解鎖 if __name__ == '__main__': mutex = Lock() # 建立一個鎖 p1 = Process(target=task1, args=(mutex,)) # 然後將這一個鎖當做引數進行傳遞 p2 = Process(target=task2, args=(mutex,)) p3 = Process(target=task3, args=(mutex,)) p1.start() p2.start() p3.start()互斥鎖解決併發的亂序的問題

區別二:共享鎖寫一個簡單的搶票小程式
步驟一:建立一個db檔案用來存放共享資料,也就是票的數量。因為程序之間的通訊目前還沒有學到,但是對於磁碟的訪問每個程序都是可以訪問的,因此先建立db檔案
{"count": 1}
步驟二:寫一個不加鎖不加延遲的一個簡單功能
from multiprocessing import Process import os import json import time def search(): """查詢當前還有幾張票""" with open('db.json', 'r', encoding='utf-8') as f: print('%s 剩餘票數 %s' %(os.getpid(), json.load(f)['count'])) def get(): """購買票""" with open('db.json', 'r', encoding='utf-8') as f: dic = json.load(f) if dic['count'] > 0: dic['count'] -= 1 with open('db.json', 'w', encoding='utf-8') as f: json.dump(dic, f) print('%s 購買票成功' % os.getpid()) def task(): """搶票程式,包含一個查詢票和購買票的功能""" search() get() if __name__ == '__main__': for i in range(5): p = Process(target=task) p.start()不加鎖不加延遲
步驟三: 如果沒有延遲的情況下,我們的程式目前來看已經具備了搶票的功能,因為在沒有延遲的情況下,當所有程序建立完成之後就是一些基本的運算,cpu的執行是非常快的,因此cpu在執行get函式的時候基本上是不會切換到其他的程序中執行的。但是如果有延遲的情況就不一樣了,加上延遲之後因為cpu會切換,所以導致結果不可控,有兩種解決方案,1. join將整個程序變成序列的 , 雖然join可以解決問題,但是對於查詢票數這個操作來說,我們並不希望是序列的,因此此方法並不合適 2. 用互斥鎖
from multiprocessing import Process,Lock import os import json import time import random def search(): """查詢當前還有幾張票""" # 加上查詢票的延遲 time.sleep(random.randint(1,3)) with open('db.json', 'r', encoding='utf-8') as f: print('%s 剩餘票數 %s' %(os.getpid(), json.load(f)['count'])) def get(): """購買票""" with open('db.json', 'r', encoding='utf-8') as f: dic = json.load(f) if dic['count'] > 0: dic['count'] -= 1 # 加上購買票的延遲 time.sleep(random.randint(1, 3)) with open('db.json', 'w', encoding='utf-8') as f: json.dump(dic, f) print('%s 購買票成功' % os.getpid()) def task(lock): """搶票程式,包含一個查詢票和購買票的功能""" search() lock.acquire() get() lock.release() if __name__ == '__main__': metux = Lock() for i in range(10): p = Process(target=task, args=(metux,)) p.start()用互斥鎖解決搶票問題
七. IPC通訊機制
IPC: 程序之間的通訊
問題: 兩個程序之間的記憶體空間是物理隔離的,因此怎麼通訊呢?
程序之間通訊的方式:
1. 上面講到的建立一個共享檔案
檔案的i/0操作太浪費時間,因此這個方式不建議使用
2. 通道
之前學過subprocess也可以實現程序之間的通訊,但是這個程序之間必須是父子程序,並且是半雙工模式,因此也不推薦使用
3. 共享記憶體
Manager,可以通過此類建立一個共享的字典或者列表,為了防止資料出錯,在修改資料的時候我們需要自己新增鎖,很麻煩,也不建議使用
Queue: 佇列,我們可以通過佇列的方式實現程序之間的通訊,佇列在內部已經幫我們添加了鎖。
IPC機制應該遵循的原則
1. 所有程序都應該可以共享資料
2. 共享的資料最好應該在記憶體中
3. 並且我們不需要去操作鎖,也就是IPC應該幫我們處理好鎖的功能
Manager存在的問題:要自己定義鎖才能對資料進行修改
# 建立共享記憶體空間,並進行修改 from multiprocessing import Process, Manager def task(dic): dic['num'] -= 1 if __name__ == '__main__': m = Manager() dic = m.dict({'num': 10}) l = [] for i in range(10): p = Process(target=task, args=(dic, )) p.start() l.append(p) # 等待子程序結束 for p in l: p.join() print(dic) # 結果: # {'num': 0}# 建立共享記憶體空間,並進行修改
步驟一:建立一個共享的記憶體空間,然後通過建立程序去修改共享字典的內容,我們發現我們想要的效果Manager確實是已經幫我們實現了,但是當我們在task函式做了以下修改之後,再列印資訊就會發現所出來結果不是0而是9了
def task(dic): temp = dic['num'] # 和之前的dic['num'] = 1性質是一樣的,但是為什麼結果不一樣呢 time.sleep(0.1) dic['num'] = temp - 1
步驟二:這是因為在建立程序之後,所有的程序基本上都會在同一時間內拿到temp的值為10,也就是說10個程序的temp都是10, 當他們睡完0.1秒之後無論是誰進行修改dic的值都是10-1所以結果是0,因此對於Manager建立的記憶體空間預設在修改資料的時候是不會給我們加鎖的,因此我們需要自己去加鎖對資料進行修改,否則資料就會被損壞。
from multiprocessing import Process, Manager, Lock import time mutex = Lock() def task(dic, lock): lock.acquire() # 加鎖,防止資料被破壞 temp = dic['num'] time.sleep(0.1) dic['num'] = temp - 1 lock.release() if __name__ == '__main__': m = Manager() dic = m.dict({'num': 10}) l = [] for i in range(10): p = Process(target=task, args=(dic, mutex)) p.start() l.append(p) # 等待子程序結束 for p in l: p.join() print(dic) # 結果: # {'num': 0}加鎖使得資料變得安全
Queue佇列簡介
特點 1. 先進先出 2. 佇列只應該傳送訊息,資料量不應該過大 3.建立佇列的長度不應該過大,因為它佔用的是記憶體的空間 方法 put: 往佇列裡面新增東西 引數一:obj,放到佇列裡面的物件 引數二: block,如果佇列滿了是否阻塞 引數三: timeout,超時時間,在佇列的阻塞的狀態下才有意義 get: 從佇列裡面拿東西 引數一:block, 如果佇列為空是否阻塞, 引數二:timeout,超時時間,在佇列阻塞狀態下才有意義 例子: # 建立佇列,佇列長度為3 q = Queue(3) q.put('first') q.put({'second': None}) q.put('三') # q.put('四') # 預設會阻塞 q.get() q.get() q.get()
八:生產者消費者模型
生產者和消費者模型
1.模型指的是一種解決問題的套路
2.該模式下具備兩種角色
生產者: 生產資料
消費者: 處理資料
3.該模型的運作方式
生產者生產資料,放到一個共享的空間中,然後消費者取走進行處理
4.該模型的實現方式一
生產者程序 + 佇列 + 消費者程序
佇列中存放的是一些訊息,不應該存放大量的資料
5.該模型的應用場景
如果程式中由明顯的兩類任務,一類任務是負責生產資料,另外一類是負責處理資料的
就應該使用生產者和消費者模型
6.該模式的優點
1. 實現了生產者和消費者解耦和
2. 平衡了生產者的生產資料的能力與消費者處理資料的能力
案例:模擬一個生產者和消費者模型
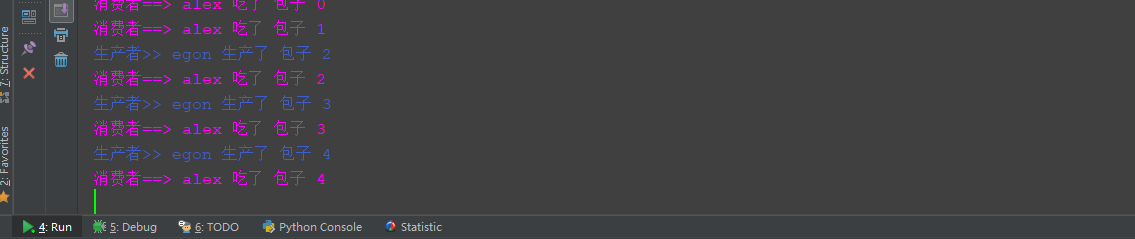
import time import random from multiprocessing import Process, Queue def consumer(name, q): while True: res = q.get() time.sleep(random.randint(1,2)) print('\033[35m消費者==> %s 吃了 %s\033[0m' %(name, res)) def producer(name, q, food): for i in range(5): res = '%s %s' %(food, i) time.sleep(random.randint(1, 2)) q.put(res) print('\033[34m生產者>> %s 生產了 %s \033[0m' %(name, res)) if __name__ == '__main__': q = Queue() p1 = Process(target=producer, args=('egon', q, '包子')) c1 = Process(target=consumer, args=('alex', q)) p1.start() c1.start()簡單的生產消費者模型程式碼
問題一:我們會發現雖然實現了生產者和消費者併發執行的效果,但是當消費者吃完包子之後主程式阻塞掉了。主程式阻塞原因有兩個: 1. 主程式自己的程式碼沒有執行完畢,2. 主程序在等待子程序執行完畢。此處主程式的程式碼很明顯是阻塞在了消費者模型裡面。如何去解決這樣的問題呢?
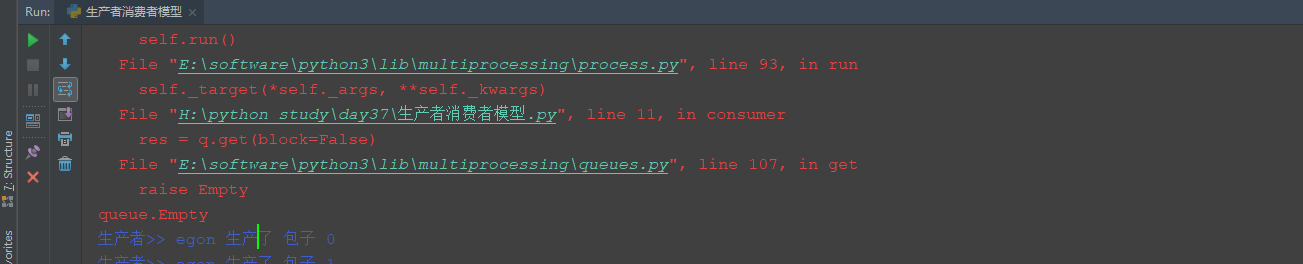
解決方案一:因為程式是在子程序的獲取佇列的時候阻塞掉了,因此我們考慮將佇列的修改成非阻塞狀態,但是發現報錯了,這是因為在c1和p1程序起來之後我們是不能確定誰先執行的,如果c1先執行了get,發現佇列裡面沒有內容,又是非阻塞狀態,就會報錯。因此佇列不能是非阻塞狀態。
def consumer(name, q): while True: # 在此處阻塞掉了,因此我們考慮將佇列設定為非阻塞 res = q.get(block=False) time.sleep(random.randint(1,2)) print('\033[35m消費者==> %s 吃了 %s\033[0m' %(name, res))
解決方案二:既然佇列必須是阻塞狀態,那麼我們能不能設定一個超時時間,但是對於消費者而言,超時時間設定為多少才合適呢?我們並不能確定生產者每次生產資料的時間,因此如果設定成了4, 但是生產者過了5s才生產一個數據該怎麼辦呢?這個方式也是不合理的。
def consumer(name, q): while True: # 佇列必須是阻塞狀態,因此設定超時時間 res = q.get(timeout=4) time.sleep(random.randint(1,2)) print('\033[35m消費者==> %s 吃了 %s\033[0m' %(name, res))
解決方案三:既然從消費者的角度無法解決這樣的問題,那麼我們就從生產者的角度來解決這樣的問題。當我生產完資料之後我額外的放一個None,當消費者收到這個標誌的時候就代表生產的資料完了,如下
def consumer(name, q): while True: res = q.get() # 當收到一個None時就結束掉子程序 if not res: break time.sleep(random.randint(1,2)) print('\033[35m消費者==> %s 吃了 %s\033[0m' %(name, res)) def producer(name, q, food): for i in range(5): res = '%s %s' %(food, i) time.sleep(random.randint(1, 2)) q.put(res) print('\033[34m生產者>> %s 生產了 %s \033[0m' %(name, res)) # 在我生產完資料之後就在佇列裡面設定一個None,然後消費者收到None之後就結束程序 q.put(None)
問題二:雖然我們完美的解決了問題,但是當我們的生產者變多了之後就會出現下面的這個效果,有的生產者產生的資料並沒有消費者去消費,那是因為每個生產者生產完資料之後都會往佇列中放入一個None,當一個消費者收到一個None的時候就會結束掉子程序,因此當你的生產者的數量一旦大於了消費者的數量,肯定會出現生產的資料沒有人去處理的問題。
if __name__ == '__main__': q = Queue() p1 = Process(target=producer, args=('egon', q, '包子')) # 添加了一個生產者 p2 = Process(target=producer, args=('hu', q, '甘蔗')) c1 = Process(target=consumer, args=('alex', q)) p1.start() p2.start() c1.start()

解決方案一: 之前的初衷是想等生產者程序結束之後在佇列的後面新增None,但是這個None的數量不能超過消費者的數量,因此我們可以通過在主程序中join來確定生產者模型結束之後,由子程序統一往佇列中新增None。 這種方法雖然可以解決問題,但是不好的地方在哪裡呢?我們有幾個消費者就要往佇列中新增幾個None,浪費空間,而且還麻煩,因此這種方案也不推薦。
if __name__ == '__main__': q = Queue() p1 = Process(target=producer, args=('egon', q, '包子')) # 添加了一個生產者 p2 = Process(target=producer, args=('hu', q, '甘蔗')) p3 = Process(target=producer, args=('hu', q, '米飯')) c1 = Process(target=consumer, args=('alex', q)) c2 = Process(target=consumer, args=('alex', q)) p1.start() p2.start() p3.start() c1.start() c2.start() # 記得將之前生產者函式中的put給刪除掉,搞了半天,我還以為我理解錯了呢 # 等待生產者生產完成之後再往佇列中新增None,個數為消費者的個數 p1.join() p2.join() p3.join() q.put(None) q.put(None) print('主程序..')
解決方案二:這個時候我們就要引入JoinableQueue佇列
實現原理:
1. 等待生產者生產完成之後,計入此時佇列裡的值,通過q.join()
2. 每次消費者get一個內容之後都會通過 task_done將之前計入的值減1
3. 當計入的值變成零的時候就代表隊列為空了
4. 在建立之處就設計消費者為守護程序
import time import random from multiprocessing import Process, Queue, JoinableQueue def consumer(name, q): while True: res = q.get() time.sleep(random.randint(1,2)) print('\033[35m消費者==> %s 吃了 %s\033[0m' %(name, res)) # 每次取出一個就將佇列計數減一 q.task_done() def producer(name, q, food): for i in range(5): res = '%s %s' %(food, i) time.sleep(random.randint(1, 2)) q.put(res) print('\033[34m生產者>> %s 生產了 %s \033[0m' %(name, res)) if __name__ == '__main__': q = JoinableQueue() p1 = Process(target=producer, args=('egon', q, '包子')) p2 = Process(target=producer, args=('hu', q, '甘蔗')) p3 = Process(target=producer, args=('hu', q, '米飯')) c1 = Process(target=consumer, args=('alex', q)) c2 = Process(target=consumer, args=('alex', q)) p1.start() p2.start() p3.start() # 設定守護程序 c1.daemon = True c2.daemon = True c1.start() c2.start() # 等待生產者生產完成之後再往佇列中新增None,個數為消費者的個數 p1.join() p2.join() p3.join() # 記錄當前佇列中還有值得數量 q.join() # 當執行到這一個步驟的時候,就代表消費者已經將內容取完了,主程序程式碼執行完畢之後,守護程序也就被殺死了 print('主程序..')最終實現程式碼