
pandas資料結構之Dataframe
Dataframe
DataFrame是一個【表格型】的資料結構,可以看做是【由Series組成的字典】(多個series共用同一個索引)。DataFrame由按一定順序排列的多列資料組成。設計初衷是將Series的使用場景從一維拓展到多維。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(numpy的二維陣列)
dataframe的建立
最常用的方法是傳遞一個字典或者二維陣列的方法建立
DataFrame(data=data,index=['張三','李四','王五'],columns=list('語數外'))
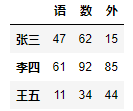
另外通過匯入csv檔案得到的也是DataFrame
import pandas as pd df1 = pd.read_csv('../backup/data/president_heights.csv') # 路徑名
DataFrame屬性:values、columns、index、shape
values:表格中的資料(二維陣列)
columns:列索引
index:行索引
shape:形狀
Dataframe的索引
(1) 對列進行索引
- 通過類似字典的方式
- 通過屬性的方式
按照列名進行索引,獲取到一個Series
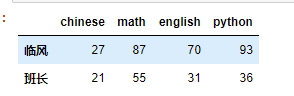
d = np.random.randint(0,100,size=(3,4)) d i= ['臨風','班長','孫武空'] # 行索引 c = ['chinese','math','english','python'] # 列索引 df = DataFrame(d,i,c)

df['math'] 臨風 87 班長 55 孫武空 28 Name: math, dtype: int32 type(df['math']) pandas.core.series.Series df.math 臨風 87 班長 55 孫武空 28 Name: math, dtype: int32
(2) 對行進行索引
- 使用.loc[]加index來進行行索引,顯式索引 - 使用.iloc[]加整數來進行行索引,隱式索引
同樣返回一個Series,index為原來的columns。
# df.loc['臨風'] # 顯式索引 df.iloc[0] # 隱式所引進
chinese 27 math 87 english 70 python 93 Name: 臨風, dtype: int32
總結
對 列 進行索引 df['列名'] df.列名 得到的是Series
對 行 進行索引 df.loc['行名'] df.iloc[行序號] 得到的是Series
(3) 對元素索引的方法
- 使用列索引
- 使用行索引
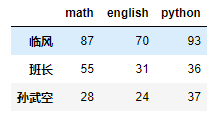
- 使用values屬性(二維numpy陣列)# 對具體元素進行定位 df.python.loc['班長'] # 先按列找 找到的是Series 在對Series進行索引 df.loc['班長'].iloc[-1] # df的loc或者iloc提供了更加優雅的方式 df.loc['班長','python'] df.iloc[1,-1] df.values # 如果DataFrame的索引記不清 可以直接通過values然後去定位值 array([[27, 87, 70, 93], [21, 55, 31, 36], [38, 28, 24, 37]]) df.values[1,-1]
【注意】 直接使用中括號時:
- 索引表示的是列索引
- 切片表示的是行切片
df['臨風':'孫武空']
df['臨風':'班長'] # 直接使用中括號 不能對列進行切片 而是對行進行切片(因為對行進行切片的需求比較常見)
# 如果非要對列 進行切片 可以使用loc或者iloc df.loc[:,'math':'python']
Dataframe的運算
(0) df和數值
df +5
相當於給表中的所有的資料都+5
# 對某一行樣本進行修改
df.loc['臨風']+=100
(1) DataFrame之間的運算
同Series一樣:
- 在運算中自動對齊不同索引的資料
- 如果索引不對應,則補NaN
# 建立DataFrame df1 不同人員的各科目成績,月考一 d = np.random.randint(0,100,size=(4,3)) d i = ['jack','rose','tom','jerry'] # 行索引 c = ['math','english','python'] # 列索引 df1 = DataFrame(d,i,c) df1
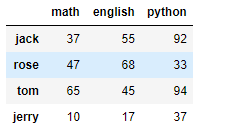
# 建立DataFrame df2 不同人員的各科目成績,月考二 有新學生轉入 d = np.random.randint(0,100,size=(5,3)) d i = ['jack','rose','tom','jerry','bob'] # 行索引 c = ['math','english','python'] # 列索引 df2 = DataFrame(d,i,c) df2
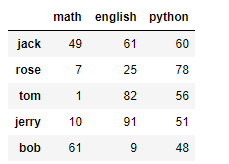
display(df1,df2) 可以讓資料同時顯示
df1+df2
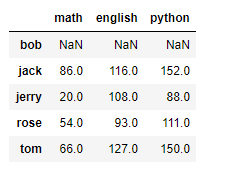
那麼有沒有辦法不顯示NaN呢,肯定是有的
其實物件使用 + 相加其實是執行了類中的add方法
所以
df1.add(df2,fill_value=0) # 設定上這個引數就可以給沒有的資料設定一個預設值=
結果展示:

下面是Python 操作符與pandas操作函式的對應表:

(2) Series與DataFrame之間的運算
【重要】
-
使用Python操作符:以行為單位操作,對所有行都有效。(類似於numpy中二維陣列與一維陣列的運算,但可能出現NaN)
-
使用pandas操作函式:
axis=0:以列為單位操作(引數必須是列),對所有列都有效。 axis=1:以行為單位操作(引數必須是行),對所有行都有效。
例子:
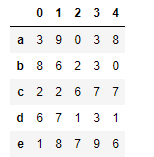
df = DataFrame(data=np.random.randint(0,10,size=(5,5)),index=list('abcde'),columns=list('01234')) df
s1 = Series(data=np.random.randint(0,10,size=5),index=list('01234')) s1
0 1 1 3 2 1 3 1 4 9 dtype: int32
df+s1 # 表格和序列 相加 預設 每一行都要和序列相加 對應項相加
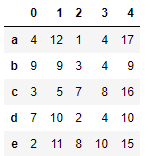
s2 = Series(data=np.random.randint(0,10,size=5),index=list('abcde')) s2
df+s2 # 輸出的結果全部都是NaN
# axis='columns' 預設是columns 每一行和Series相加 讓列名和Series中的索引去對應 df.add(s2,axis='index')