
k8s的Health Check(健康檢查)
強大的自愈能力是 Kubernetes 這類容器編排引擎的一個重要特性。自愈的預設實現方式是自動重啟發生故障的容器。除此之外,使用者還可以利用 Liveness 和 Readiness 探測機制設定更精細的健康檢查,進而實現如下需求:
-
零停機部署。
-
避免部署無效的映象。
-
更加安全的滾動升級。
下面通過實踐學習 Kubernetes 的 Health Check 功能。
1.預設的健康檢查
我們首先學習 Kubernetes 預設的健康檢查機制:
每個容器啟動時都會執行一個程序,此程序由 Dockerfile 的 CMD 或 ENTRYPOINT 指定。如果程序退出時返回碼非零,則認為容器發生故障,Kubernetes 就會根據 restartPolicy
下面我們模擬一個容器發生故障的場景,Pod 配置檔案如下:
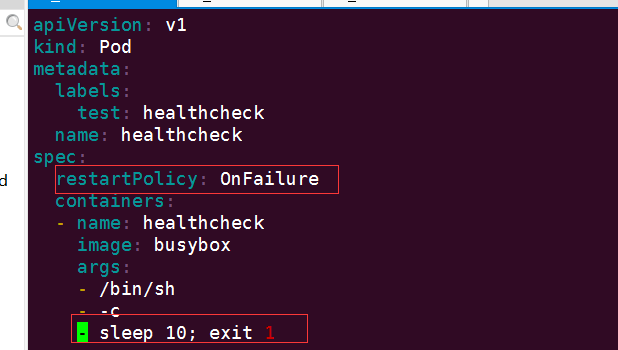


apiVersion: v1 kind: Pod metadata: labels: test: healthcheck name: healthcheck spec: restartPolicy: OnFailure containers: - name: healthcheck image: busybox args: - /bin/sh - -c - sleep 10; exit 1View Code
Pod 的 restartPolicy 設定為 OnFailure,預設為 Always。
sleep 10; exit 1 模擬容器啟動 10 秒後發生故障。
執行 kubectl apply 建立 Pod,命名為 healthcheck。

可看到容器當前已經重啟了 4 次。

在上面的例子中,容器程序返回值非零,Kubernetes 則認為容器發生故障,需要重啟。但有不少情況是發生了故障,但程序並不會退出。比如訪問 Web 伺服器時顯示 500 內部錯誤,可能是系統超載,也可能是資源死鎖,此時 httpd 程序並沒有異常退出,在這種情況下重啟容器可能是最直接最有效的解決方案,那我們如何利用 Health Check 機制來處理這類場景呢?
答案是 Liveness
2.Liveness探測
Liveness 探測讓使用者可以自定義判斷容器是否健康的條件。如果探測失敗,Kubernetes 就會重啟容器。
還是舉例說明,建立如下 Pod:
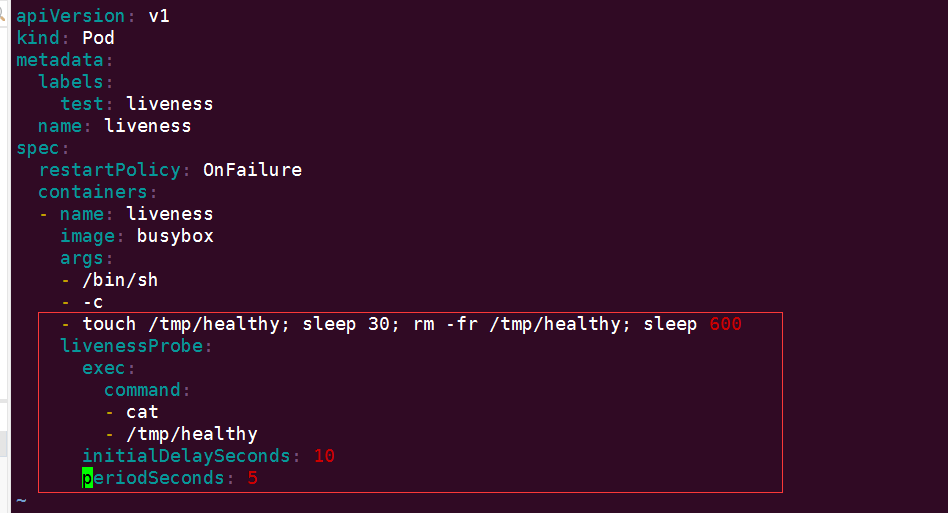
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness spec: restartPolicy: OnFailure containers: - name: liveness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -fr /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5View Code
啟動程序首先建立檔案 /tmp/healthy,30 秒後刪除,在我們的設定中,如果 /tmp/healthy 檔案存在,則認為容器處於正常狀態,反正則發生故障。
livenessProbe 部分定義如何執行 Liveness 探測:
-
探測的方法是:通過
cat命令檢查/tmp/healthy檔案是否存在。如果命令執行成功,返回值為零,Kubernetes 則認為本次 Liveness 探測成功;如果命令返回值非零,本次 Liveness 探測失敗。 -
initialDelaySeconds: 10指定容器啟動 10 之後開始執行 Liveness 探測,我們一般會根據應用啟動的準備時間來設定。比如某個應用正常啟動要花 30 秒,那麼initialDelaySeconds的值就應該大於 30。 -
periodSeconds: 5指定每 5 秒執行一次 Liveness 探測。Kubernetes 如果連續執行 3 次 Liveness 探測均失敗,則會殺掉並重啟容器。
下面建立 Pod liveness:

從配置檔案可知,最開始的 30 秒,/tmp/healthy 存在,cat 命令返回 0,Liveness 探測成功,這段時間 kubectl describe pod liveness 的 Events部分會顯示正常的日誌。
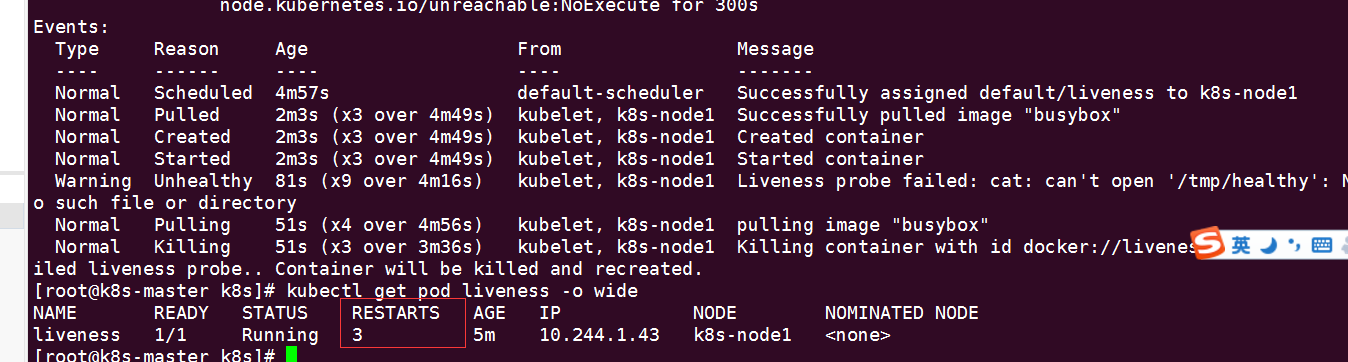
2m3s =123s 123s-30s(初始化時間)=93s 可以檢查三次,對應的RESTARTS次數 為3
3.Readiness探測
除了 Liveness 探測,Kubernetes Health Check 機制還包括 Readiness 探測。
使用者通過 Liveness 探測可以告訴 Kubernetes 什麼時候通過重啟容器實現自愈;Readiness 探測則是告訴 Kubernetes 什麼時候可以將容器加入到 Service 負載均衡池中,對外提供服務。
Readiness 探測的配置語法與 Liveness 探測完全一樣,下面是個例子:
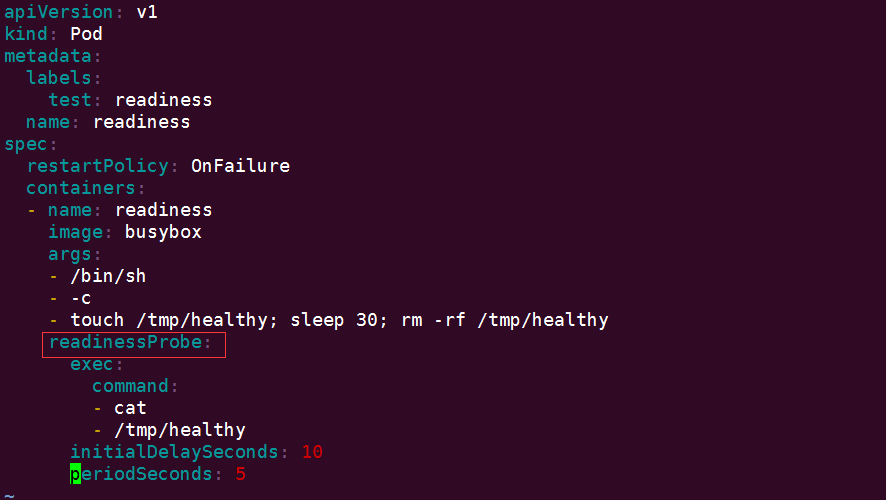
apiVersion: v1 kind: Pod metadata: labels: test: readiness name: readiness spec: restartPolicy: OnFailure containers: - name: readiness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5View Code
這個配置檔案只是將前面例子中的 liveness 替換為了 readiness,我們看看有什麼不同的效果。


Pod readiness 的 READY 狀態經歷瞭如下變化:
-
剛被建立時,
READY狀態為不可用。 -
15 秒後(initialDelaySeconds + periodSeconds),第一次進行 Readiness 探測併成功返回,設定
READY為可用。 -
30 秒後,
/tmp/healthy被刪除,連續 3 次 Readiness 探測均失敗後,READY被設定為不可用 STATUS變為Completed,而RESTARTS一直為0。
通過 kubectl describe pod readiness 也可以看到 Readiness 探測失敗的日誌。

下面對 Liveness 探測和 Readiness 探測做個比較:
-
Liveness 探測和 Readiness 探測是兩種 Health Check 機制,如果不特意配置,Kubernetes 將對兩種探測採取相同的預設行為,即通過判斷容器啟動程序的返回值是否為零來判斷探測是否成功。
-
兩種探測的配置方法完全一樣,支援的配置引數也一樣。不同之處在於探測失敗後的行為:Liveness 探測是重啟容器;Readiness 探測則是將容器設定為不可用,不接收 Service 轉發的請求。
-
Liveness 探測和 Readiness 探測是獨立執行的,二者之間沒有依賴,所以可以單獨使用,也可以同時使用。用 Liveness 探測判斷容器是否需要重啟以實現自愈;用 Readiness 探測判斷容器是否已經準備好對外提供服務。
4.Health Check在滾動更新中使用
對於多副本應用,當執行 Scale Up 操作時,新副本會作為 backend 被新增到 Service 的負責均衡中,與已有副本一起處理客戶的請求。考慮到應用啟動通常都需要一個準備階段,比如載入快取資料,連線資料庫等,從容器啟動到正真能夠提供服務是需要一段時間的。我們可以通過 Readiness 探測判斷容器是否就緒,避免將請求傳送到還沒有 ready 的 backend。
下面是示例應用的配置
重點關注 readinessProbe 部分。這裡我們使用了不同於 exec 的另一種探測方法 -- httpGet。Kubernetes 對於該方法探測成功的判斷條件是 http 請求的返回程式碼在 200-400 之間。
schema 指定協議,支援 HTTP(預設值)和 HTTPS。path 指定訪問路徑。port 指定埠。
上面配置的作用是:
-
容器啟動 10 秒之後開始探測。
-
如果
http://[container_ip]:8080/healthy返回程式碼不是 200-400,表示容器沒有就緒,不接收 Serviceweb-svc的請求。 -
每隔 5 秒再探測一次。
-
直到返回程式碼為 200-400,表明容器已經就緒,然後將其加入到
web-svc的負責均衡中,開始處理客戶請求。 -
探測會繼續以 5 秒的間隔執行,如果連續發生 3 次失敗,容器又會從負載均衡中移除,直到下次探測成功重新加入。
對於 http://[container_ip]:8080/healthy,應用則可以實現自己的判斷邏輯,比如檢查所依賴的資料庫是否就緒,示例程式碼如下:
