
機器學習的理論知識點總結
最近一邊看書,一邊梳理機器學習的知識點:
1. 線性迴歸
2.線性迴歸的損失函式(誤差的平方和)
3. 最小二乘法(手推導)
4.批量梯度下降法(學習率大小問題)
5.放縮scaling對梯度下降的影響
6.多元線性迴歸
7.邏輯斯蒂迴歸-二元分類
8.LR代價函式
9.神經網路
10.前向傳播和後向傳播
11.神經網路過程

12.模型選擇和交叉驗證
13.高偏差和高方差
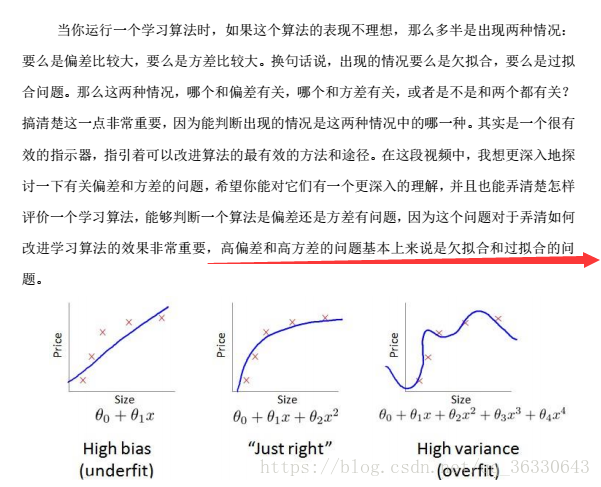
14.偏差和方差(欠擬合和過擬合)
15.學習率
16.模型評價 混淆矩陣 準確率和召回率 F1值,ROC曲線和auc的含義
17.無監督聚類 k-means 迭代演算法和過程 選擇聚類數的動機 聚類相似度和距離的度量 中心點隨機初始化 代價函式 容易陷入區域性最小值 解決辦法多執行幾次取loss最小的,降維 資料視覺化 PCA。
18.
相關推薦
機器學習的理論知識點總結
最近一邊看書,一邊梳理機器學習的知識點: 1. 線性迴歸 2.線性迴歸的損失函式(誤差的平方和) 3. 最小二乘法(手推導) 4.批量梯度下降法(學習率大小問題) 5.放縮scaling對梯度下降的影響 6.多元線性迴歸 7.邏輯斯蒂迴歸-二元分類 8.LR代價函
機器學習基本概念總結(轉載)
9.png png log images es2017 enter 08-18 機器學習 style 機器學習基本概念總結(轉載)
機器學習理論(一)——線性回歸
隨機 .cn 過程 小寫 找到 想想 每次 回歸 所在 (一)單變量線性回歸。 舉個例子來說,假如你要在北京的五環路租房,要預測房子的價格,其中一個比較顯著的特征就是房子的面積,根據不同的房間的面積來預測租金是多少。於是你就可以構建一個模型橫軸是房間面積,縱軸是租金
阿裏雲雲計算工程師ACP學習筆記--知識點總結
阿裏雲 acp Elastic Compute Server 是一種處理能力可彈性伸縮的計算服務。 CPU內存需要停機,帶寬不需要。垂直:帶寬 CPU 內存 水平:服務器Region 地域 Zone 可用區安全組, 允許包含跨可用區的實例 磁盤 只能掛在同一可用區
輕松入門機器學習之概念總結(二)
消息 目的 作者 固定 erp 效率 dev 常用 度量 歡迎大家前往雲加社區,獲取更多騰訊海量技術實踐幹貨哦~ 作者:許敏 接上篇:機器學習概念總結筆記(一) 8)邏輯回歸 logistic回歸又稱logistic回歸分析,是一種廣義的線性回歸分析模型,常用於數據挖掘
初識機器學習-理論篇(慕課筆記)
最好 框架 要求 它的 推薦系統 利用 評估 das 離散 什麽是機器學習 定義: 利用計算機從歷史數據中找出規律,並把這些規律用到對未來不確定場景的決策。 從數據中尋找規律 尋找規律:概率學 統計學統計學方法:抽樣 -> 統計 -> 假設檢驗隨著計算
《機器學習理論、方法及應用》研讀(1)
性能 能力 角度 怎樣 應用 環境 十年 外部表 過程 第一章 機器學習概述 機器學習的概念 學習:可以從不同角度對學習給出解釋,但是都包含了知識獲取和能力改善這兩個主要方面。因此給學習如下一般的解釋:學習是一個有特定目的的知識獲取和能力增長過程,其內在行為是獲得知識、積累
機器學習:理論知識
apriori 單身 遷移 learn 指標 -s onf 統計學 一行 一、混淆矩陣(Confusion matrix) 混淆矩陣也稱誤差矩陣,是表示精度評價的一種標準格式,用n行n列的矩陣形式來表示。具體評價指標有總體精度、制圖精度、用戶精度等,這些精度指標從不同的
吳恩達《機器學習》課程總結(7)正則化
額外 分享 哪些 TP 回歸 分享圖片 表現 例子 兩個 7.1過擬合的問題 訓練集表現良好,測試集表現差。魯棒性差。以下是兩個例子(一個是回歸問題,一個是分類問題) 解決辦法: (1)丟棄一些不能幫助我們正確預測的特征。可以使用工選擇保留哪些特征,或者使用一些模型選擇
吳恩達《機器學習》課程總結(15)異常檢測
是否 5.6 問題 com 結果 平移 分享 出現問題 計算過程 15.1問題的動機 將正常的樣本繪制成圖表(假設可以),如下圖所示: 當新的測試樣本同樣繪制到圖標上,如果偏離中心越遠說明越可能不正常,使用某個可能性閾值,當低於正常可能性閾值時判斷其為異常,然後做進一步的
sklearn 學習筆記-3 機器學習理論基礎
本章主要知識點: 過擬合和欠擬合的概念 模型的成本及成本函式的含義 評價一個模型的好壞的標準 學習曲線,以及用學習曲線來對模型進行診斷 通用模型優化方法 其他模型評價標準 ##3.1過擬合和欠擬合 過擬合就是模型能很好的擬合訓練樣
機器學習特徵工程總結
一、前言 資料清洗: 不可信的樣本去除 缺失值極多的欄位考慮去除 補齊缺失值 資料取樣:很多情況下,正負樣本是不均衡的,大多數模型對正負樣本是敏感的(比如LR) 正樣本>>負樣本,且量都挺大:下采樣 正樣本>>負
機器學習掌握知識點
一、人工智慧學習演算法分類 人工智慧演算法大體上來說可以分類兩類:基於統計的機器學習演算法(Machine Learning)和深度學習演算法(Deep Learning) 總的來說,在sklearn中機器學習演算法大概的分類如下: 1. 純演算法類 (1).迴歸演算法 (2).分類演算法&
常見機器學習演算法優缺點總結
一、樸素貝葉斯 1.1主要優點: 1)樸素貝葉斯模型發源於古典數學理論,有穩定的分類效率。 2)對小規模的資料表現很好,能個處理多分類任務,適合增量式訓練,尤其是資料量超出記憶體時,我們可以一批批的去增量訓練。 3)對缺失資料不太敏感,演算法也比較簡單,常用於文字分類
機器學習面試題總結(轉)
原文連結: https://blog.csdn.net/sinat_35512245/article/details/78796328 1.請簡要介紹下SVM。 SVM,全稱是support vector machine,中文名叫支援向量機。SVM是一個面向資料的分類演算法,它的目標是為確定一個
機器學習面試知識點之決策樹相關
決策樹面試知識點最全總結(一) 一:首先明確以下幾個基本問題: 1.決策樹是幹什麼用的? 一種最基本的分類與迴歸方法,因為實際應用中基本上全是用來分類,所以重點討論分類決策樹。 2.決策樹優缺點: 優點: 1)
機器學習概念,公式總結
一. 引言 1.機器學習是什麼 Arthur Samuel:在進行特定程式設計的情況下,給予計算機學習能力的領域。Tom Mitchell:一個程式被認為能從經驗E中學習,解決任務T,達到效能度量值P,當且僅當,有了經驗E後,經過P評判,程式在處理T時的效能有所提升
機器學習技法筆記總結(一)SVM系列總結及實戰
機器學技法筆記總結(一)SVM系列總結及實戰 1、原理總結 在機器學習課程的第1-6課,主要學習了SVM支援向量機。 SVM是一種二類分類模型。它的基本模型是在特徵空間中尋找間隔最大化的分離超平面的線性分類器。 (1)當訓練樣本線性可分時,通過硬間隔最大化,學習
不得不瞭解的機器學習面試知識點
機器學習崗位的面試中通常會對一些常見的機器學習演算法和思想進行提問,在平時的學習過程中可能對演算法的理論,注意點,區別會有一定的認識,但是這些知識可能不繫統,在回答的時候未必能在短時間內答出自己的認識,因此將機器學習中常見的原理性問題記錄下來,保持對各個機器學習演算法原理和特點的熟練度。 本文總結了機
關於機器學習的一些總結
以下是自己關於機器學習的一些知識點總結,主要滲透了自己對某些知識點的理解,涵蓋的面較廣,將會不定期地更新。若有理解不一致之處,望指明並相互交流。 1 SVM中常用的核函式有哪些?如何選擇相應的核函式? 常用的核函式有線性核,多項式核以及高斯核。 1.