
詳解python 3下文字檔案的編解碼
很多次遇到python 3下的檔案編碼,解碼問題,我這裡的平臺是mac,下面吐血搞一波。。
1. ASCII編碼:
字串是一種資料型別,但是,字串比較特殊的是還有一個編碼問題。因為計算機只能處理數字,如果要處理文字,就必須先把文字轉換為數字才能處理。最早的計算機在設計時採用8個位元(bit)作為一個位元組(byte),所以,一個位元組能表示的最大的整數就是255(二進位制11111111=十進位制255),如果要表示更大的整數,就必須用更多的位元組。比如兩個位元組可以表示的最大整數是65535,4個位元組可以表示的最大整數是4294967295。
由於計算機是美國人發明的,因此,最早只有127個字母被編碼到計算機裡,也就是大小寫英文字母、數字和一些符號,這個編碼表被稱為ASCII編碼,比如大寫字母A的編碼是65,小寫字母z的編碼是122。
2. Unicode編碼
Unicode把所有語言都統一到一套編碼裡,這樣就不會再有亂碼問題了。
Unicode標準也在不斷髮展,但最常用的是用兩個位元組表示一個字元(如果要用到非常偏僻的字元,就需要4個位元組)。現代作業系統和大多數程式語言都直接支援Unicode。
ASCII編碼和Unicode編碼的區別:ASCII編碼是1個位元組,而Unicode編碼通常是2個位元組。
3. UTF-8編碼
新的問題又出現了:如果統一成Unicode編碼,亂碼問題從此消失了。但是,如果你寫的文字基本上全部是英文的話,用Unicode編碼比ASCII編碼需要多一倍的儲存空間,在儲存和傳輸上就十分不划算。
所以,又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文字包含大量英文字元,用UTF-8編碼就能節省空間:
4. 檔案傳輸
在計算機記憶體中,統一使用Unicode編碼,當需要儲存到硬碟或者需要傳輸的時候,就轉換為UTF-8編碼。
用記事本編輯的時候,從檔案讀取的UTF-8字元被轉換為Unicode字元到記憶體裡,編輯完成後,儲存的時候再把Unicode轉換為UTF-8儲存到檔案:

瀏覽網頁的時候,伺服器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器:

所以你看到很多網頁的原始碼上會有類似的資訊,表示該網頁正是用的UTF-8編碼。
5. python 3 字串型別和 bytes 型別
字串
在最新的Python 3版本中,字串是以Unicode編碼的,也就是說,Python的字串支援多語言。
In [181]: print('包含中文的str')
包含中文的str
bytes
由於Python的字串型別是str,在記憶體中以Unicode表示,一個字元對應若干個位元組。如果要在網路上傳輸,或者儲存到磁碟上,就需要把str變為以位元組為單位的bytes。
Python對bytes型別的資料用帶b字首的單引號或雙引號表示:x = b'ABC'
要注意區分’ABC’和b’ABC’,前者是str,後者雖然內容顯示得和前者一樣,但bytes的每個字元都只佔用一個位元組。
(1)以Unicode表示的str通過encode()方法可以編碼為指定的bytes。例如:
In [182]: 'ABC'.encode('ascii')
Out[182]: b'ABC'
In [183]: '中文'.encode('utf-8')
Out[183]: b'\xe4\xb8\xad\xe6\x96\x87'
In [184]: '中文ABC'.encode('utf-8')
Out[184]: b'\xe4\xb8\xad\xe6\x96\x87ABC'
In [185]: '中文'.encode('ascii')
Traceback (most recent call last):
File "<ipython-input-185-76f41cd8dafa>", line 1, in <module>
'中文'.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
純英文的str可以用ASCII編碼為bytes,內容是一樣的,含有中文的str可以用UTF-8編碼為bytes。含有中文的str無法用ASCII編碼,因為中文編碼的範圍超過了ASCII編碼的範圍,Python會報錯。
(2)如果我們從網路或磁碟上讀取了位元組流,那麼讀到的資料就是bytes。要把bytes變為str,就需要用decode()方法:
In [193]: b'ABC'.decode('ascii')
Out[193]: 'ABC'
In [194]: b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
Out[194]: '中文'
(3)len()函式計算的是str的字元數,如果換成bytes,len()函式就計算位元組數
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
1箇中文字元經過UTF-8編碼後通常會佔用3個位元組,而1個英文字元只佔用1個位元組。
在操作字串時,我們經常遇到str和bytes的互相轉換。為了避免亂碼問題,應當始終堅持使用UTF-8編碼對str和bytes進行轉換。
Python原始碼也是一個文字檔案,所以,當你的原始碼中包含中文的時候,在儲存原始碼時,就需要務必指定儲存為UTF-8編碼。當Python直譯器讀取原始碼時,為了讓它按UTF-8編碼讀取,我們通常在檔案開頭寫上這兩行
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第二行註釋是為了告訴Python直譯器,按照UTF-8編碼讀取原始碼,否則,你在原始碼中寫的中文輸出可能會有亂碼。
4. 修改資料夾下的所有文字的編碼
(1)Python3 中,在字元引號前加‘b’,明確表示這是一個 bytes 型別的物件,實際上它就是一組二進位制位元組序列組成的資料,bytes 型別可以是 ASCII範圍內的字元和其它十六進位制形式的字元資料,但不能用中文等非ASCII字元表示。
In [195]: b'a'
Out[195]: b'a'
In [196]: b'\xe7\xa6\x85'
Out[196]: b'\xe7\xa6\x85'
In [197]: b'中文'
File "<ipython-input-197-241a368e5c3e>", line 1
b'中文'
^
SyntaxError: bytes can only contain ASCII literal characters.
(2)str 與 bytes 之間的轉換可以用 encode 和從decode 方法:
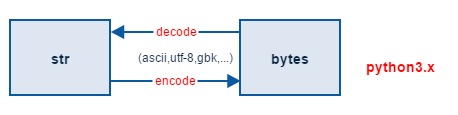
encode 負責字元到位元組的編碼轉換。預設使用 UTF-8 編碼準換。
In [198]: s = "Python之禪"
In [199]: s.encode()
Out[199]: b'Python\xe4\xb9\x8b\xe7\xa6\x85'
In [200]: s.encode("gbk")
Out[200]: b'Python\xd6\xae\xec\xf8'
decode 負責位元組到字元的解碼轉換,通用使用 UTF-8 編碼格式進行轉換。
In [201]: b'Python\xe4\xb9\x8b\xe7\xa6\x85'.decode()
Out[201]: 'Python之禪'
In [202]: b'Python\xd6\xae\xec\xf8'.decode("gbk")
Out[202]: 'Python之禪'
下面是一個修改一個資料夾下的所有文字問價為utf-8的編碼格式的例子:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 31 09:42:29 2018
@author: lilong
"""
import chardet
import os
class Unicode(object):
def __init__(self):
self.file_path='/Users/lilong/Desktop/coding_test/'
self.flag=0
def readFile(self,file_path):
with open(file_path, 'rb') as f: # 這裡讀檔案判斷編碼時必須是‘rb’的格式
filecontent = f.read()
return filecontent
def converCode(self,filepath):
file_con = self.readFile(filepath)
result=chardet.detect(file_con) # 判斷檔案編碼
print('result:',result)
if self.flag==0:
if result['encoding'] == 'GB2312': # GBK是GB2312的擴充套件
unicode_raw = file_con.decode('GB2312') # unicode_raw是位元組流
unicode_done= unicode_raw.encode('utf-8') # unicode_done是位元組流
#print(str(unicode_done))
with open(filepath, 'wb') as f: # 這裡寫檔案時必須時‘wb’的格式
f.write(unicode_done)
else:
pass
def listDirFile(self,file_path):
list_ = os.listdir(file_path)
for ll in list_:
filepath = os.path.join(file_path, ll)
if os.path.isdir(filepath):
self.listDirFile(filepath)
else:
print('ll:',ll)
self.converCode(filepath)
def check(self):
self.flag=1
self.listDirFile(self.file_path)
def start(self):
self.listDirFile(self.file_path)
self.check()
# 例項化
tt=Unicode()
tt.start()
執行:
ll: .DS_Store
result: {'encoding': 'Windows-1252', 'confidence': 0.73, 'language': ''}
ll: 2.txt
result: {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
ll: 1.txt
result: {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
ll: .DS_Store
result: {'encoding': 'Windows-1252', 'confidence': 0.73, 'language': ''}
ll: 2.txt
result: {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
ll: 1.txt
result: {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
.DS_Store檔案是我的mac系統下自動生成的,在這裡不影響說明問題。