
Keepalived高可用叢集。
Keepalived高可用叢集
Keepalived介紹
Keepalived軟體起初是專門為LVS負載均衡軟體設計的,用來管理並監控LVS集群系統中各個服務節點的狀態,後來又加入了可以實現高可用的VRRP功能。因此,Keepalived除了能夠管理LVS軟體外,還可以作為其他服務(例如:Nginx,Haproxy,MySQL等)的高可用解決方案軟體。
Keepalived軟體主要是通過VRRP協議實現高可用功能的。VRRP是Virtual Router Redundancy Protocol(虛擬路由器冗餘協議)的縮寫,VRRP出現的目的就是為了解決靜態路由單點故障問題的,他能夠保證當個別節點宕機時,整個網路可以不間斷地執行。所以,Keepalived一方面具有配置管理LVS的功能,同時還具有對LVS下面節點進行健康檢查的功能,另一方面也可實現系統網路服務的高可用功能。
Keepalived軟體的官方站點是http://www.keepalived.org
Keepalived服務的三個重要功能
(1)管理LVS負載均衡軟體
早期的LVS軟體,需要通過命令列或指令碼實現管理,並且沒有針對LVS節點的健康檢查功能。為了解決LVS的這些使用不便問題,Keepalived誕生了,可以說,Keepalived軟體起初是專為解決LVS的問題而誕生的。因此,Keepalived和LVS的感情很深,他們的關係如同夫妻一樣,可以緊密地結合,愉快地工作。Keepalived可以通過讀取自身的配置檔案,實現通過更底層的介面直接管理LVS的配置以及控制服務的啟動,停止功能,這使得LVS的應用更加簡單方便了。
(2)實現對LVS叢集節點健康檢查功能(healthcheck)
前文已講過,Keepalived可以通過在自身的Keepalived.conf檔案裡配置LVS的節點IP和相關引數實現對LVS的直接管理;除此之外,當LVS叢集中的某一個甚至是幾個節點伺服器同時發生故障無法提供服務時,Keepalived服務會自動將失效的節點伺服器從LVS的正常轉發佇列中清除出去,並將請求排程到別的正常節點伺服器上,從而保證終端使用者的訪問不受影響;當故障的節點伺服器被修復以後,Keepalived服務又會自動地把它們加入到正常轉發佇列中,對客戶提供服務。
(3)作為系統網路服務的高可用功能(failover)
Keepalived可以實現任意兩臺主機之間,例如Master和Backup主機之間的故障轉移和自動切換,這個主機可以是普通的不能停機的業務伺服器,也可以是LVS負載均衡,Nginx反向代理這樣的伺服器。
Keepalived高可用功能實現的簡單原理為,兩臺主機同時安裝好Keepalived軟體並啟動服務,開始正常工作時,由角色為Master的主機獲得所有資源並對使用者提供服務,角色為Backup的主機作為Master主機的熱備;當角色為Master的主機失效或出現故障時,角色為Backup的主機將自動接管Master主機的所有工作,包括接管VIP資源及相應資源服務;而當角色為Master的主機故障修復後,又會自動接管回它原來處理的工作,角色為Backup的主機則同時釋放Master主機失效時它接管的工作,此時,兩臺主機將恢復到最初啟動時各自的原始角色及工作狀態。
Keepalived高可用故障切換轉移原理
Keepalived高可用服務之間的故障切換轉移,是通過VRRP(Virtual Router Redundancy Protocol,虛擬路由器冗餘協議)來實現的。
在Keepalived服務正常工作時,主Master節點會不斷地向備節點發送(多播的方式)心跳訊息,用以告訴備Backup節點自己還活著,當主Master節點發生故障時,就無法傳送心跳訊息,備節點也就因此無法繼續檢測到來自主Master節點的心跳了,於是呼叫自身的接管程式,接管主Master節點的IP資源及服務。而當主Master節點恢復時,備Backup節點又會釋放主節點故障時自身接管的IP資源及服務,恢復到原來的備用角色。
那麼,什麼是VRRP呢?
VRRP,全稱Virtual Router Redundancy Protocol,中文名為虛擬路由冗餘協議,VRRP的出現就是為了解決靜態路由的單點故障問題,VRRP是通過一種競選機制來將路由的任務交給某臺VRRP路由器的。VRRP早期是用來解決交換機,路由器等裝置單點故障的,下面是交換,路由的Master和Backup切換原理描述,同樣適用於Keepalived的工作原理。
在一組VRRP路由器叢集中,有多臺物理VRRP路由器,但是這多臺物理的機器並不是同時工作的,而是由一臺稱為Master的機器負責路由工作,其他的機器都是Backup。Master角色並非一成不變的,VRRP會讓每個VRRP路由參與競選,最終獲勝的就是Master。獲勝的Master有一些特權,比如擁有虛擬路由器的IP地址等,擁有系統資源的Master負責轉發傳送給閘道器地址的包和響應ARP請求。
VRRP通過競選機制來實現虛擬路由器的功能,所有的協議報文都是通過IP多播(Multicast)包(預設的多播地址224.0.0.18)形式傳送的。虛擬路由器由VRID(範圍0-225)和一組IP地址組成,對外表現為一個周知的MAC地址:00-00-5E-00-01-{VRID}。所以,在一個虛擬路由器中,不管誰是Master,對外都是相同的MAC和IP(稱之為VIP)。客戶端主機並不需要因Master的改變而修改自己的路由配置。對他們來說,這種切換是透明的。
在一組虛擬路由器中,只有作為Master的VRRP路由器會一直髮送VRRP廣播包(VRRP Advertisement messages),此時Backup不會搶佔Master。當Master不可用時,Backup就收不到來自Master的廣播包了,此時多臺Backup中優先順序最高的路由器會搶佔為Master。這種搶佔是非常快速的(可能只有1秒甚至更少),以保證服務的連續性。出於安全性考慮,VRRP資料包使用了加密協議進行了加密。
VRRP通訊原理
1.VRRP也就是虛擬路由冗餘協議,它的出現就是為了解決靜態路由的單點故障。
2.VRRP是通過一種競選協議機制來將路由任務交給某臺VRRP路由器的。
3.VRRP用IP多播的方式(預設多播地址(224.0.0.18))實現高可用之間通訊。
4.工作時主節點發包,備節點接包,當備節點接收不到主節點發的資料包的時候,就啟動接管程式接管主節點的資源。備節點可以有多個,通過優先順序競選,但一般Keepalived系統運維工作中都是一對。
5.VRRP使用了加密協議加密資料,但Keepalived官方目前還是推薦用明文的方式配置認證型別和密碼。
Keepalived服務的工作原理
Keepalived高可用之間是通過VRRP進行通訊的,VRRP是通過競選機制來確定主備的,主的優先順序高於備,因此,工作時主會優先獲得所有的資源,備節點處於等待狀態,當主掛了的時候,備節點就會接管主節點的資源,然後頂替主節點對外提供服務。
在Keepalived服務之間,只有作為主的伺服器會一直髮送VRRP廣播包,告訴備它還活著,此時備不會搶佔主,當主不可用時,即備監聽不到主傳送的廣播包時,就會啟動相關服務接管資源,保證業務的連續性。接管速度最快可以小於1秒。
Keepalived高可用單例項服務搭建
虛擬機器主從伺服器各新增一塊網絡卡並開機配置網絡卡
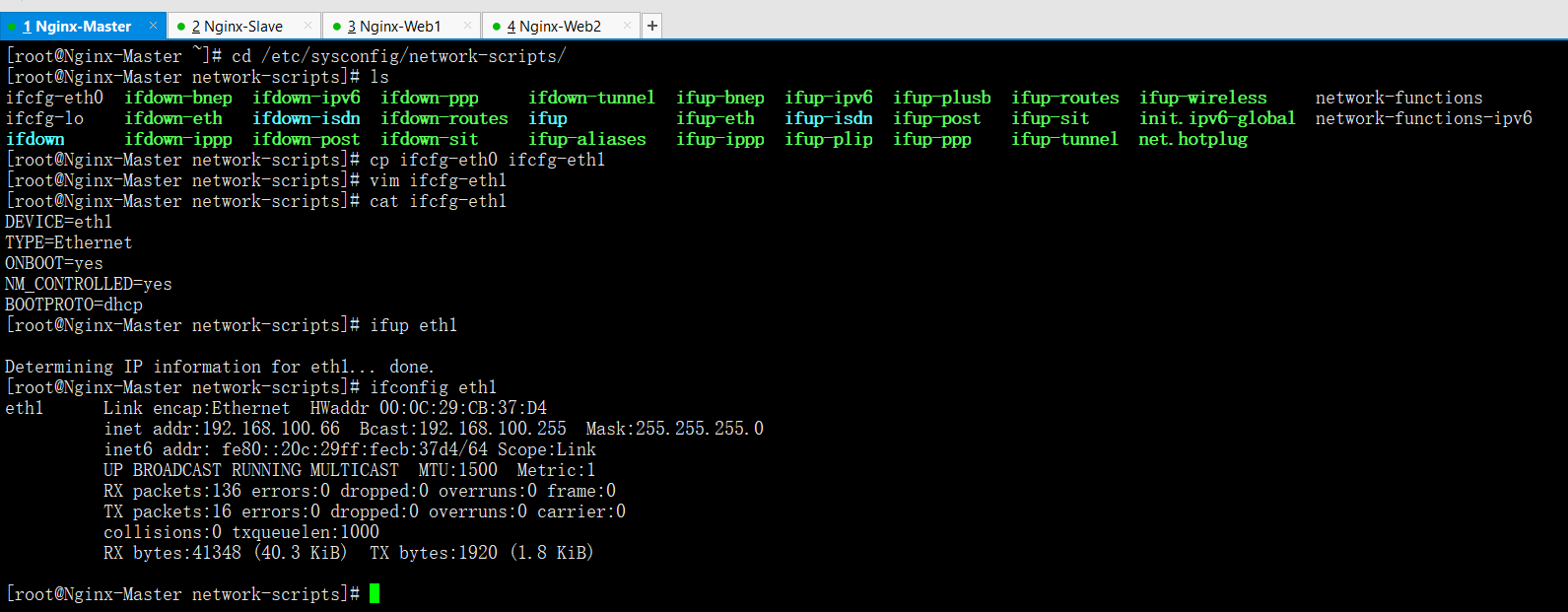
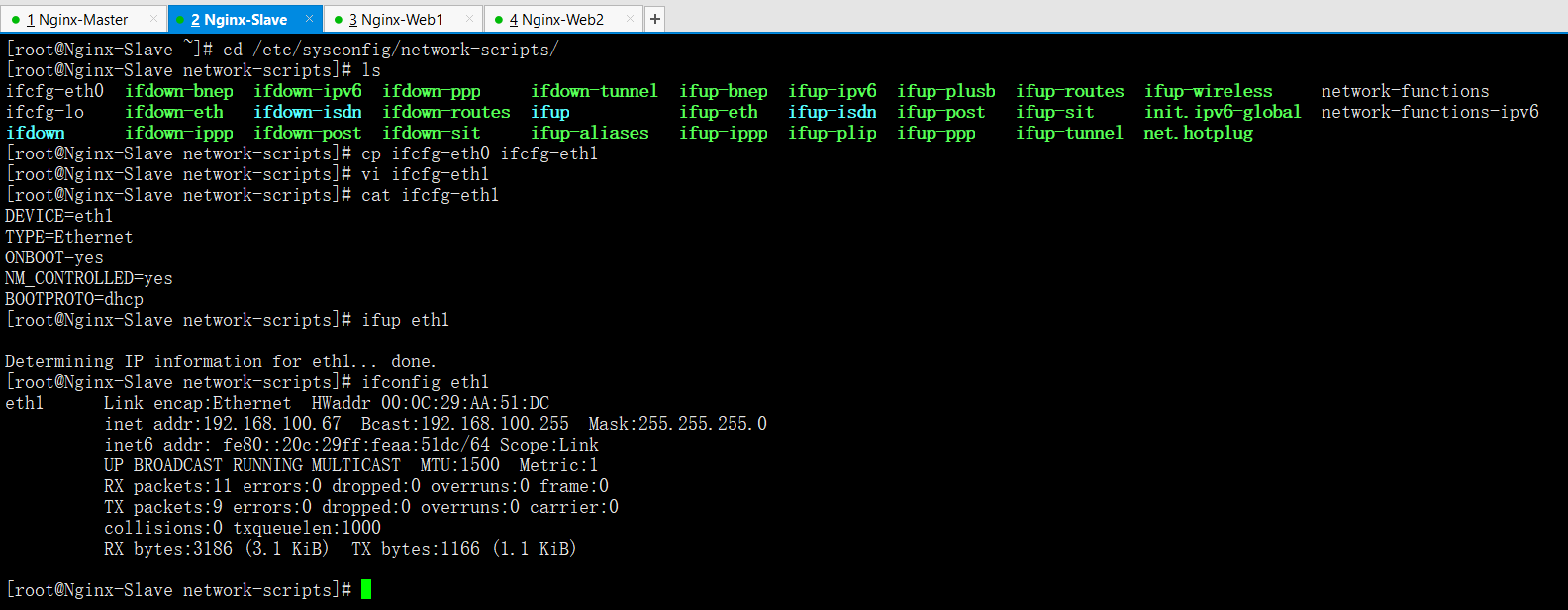
cd /etc/sysconfig/network-scripts/
cp ifcfg-eth0 ifcfg-eth1
vim ifcfg-eth1 --->把網絡卡名換成eth1即可
硬體環境準備
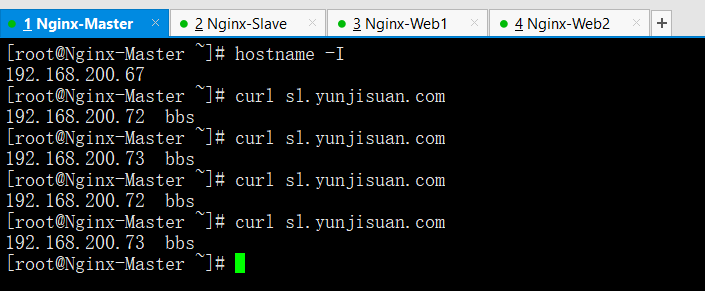
準備4臺VM虛擬機器,兩臺用來做Keepalived服務,兩臺做測試的Web節點
Nginx-Master IP:192.168.200.67 --->Keepalived主伺服器(Nginx主負載均衡)
Nginx-Slave IP:192.168.200.71 --->Keepalived從伺服器(Nginx從負載均衡)
Nginx-WEB1 IP:192.168.200.72 --->WEBA節點
Nginx-WEB2 IP:192.168.200.73 --->WEBB節點
安裝Keepalived軟體
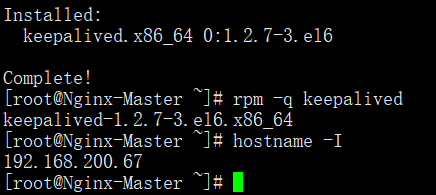
主從Nginx負載均衡都需要安裝Keepalived軟體
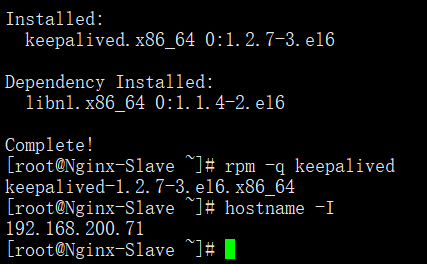
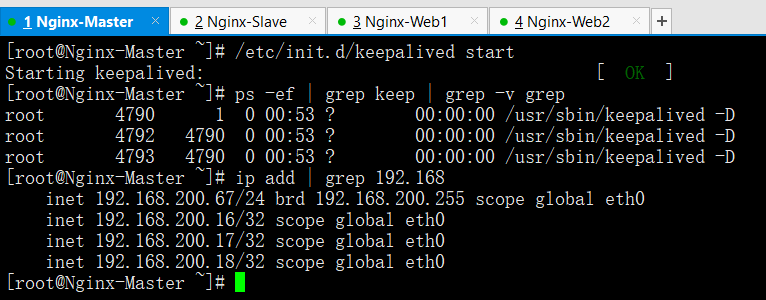
啟動Keepalived服務並檢查
啟動後有3個Keepalived程序表示安裝正確
預設情況會啟動三個VIP地址,這裡從Nginx就不測試了
Keepalived主配置檔案
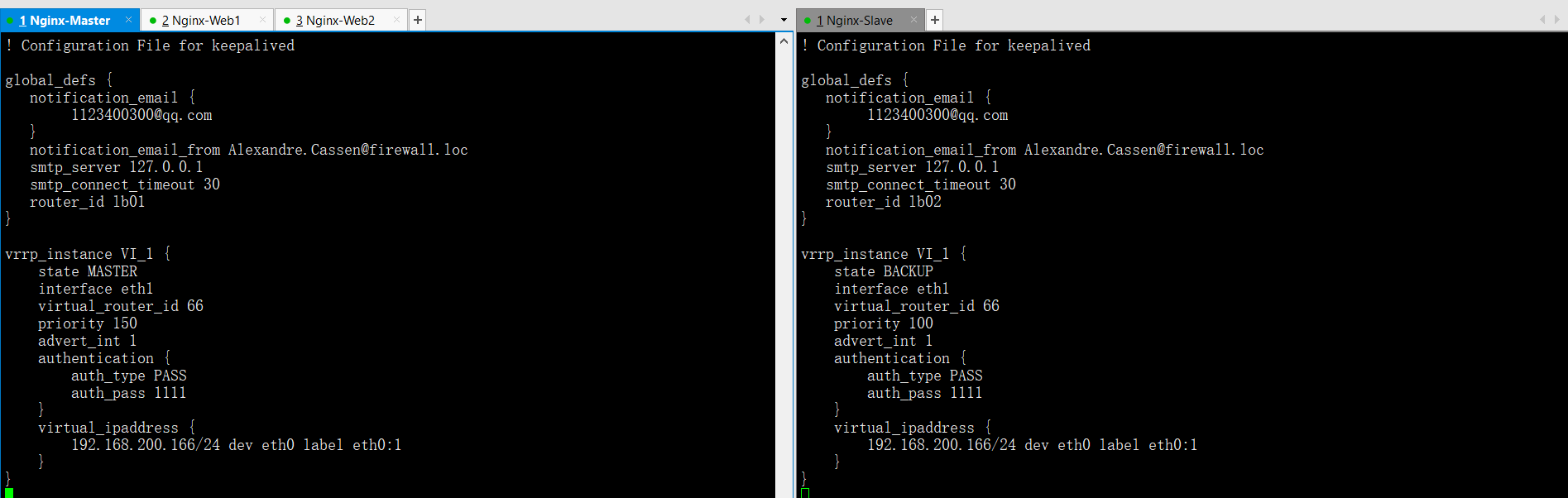
! Configuration File for keepalivedglobal_defs {notification_email {[email protected].com}notification_email_from Alexandre.[email protected].locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id lb01}vrrp_instance VI_1 {state MASTERinterface eth1virtual_router_id 66priority 150advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.166/24 dev eth0 label eth0:1}}
主配置檔案基本改動
[email protected].com --->郵箱隨便寫smtp_server 127.0.0.1 --->郵件伺服器IProuter_id lb01 --->lb代表負載均衡,不能和其他Keepalived節點相同(全域性唯一)vrrp_instance VI_1 { --->例項名字為VI_1,相同例項的備節點名字要和這個相同state MASTER --->狀態為MASTER,備節點狀態需要為BACKUPinterface eth1 --->通訊(心跳)介面為eth1,此引數備節點設定和主節點相同virtual_router_id 66 --->例項ID為66,要和備節點相同priority 150 --->優先順序為150,備節點的優先順序必須比此數字低,一般為100advert_int 1 --->通訊檢查間隔時間1秒,不需要改動auth_type PASS --->PASS認證型別,此引數備節點設定和主節點相同,用預設的就可以auth_pass 1111 --->密碼1111,此引數備節點設定和主節點相同,用預設的就可以192.168.200.166/24 dev eth0 label eth0:1--->VIP地址,dev繫結的意思,label別名為eth0:1,此引數備節點設定和主節點相同
Keepalived從配置檔案
! Configuration File for keepalivedglobal_defs {notification_email {[email protected].com}notification_email_from Alexandre.[email protected].locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id lb02}vrrp_instance VI_1 {state BACKUPinterface eth1virtual_router_id 66priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.166/24 dev eth0 label eth0:1}}
從配置檔案基本改動
router_id lb02 --->此引數和lb01 MASTER不同vrrp_instance VI_1 { --->lb01 MASTER相同state BACKUP --->此引數和lb01 MASTER不同interface eth1 --->和lb01 MASTER相同virtual_router_id 66 --->和lb01 MASTER相同priority 100 --->此引數和lb01 MASTER不同
配置檔案引數詳解
第1行是註釋,!開頭和#號開發一樣,都是註釋。第2行是空行。第3~8行是定義服務故障報警的Email地址。作用是當服務發生切換或RS節點等有故障時,發報警郵件。這幾行是可選配置,notification_email指定在Keepalived發生事件時,需要傳送的Email地址,可以有多個,每行一個。第9行是指定傳送郵件的傳送人,即發件人地址,也是可選的配置。第10行smtp_server指定傳送郵件的smtp伺服器,如果本機開啟了sendmail或postfix,就可以使用上面預設配置實現郵件傳送,也是可選配置。第11行smtp_connect_timeout是連線smtp的超時時間,也是可選配置。注意:第4~11行所有和郵件報警相關的引數均可以不配,在實際工作中會將監控的任務交給更加擅長監控報警的Nagios或Zabbix軟體。第12行是Keepalived伺服器的路由標識(router_id).在一個區域網內,這個標識(router_id)應該是唯一的。大括號“{}”。用來分隔區塊,要成對出現。如果漏寫了半個大括號,Keepalived執行時,不會報錯,但也不會得到預期的結果。另外,由於區塊間存在多層巢狀關係,因此很容易遺漏區塊結尾處的大括號,要特別注意。第15行表示定義一個vrrp_instance例項,名字是VI_1,每個vrrp_instance例項可以認為是Keepalived服務的一個例項或者作為一個業務服務,在Keepalived服務配置中,這樣的vrrp_instance例項可以有多個。注意,存在於主節點中的vrrp_instance例項在備節點中也要存在,這樣才能實現故障切換接管。第16行state MASTER表示當前例項VI_1的角色狀態,當前角色為MASTER,這個狀態只能有MASTER和BACKUP兩種狀態,並且需要大寫這些字元。其中MASTER為正式工作的狀態,BACKUP為備用的狀態。當MASTER所在的伺服器故障或失效時,BACKUP所在的伺服器會接管故障的MASTER繼續提供服務。第17行interface為網路通訊介面。為對外提供服務的網路介面,如eth0,eth1。當前主流的伺服器都有2~4個網路介面,在選擇服務介面時,要搞清楚了。第18行virtual_router_id為虛擬路由ID標識,這個標識最好是一個數字,並且要在一個keepalived.conf配置中是唯一的。但是MASTER和BACKUP配置中相同例項的virtual_router_id又必須是一致的,否則將出現腦裂問題。第19行priority為優先順序,其後面的數值也是一個數字,數字越大,表示例項優先順序越高。在同一個vrrp_instance例項裡,MASTER的優先順序配置要高於BACKUP的。若MASTER的priority值為150,那麼BACKUP的priority必須小於150,一般建議間隔50以上為佳,例如:設定BACKUP的priority為100或更小的數值。第20行advert_int為同步通知間隔。MASTER與BACKUP之間通訊檢查的時間間隔,單位為秒,預設為1.第21~24行authentication為許可權認證配置。包含認證型別(auth_type)和認證密碼(auth_pass)。認證型別有PASS(Simple Passwd(suggested)),AH(IPSEC(not recommended))兩種,官方推薦使用的型別為PASS。驗證密碼為明文方式,最好長度不要超過8個字元,建議用4位數字,同一vrrp例項的MASTER與BACKUP使用相同的密碼才能正常通訊。第25 ~ 29 行virtual_ipaddress為虛擬IP地址。可以配置多個IP地址,每個地址佔一行,配置時最好明確指定子網掩碼以及虛擬IP繫結的網路介面。否則,子網掩碼預設是32位,繫結的介面和前面的interface引數配置的一致。注意,這裡的虛擬IP就是在工作中需要和域名繫結的IP,即和配置的高可用服務監聽的IP要保持一致!
單例項主備模式Keepalived配置檔案對比
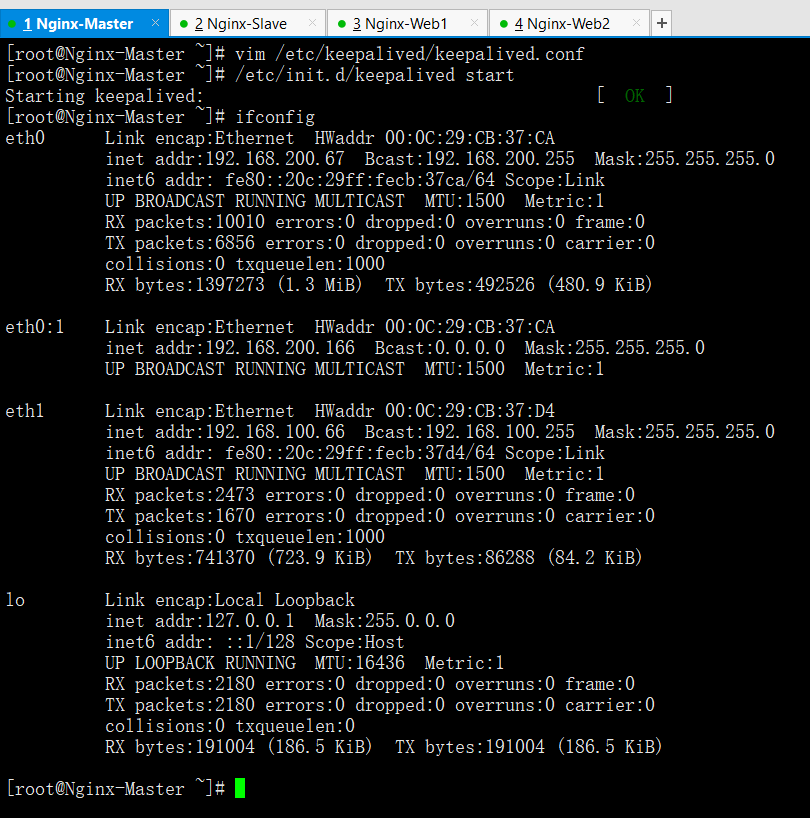
配置完成後,啟動Keepalived服務
/etc/init.d/keepalived start
這時候發現主伺服器有eth0:1而從沒有,這就代表成功了
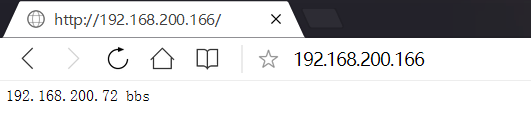
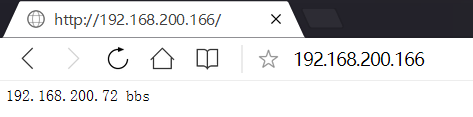
用主漂的IP進行wdinows頁面測試
192.168.200.166
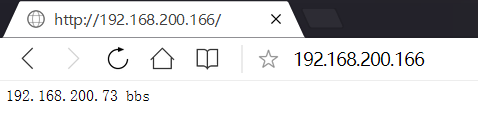
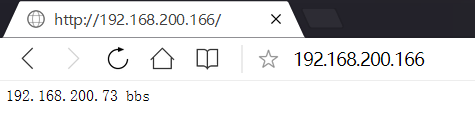
用從漂的IP進行wdinows頁面測試
192.168.200.166
Keepalived高可用多例項服務搭建
多例項就是把原先的主變成備,原先的備變成主,配置詳解請看上文
原先的備配置檔案(現在的主)
! Configuration File for keepalivedglobal_defs {notification_email {[email protected].com}notification_email_from Alexandre.[email protected].locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id lb02}vrrp_instance VI_1 {state BACKUPinterface eth1virtual_router_id 66priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.166/24 dev eth0 label eth0:1}}vrrp_instance VI_2 {state MASTERinterface eth1virtual_router_id 68priority 150advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.188/24 dev eth0 label eth0:2}}
原先的主配置檔案(現在的備)
! Configuration File for keepalivedglobal_defs {notification_email {[email protected].com}notification_email_from Alexandre.[email protected].locsmtp_server 127.0.0.1smtp_connect_timeout 30router_id lb01}vrrp_instance VI_1 {state MASTERinterface eth1virtual_router_id 66priority 150advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.166/24 dev eth0 label eth0:1}}vrrp_instance VI_2 {state BACKUPinterface eth1virtual_router_id 68priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.188/24 dev eth0 label eth0:2}}
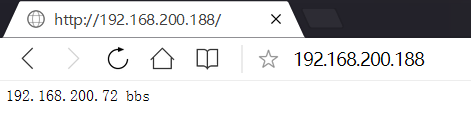
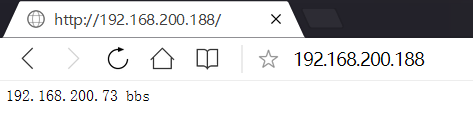
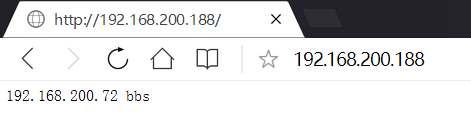
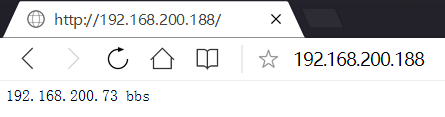
多例項主測試階段
多例項備測試階段
Keepalived高可用伺服器的“裂腦”問題
什麼是裂腦
由於某些原因,導致兩臺高可用伺服器對在指定時間內,無法檢測到對方的心跳訊息,各自取得資源及服務的所有權,而此時的兩臺高可用伺服器對都還活著並在正常執行,這樣就會導致同一個IP或服務在兩端同時存在而發生衝突,最嚴重的是兩臺主機佔用同一個VIP地址,當用戶寫入資料時可能會分別寫入到兩端,這可能會導致伺服器兩端的資料不一致或造成資料丟失,這種情況就被稱為裂腦。
導致裂腦發生的原因
高可用伺服器對之間心跳線鏈路發生故障,導致無法正常通訊。
心跳線壞了(包括斷了,老化)
網絡卡及相關驅動壞了,IP配置及衝突問題(網絡卡直連)。
心跳線間連線的裝置故障(網絡卡及交換機)
仲裁的機器出問題(採用仲裁的方案)
高可用伺服器上開啟了iptables防火牆阻擋了心跳訊息傳輸
高可用伺服器上心跳網絡卡地址等資訊配置不正確,導致傳送心跳失敗。
其他服務配置不當等原因,如心跳方式不同,心跳廣播衝突,軟體BUG等
重點提示
Keepalived配置裡同一VRRP例項如果virtual_router_id兩端引數配置不一致,也會導致裂腦問題發生。
解決裂腦的常見方案
同時使用序列電纜和乙太網電纜連線,同時用兩條心跳線路,這樣一條線路壞了,另一個還是好的,依然能傳送心跳訊息。
當檢測到裂腦時強行關閉一個心跳節點(這個功能需特殊裝置支援,如Stonith,fence)。相當於備節點接收不到心跳訊息,通過單獨的線路傳送關機命令關閉主節點的電源。
做好對裂腦的監控報警(如郵件及手機簡訊等或值班),在問題發生時人為第一時間介入仲裁,降低損失。例如,百度的監控報警簡訊就有上行和下行的區別。報警資訊傳送到管理員手機上,管理員可以通過手機回覆對應數字或簡單的字串操作返回給伺服器,讓伺服器根據指令自動處理相應故障,這樣解決故障的時間更短。
當然,在實施高可用方案時,要根據業務實際需求確定是否能容忍這樣的損失。對於一般的網站常規業務,這個損失是可容忍的。
作為網際網路應用伺服器的高可用,特別是前端Web負載均衡器的高可用,裂腦的問題對普通業務的影響是可以忍受的,如果是資料庫或者儲存的業務,一般出現裂腦問題就非常嚴重了。因此,可以通過增加冗餘心跳線路來避免裂腦問題的發生,同時加強對系統的監控,以便裂腦發生時人為快速介入解決問題。
如果開啟防火牆,一定要讓心跳訊息通過,一般通過允許IP段的形式解決。
可以拉一條乙太網網線或者串列埠線作為主被節點心跳線路的冗餘。
開發檢測程式通過監控軟體(例如Nagios)檢測裂腦。
生產場景檢測裂腦故障的一些思路
1)簡單判斷的思想:只要備節點出現VIP就報警,這個報警有兩種情況,一是主機宕機了備機接管了;二是主機沒宕,裂腦了。不管屬於哪個情況,都進行報警,然後由人工檢視判斷及解決。
2)比較嚴謹的判斷:備節點出現對應VIP,並且主節點及對應服務(如果能遠端連線主節點看是否有VIP就更好了)還活著,就說明發生裂腦了。