
Highcharts中處理座標軸資料過多的問題
昨天專案中遇到了highcharts這個元件,這次是對它記憶尤深,給我卡了一天,第一個問題就是在座標軸資料過多的時候,highcharts元件會自動調整座標軸的刻度間隔,好是好,但是我遇到的是它存在隨機性,在我的專案中,如圖
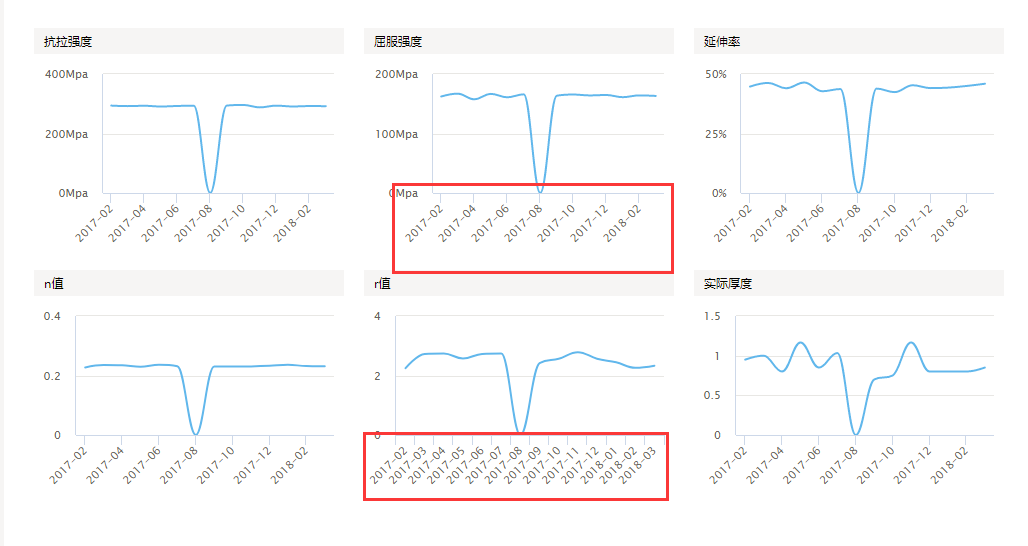
而且每次出現的都是不固定的,有時候是這兩個,有時候是那兩個,而且看了後臺資料也沒問題,判斷之後應該就是這個元件顯示資料問題,經過多次嘗試,最後經過萬能的百度,查到這個元件有個屬性tickInterval,就是它可以設定刻度間隔,我把每個X軸的這個屬性都設定成2之後,頁面就顯示正常了,如圖
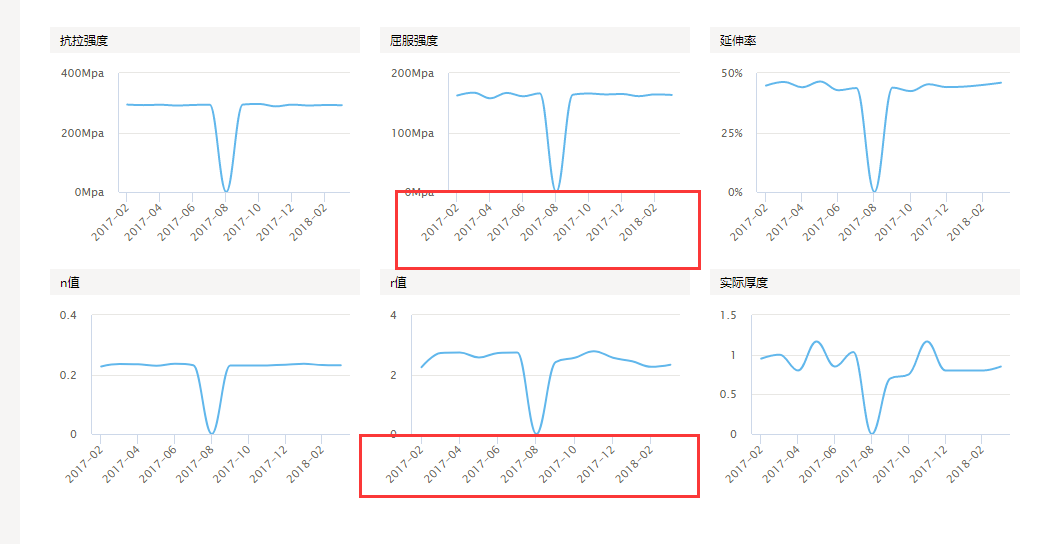
終於是解決了這個費腦子的問題。但是在測試過程中,又發現了一個問題,如圖
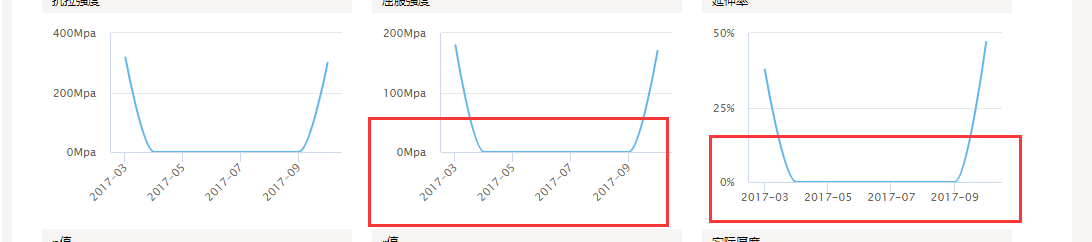
當資料少的時候,這個元件在座標軸上又出現文字排列方向問題,又是經過了強大的百度之後,發現了這個元件另外一個屬性rotation

兩個屬性完美解決了在我的專案中這個元件帶來的問題。最後總結一句話,元件好用,也好迷。
相關推薦
Highcharts中處理座標軸資料過多的問題
昨天專案中遇到了highcharts這個元件,這次是對它記憶尤深,給我卡了一天,第一個問題就是在座標軸資料過多的時候,highcharts元件會自動調整座標軸的刻度間隔,好是好,但是我遇到的是它存在隨機性,在我的專案中,如圖 而且每次出現的都是不固定的,有時候是這兩個,有時候是那兩個,而且看了
03 -2 numpy與pandas中處理丟失資料的理解與例項
引入三劍客 import numpy as np import pandas as pd from pandas import Series,DataFrame 處理丟失資料 1.有兩種丟失資料: None: Python自帶的資料型別 不能參與到任何計算中
微信小程式-中處理json資料 (從json資料中提取想要的值 將變數json字串轉成json物件)
1、新增依賴 <dependency> <groupId>net.sf.json-lib</groupId> <artifactId>jso
在JavaScript中處理JSON資料 jquery js 定義 json 格式
1.JSON(JavaScript Object Notation)一種簡單的資料格式,比xml更輕巧。JSON是JavaScript原生格式,這意味著在JavaScript中處理JSON資料不需要任何特殊的API或工具包。 JSON的規則很簡單:物件是一個無序的“‘名稱:值'對”集合
關於HighCharts中餅圖資料標籤顏色與圖形顏色一致問題的解決
之前一直用的百度的Echarts但是他沒有3D的餅圖所以今天用到HighCharts中的3D餅圖,但是發現,餅圖的資料標籤顏色屬性中的color是string型別,而不是array型別的,說明無法跟隨餅圖的顏色來進行著色,這就很坑了,在網上找了很多的解決方法,都是在 for
陣列和字典的writeToFile方法——在專案開發中處理網路資料的時候,可以把請求獲得的網路資料儲存為plist檔案,這樣更方便開發
在專案開發中處理網路資料的時候,可以把請求獲得的網路資料儲存為plist檔案,這樣更方便開發,下面是程式碼 //路徑(可以隨便找個資料夾
scala中處理json資料
import net.sf.json.JSONObject object Json { def main(args: Array[String]): Unit = { val str2 = "{\"et\":\"kanqiu_client_join\",\"vtm\":1435898329434
MySQL中sleep線程過多的處理方法
rec 連接超時 服務 一行 client out char* mysql連接 測試 先說具體方法: 先在MySQL中操作 set global wait_timeout = 60; set global interactive_timeout = 60; 然後在配置
由散列表到BitMap的概念與應用(三):面試中的海量資料處理
一道面試題 在面試軟體開發工程師時,經常會遇到海量資料排序和去重的面試題,特別是大資料崗位。 例1:給定a、b兩個檔案,各存放50億個url,每個url各佔64位元組,記憶體限制是4G,找出a、b檔案共同的url? 首先我們最常想到的方法是讀取檔案a,建立雜湊表,然後再讀取檔案b,遍歷檔
03 -2 numpy與pandas中isnull()、notnull()、dropna()、fillna()處理丟失資料的理解與例項
引入三劍客 import numpy as np import pandas as pd from pandas import Series,DataFrame 處理丟失資料 1.有兩種丟失資料: None: Python自帶的資料型別 不能參與到任何計算中
JMeter中返回Json資料的處理方法
Json 作為一種資料交換格式在網路開發,特別是 Ajax 與 Restful 架構中應用的越來越廣泛。而 Apache 的 JMeter 也是較受歡迎的壓力測試工具之一,但是它本身沒有提供對於 Js
機器學習中不平衡資料的處理方式
https://blog.csdn.net/pipisorry/article/details/78091626 不平衡資料的場景出現在網際網路應用的方方面面,如搜尋引擎的點選預測(點選的網頁往往佔據很小的比例),電子商務領域的商品推薦(推薦的商品被購買的比例很低),信用卡欺詐檢測,網路攻擊識別
資料庫讀取原始資料插入新表中,對處理原始資料的原則總結
在讀取原始資料的時候會有可能屬性名的名字與要建立的表的名字不符,這個時候就要為讀取到的資料重新命名屬性名。 如果資料中存在中文,還要宣告資料庫的編碼。 在原始表中可能會有重複資料,需要事先將重複資料進行刪除,然後再做其他處理。 在設定主鍵的時候會發現有些資料的主鍵相同,但是其他屬性值不同,需要對已經插入
SpringMvc中對json資料的處理
1、使用@ResponseBody實現資料輸出 @ResponseBody的作用: 將標註此註解的處理方法的返回值結果直接寫入HTTP ResponseBody (Re
JMeter中返回Json資料的處理方法(轉)
Json 作為一種資料交換格式在網路開發,特別是 Ajax 與 Restful 架構中應用的越來越廣泛。而 Apache 的 JMeter 也是較受歡迎的壓力測試工具之一,但是它本身沒有提供對於 Json&nb
從Hadoop框架與MapReduce模式中談海量資料處理 含淘寶技術架構
從hadoop框架與MapReduce模式中談海量資料處理前言 幾周前,當我最初聽到,以致後來初次接觸Hadoop與MapReduce這兩個東西,我便稍顯興奮,覺得它們很是神祕,而神祕的東西常能勾起我的興趣,在看過介紹它們的文章或論文之後,覺得Ha
在深度學習中處理不均衡資料集
在深度學習中處理不均衡資料集 不是所有的資料都是完美的。實際上,如果你拿到一個真實的完全均衡的資料集的話,那你真的是走運了。大部分的時候,你的資料都會有某種程度上的不均衡,也就是說你的資料集中每個類別的數量會不一樣。 我們為什麼想要資料是均衡的? 在我們開始花時間做深度學習專案之前,
JDBC(6)mysql中的大資料處理
免費錄播jdbc視訊 JDBC操作 驅動可以不註冊 * 可以省略 Class.forName(driver); (高版本) * 原因:mysql-connector-java-5.1.22-bin.ja
前端工作中常用的資料處理的js方法
1.函式:split() 功能:使用一個指定的分隔符把一個字串分割儲存到陣列 例子: str=”aaa|sss|ddd|fff|ggg”; arr=str.split(”|”); //arr是一個包含字元值”aaa”、”sss”、”ddd”、”fff”和”ggg”的陣列
mysql 資料庫實際應用中的大資料處理
某年某月,我接到公司的任務,要搭建一個遊戲平臺系統,管理旗下所有遊戲的玩家賬戶資料。起初拿到任務後,想了想。那麼這個系統就是一個註冊,一個登陸就ok了。 於是有了下面的資料庫設計。tbl_account. 表【主鍵ID,使用者名稱,密碼,註冊時間,……】 業務邏輯開發完成,