
[譯]改善ProGuard名稱混淆
原文連結:https://proandroiddev.com/improving-proguard-name-obfuscation-83b27b34c52a
改進ProGuard名稱混淆
文中,我將展示如何加強ProGuard的名稱模糊處理,使攻擊者難以對程式碼進行逆向工程,以及如何有助於防止不正確混淆造成的許多錯誤。
告訴你一個祕密:ProGuard實際上是一個程式碼優化器。其中一個優化的副作用恰恰是給結果位元組碼添加了一些名稱混淆,即類和方法名稱的短接和重用。實際的好處是,生成的二進位制檔案更小和更好的可壓縮性(更小的二進位制檔案可以更快載入到堆中,即減少延遲)。
ProGuard名稱混淆是如何工作的
ProGuard使用字典來定義要重新命名包,類或方法的內容。有一個預設字典只包含字母a-z。
考慮下面這個類:
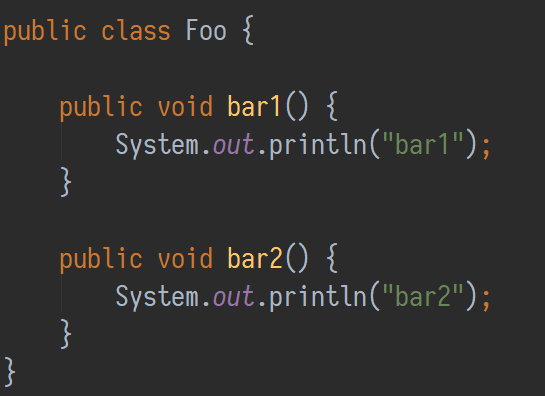
使用ProGuard優化時,從處理Foo.class開始。ProGuard會檢查它的字典,第一個條目是字母a。這個包裡沒有這個名字的類,所以Foo.class被命名為a.class。接下來是方法的重新命名:使用相同的策略,bar1()變成a(),bar2()變成b()。結果類的Java語法表示如下所示:

現在如果你新增一個新類Foobar.class,它被命名為b.class等等。如果包中有26個以上的類,名字會變長:aa.class,ab.class等。
防止確定性名稱混淆
名稱混淆處理是確定性的。有一個預定義順序(我猜這是詞典學),因此Foo.class仍然是a.class,在新增第二個類後,方法仍然分別是a()和b()。這並不意味著永遠不變。如果添加了一個類,這個類按順序排列位於其他類的中間,則混淆對映將會改變,但通常情況下該對映在構建中會保持不變。
從安全形度來看,這不是最佳選擇。例如,如果攻擊者知道應用程式的版本1中a.b()是許可證檢查邏輯,如果它仍然是a.b(),那麼在版本2中很容易找到相同的邏輯。
使用自定義名稱混淆字典
ProGuard允許定義如下字典:(參見官方手冊獲取更多資訊)
-obfuscationdictionary method 格式只是一個簡單的文字檔案,每行都有一個條目,忽略以#開頭的行和空行。
# A custom method dictonary
NUL
CoM4
COm9
lpt2
com5有可能對這些檔案有一點樂趣。 例如,在ProGuard發行版中,有一些替代字典的例子。這個檔案包含的名稱將使得無法從Windows中提取包中的類(例如.jar),因為它會建立非法的檔名。另一個版本經過優化,可以通過在位元組碼格式中使用常見的小關鍵字來實現儘可能最好的壓縮。另一種選擇是使用Java關鍵字作為類和方法名稱,這些名稱在位元組碼格式中允許建立非常令人困惑的呼叫堆疊。
無論哪種方式,這都會有點改善名稱混淆,但如果它是完全確定性的,我們仍然存在問題。
隨機化字典
Eric Lafortune,ProGuard(和商業版本DexGuard)的作者打算混淆是確定的(請參閱此特性的關於字典隨機化的請求),但有一個簡單的技巧可以解決這個問題:在我們的構建工具中, 在執行ProGuard前,只需生成一個隨機字典檔案。
以Android Gradle構建過程為例,可以在ProGuard任務之前動態新增執行的任務:
tasks.whenTaskAdded { currentTask ->
//Android Gradle plugin may change this task name in the future
def prefix = 'transformClassesAndResourcesWithProguardFor'
if (currentTask.name.startsWith(prefix)) {
def taskName = currentTask.name.replace(prefix,
'createProguardDictionariesFor')
task "$taskName" {
doLast {
createRandomizedDictonaries()
}
}
//append scramble task to proguard task
currentTask.dependsOn "$taskName"
}
}現在,任務在中需要做如下操作:
- 從臨時檔案讀取所有可能的欄位條目
- 對輸入專案進行洗牌; 不要選擇100%的輸入,而是選擇例如100%的隨機數。60-90%,因此對映不能在構建之間輕鬆轉換將條目寫入檔案
- 使用
-obfuscationdictionary將檔案引用ProGuard中 - 對類字典
-classobfuscationdictionary重複上述步驟
附加功能
建議的另一個功能是可以將所有類重新打包為一個包。這個配置會將所有的類移動到一個根級包o
-repackageclasses 'o'這也可以用上述類似的邏輯動態設定。
為了更容易的除錯,您可以打印出組裝好的ProGuard配置檔案(使用多個配置檔案時)
-printconfiguration proguard-merge-config.txt使用隨機名稱混淆的結果
請注意,每個構建版本都會有一個實際上獨特的混淆對映。所以在Android構建中,每個構建變體(flavor或構建型別)將建立非常不同的呼叫棧。因此,請小心保留Gradle中所有版本,flavor和構建型別的所有對映以及Maven中的所分類器。
但這不是一個缺點。許多Android開發者至少經歷過一次的錯誤:持續混淆名稱,這使得遷移變得不可能。這通常發生在使用Json資料繫結序列化器時,它通過反射讀取類和方法名並轉換它們,或者使用*.getClass().getName()與SharedPreferences或Databases一起使用。最糟糕的部分是:通常不會被注意到,因為名稱混淆對映可能會保留相同的版本。例如
{
"xf": {
"a": "Foo",
"ce": {
"tx": [{
"by": "Foobar",
"bv": 137
}]
}
}
}通過強制每次構建不同的對映,像這樣的錯誤將立即出現,實質上為ProGuard對映建立了快速失敗功能。
總結
- ProGuard的名稱混淆是確定性的,因此,當代碼只有一點變化時,對映通常在多個版本中保持不變
- 可為混淆建立隨機字典並告訴ProGuard使用它們,因此每個構建都將具有唯一的對映,這使得攻擊者難以對程式碼進行反向工程
- 隨機名稱混淆還具有充當常見的ProGuard配置問題的故障快速處理的優點