
windows本地eclispe執行linux上hadoop的maperduce程式
繼續上一篇博文:hadoop叢集的搭建
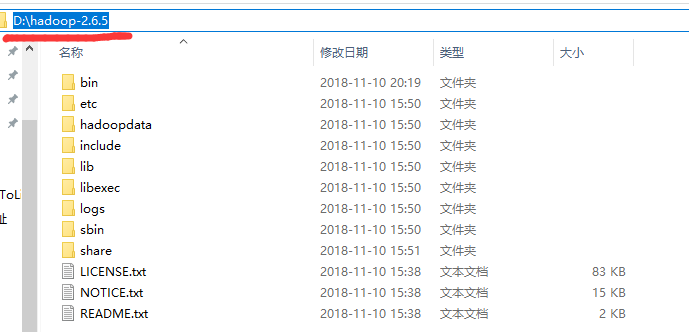
1.將linux節點上的hadoop安裝包從linux上下載下來(你也可以從網上直接下載壓縮包,解壓後放到自己電腦上)
我的地址是:
2.配置環境變數:
HADOOP_HOME D:\hadoop-2.6.5
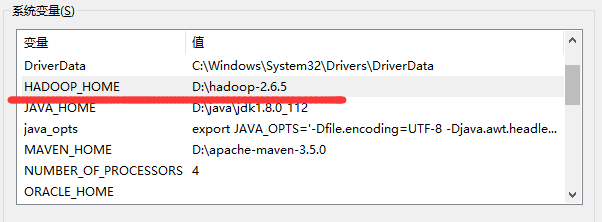
Path中新增:%HADOOP_HOME%\bin
3.下載hadoop-common-bin-master\2.7.1
並且拷貝其中的winutils.exe,libwinutils.lib這兩個檔案到hadoop安裝目錄的 bin目錄下
拷貝其中hadoop.dll,拷貝到c:\windows\system32;
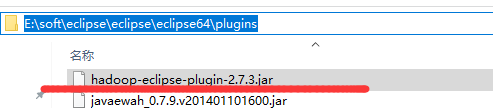
3.下載eclipse的hadoop外掛

4.拷貝到eclispe的plugin資料夾中
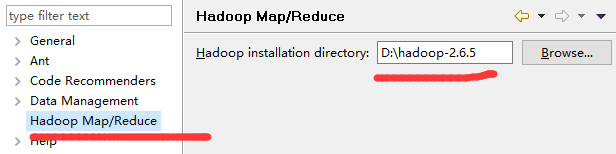
5.eclispe==》window==》Preferences
6.window==》show view==》other
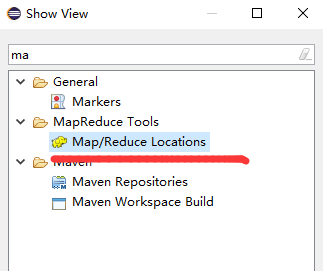
顯示面版

7.Map.Reduce Locations 面版中右擊
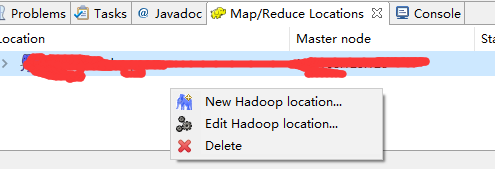
8.選擇 第一個New Hadoop location
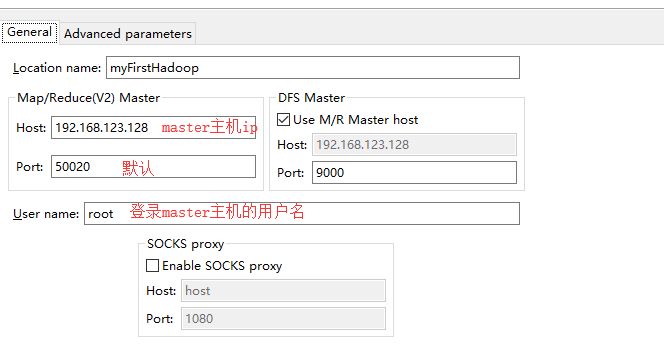
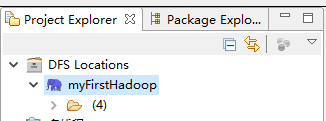
9.面板中多出來一頭小象

並且左側的Project Explorer視窗中的DFS Locations看到我們剛才新建的hadoop Location。
10.linux上準備測試檔案到
/opt中新建檔案 hadoop.txt內容如下:
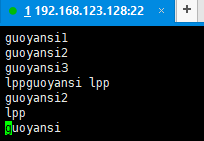
11.上傳到hadoop
hadoop fs -put /opt/hadoop.txt /test/input/hadoop.txt
12.重新整理eclipes的Hadoop Location 有我們剛才上傳的檔案

13.建立專案 File==>New==>Other

14.專案名稱

15.編寫原始碼:


package com.myFirstHadoop; import java.io.IOException; import java.util.StringTokenizer;View Codeimport org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WorkCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one=new IntWritable(1); private Text word=new Text(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ StringTokenizer itr=new StringTokenizer(value.toString()); while(itr.hasMoreTokens()){ word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result=new IntWritable(); public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{ int sum=0; for(IntWritable val:values){ sum+=val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf=new Configuration(); String[] otherArgs=new GenericOptionsParser(conf,args).getRemainingArgs(); if(otherArgs.length<2){ System.err.println("Useage:wordCount <in> [<in> ...] <out>"); System.exit(2); } Job job=new Job(conf,"word count"); job.setJarByClass(WorkCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for(int i=0;i<otherArgs.length-1;++i){ FileInputFormat.addInputPath(job, new Path(otherArgs[i])); FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length-1])); System.exit(job.waitForCompletion(true)?0:1); } } }
16.執行前的修改
右擊==》run as ==》Run Configurations
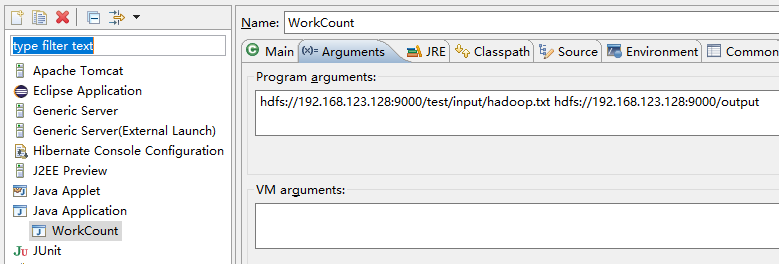
前面一個hdfs是輸入檔案;後面一個hdfs是輸出目錄
17.回到主介面右擊==》Run As==》Run on Hadoop 等執行結束後檢視Hadoop目錄
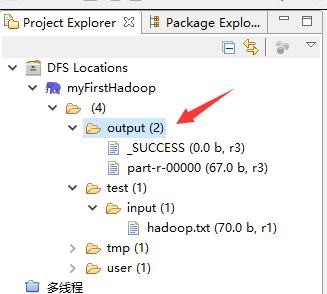
18.檢視執行結果:
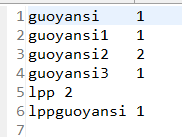
19.收工。