
第16章 Unity中的渲染優化技術
一一Michael A. Jackson
在進行程式優化的時候,人們經常會引用英國的電腦科學家Michael A. Jackson 在1988 年的優化準則。Jackson 是想借此強調,對問題認識不清以及過度優化往往會讓事情變得更加複雜,產生更多的程式錯誤。
然而, 如果我們在遊戲開發過程中從來都沒有考慮優化,那麼結果往往是慘不忍睹的。一個正確的做法是, 從一開始就把優化當成是遊戲設計中的一部分。正在閱讀本書的讀者,有可能是移動遊戲的開發者。和PC 相比,移動裝置上的GPU 有著完全不同的架構設計,它能使用的頻寬、功能和其他資源都非常有限。這要求我們需要時刻把優化謹記在心,才可以避免等到專案完成時才發現遊戲根本無法在移動裝置上流暢執行的結果。
在本章,我們將會闡述一些Unity 中常見的優化技術。這些優化技術都是和渲染相關的,例如, 使用批處理、LOD (Level of Detail )技術等。在本章最後的擴充套件閱讀部分, 我們給出一些非常有價值的參考資料, 在那裡讀者可以學習到更多真實專案中的優化技術。
在開始學習之前, 我們希望讀者能夠理解, 遊戲優化不僅是程式設計師的工作,更需要美工人員在遊戲的美術上進行一定的權衡,例如, 避免使用全屏的螢幕特效, 避免使用計算複雜的shader, 減少透明混合造成的overdraw 等。也就是說,這是由程式設計師和美工人員等各個部分人員共同參與的工作。
16.1 移動平臺的特點
和PC 平臺相比,移動平臺上的GPU 架構有很大的不同。由於處理資源等條件的限制, 移動裝置上的GPU 架構專注於盡可能使用更小的頻寬和功能,也由此帶來了許多和PC 平臺完全不同的現象。例如,為了儘可能移除那些隱藏的表面,減少overdraw (即一個畫素被繪製多次), PowerVR晶片(通常用於iOS 裝置和某些Android 裝置〉使用了基於瓦片的延遲渲染(Tiled-based Deferred Rendering, TBDR)
由於這些晶片架構造成的不同, 一些遊戲往往需要針對不同的晶片釋出不同的版本,以便對每個晶片進行更有針對性的優化。尤其是在Android 平臺上,不同裝置使用的硬體,如圖形晶片、螢幕解析度等,大相徑庭,這對圖形優化提出了更高的挑戰。相比與Android 平臺, iOS 平臺的硬體條件則相對統一。讀者可以在Unity 手冊的iOS 硬體指南
16.2 影響效能的因素
首先,在學習如何優化之前,我們得了解影響遊戲效能的因素有哪些,才能對症下藥。對於一個遊戲來說,它主要需要使用兩種方式計算資源: CPU 和GPU。它們會互相合作,來讓我們的遊戲可以在預期的幀率和解析度下工作。其中, CPU 主要負責保證幀率, GPU 主要負責解析度相關的一些處理。據此,我們可以把造成遊戲效能瓶頸的主要原因分成以下幾個方面。
(1 ) CPU。 ●過多的draw call 。 ●複雜的指令碼或者物理模擬。
(2) GPU。
● 頂點處理。
▶ 過多的頂點。
▶ 過多的逐頂點計算。
●片元處理。
▶ 過多的片元〈既可能是由於解析度造成的,也可能是由於overdraw 造成的〉。
▶ 過多的逐片元計算。
(3)頻寬。
● 使用了尺寸很大且未壓縮的紋理。
●解析度過高的幀快取。
對於CPU 來說,限制它的主要是每一幀中draw call 的數目。我們曾在2.2 節和2.4.3 節中介紹過draw call 的相關概念和原理。簡單來說,就是CPU 在每次通知GPU 進行渲染之前,都需要提前準備好頂點資料(如位置、法線、顏色、紋理座標等〉,然後呼叫一系列API 把它們放到GPU 可以訪問到的指定位置,最後,呼叫一個繪製命令,來告訴GPU ,“嘿,我把東西都準備好了,你趕緊出來幹活(渲染〉吧!”。而呼叫繪製命令的時候,就會產生一個 draw call。過多的draw call 會造成CPU 的效能瓶頸,這是因為每次呼叫draw call 時, CPU 往往都需要改變很多渲染狀態的設定,而這些操作是非常耗時的。如果一幀中需要的draw call 數目過多的話,就會導致CPU 把大部分時間都花費在提交draw call 的工作上面了。當然,其他原因也可能造成CPU 瓶頸,例如物理、布料模擬、蒙皮、粒子模擬等,這些都是計算量很大的操作,但由於本書主要討論Shader 方面的相關技術,因此,這些內容不在本書的討論範圍內。
而對於GPU 來說,它負責整個渲染流水線。它從處理CPU 傳遞過來的模型資料開始,進行頂點著色器、片元著色器等一系列工作,最後輸出螢幕上的每個畫素。因此, GPU 的效能瓶頸和需要處理的頂點數目、螢幕解析度、視訊記憶體等因素有關。而相關的優化策略可以從減少處理的資料規模(包括頂點數目和片元數目〉、減少運算複雜度等方面入手。
在瞭解了上面基本的內容後,本章後續章節會涉及的優化技術有。
(1) CPU 優化。
●使用批處理技術減少draw call 數目。
(2) GPU 優化。
●減少需要處理的頂點數目。
▶ 優化幾何體。
▶使用模型的LOD (Level ofDetail )技術。
▶使用遮擋剔除( Occlusion Culling )技術。
●減少需要處理的片元數目。
▶控制繪製順序。
▶警惕透明物體。
▶減少實時光照。 ●減少計算複雜度。
▶使用Shader 的LOD (Level of Detail) 技術。
▶程式碼方面的優化。
(3)節省記憶體頻寬。
●減少紋理大小。
●利用解析度縮放。
在開始優化之前,我們首先需要知道是哪個步驟造成了效能瓶頸。而這可以利用Unity 提供的一些渲染分析工具來實現。
16.3 Unity 中的渲染分析工具
Unity 內建了一些工具,來幫助我們方便地檢視和渲染相關的各個統計資料。這些資料可以幫助我們分析遊戲渲染效能,從而更有針對性地進行優化。在Unity 5 中,這些工具包括了渲染統計視窗( Rendering Statistics Window )、效能分析器( Profiler ) ,以及幀偵錯程式( Frame Debugger )。需要注意的是,在不同的目標平臺上,這些工具中顯示的資料也會發生變化。
16.3.1 認識Unity 5 的渲染統計視窗
Unity 5 提供了一個全新的視窗,即渲染統計視窗(Rendering Statistics Window )來顯示當前遊戲的各個渲染統計變數,我們可以通過在Game 檢視右上方的選單中單擊Stats 按鈕來開啟它,如圖16.1 所示。從圖16.1 中可以看出, 渲染統計視窗主要包含了3 個方面的資訊: 音訊(Audio )、影象( Graphics )和網路(Network)。我們這裡只關注第二個方面,即影象相關的渲染統計結果。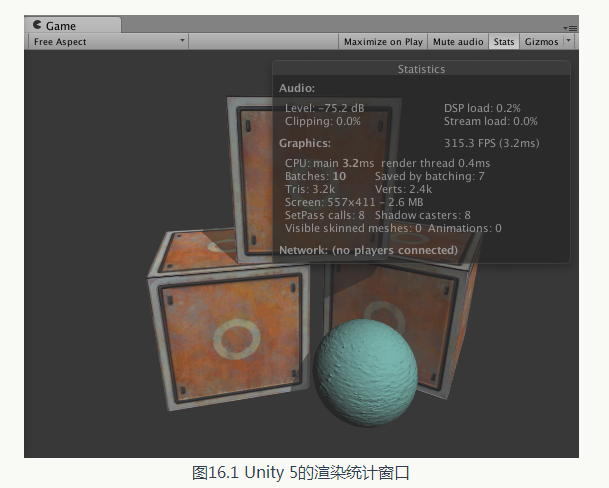 渲染統計視窗中顯示了很多重要的渲染資料,例如FPS 、批處理數目、頂點和三角網格的數目等。表16.1 列出了渲染統計視窗中顯示的各個資訊。
渲染統計視窗中顯示了很多重要的渲染資料,例如FPS 、批處理數目、頂點和三角網格的數目等。表16.1 列出了渲染統計視窗中顯示的各個資訊。


Unity 5 的渲染統計視窗相較於之前版本中的有了一些變化,最明顯的區別之一就是去掉了draw call 數目的顯示,而添加了批處理數目的顯示。Batches 和Saved by batching 更容易讓開發者理解批處理的優化結果。當然,如果我們想要檢視draw call 的數目等其他更加詳細的資料,可以通過Unity 編輯器的效能分析器來檢視。
16.3.2 效能分析器的渲染區域
我們可以通過單擊Window -> Profiler 來開啟Unity 的效能分析器(Profiler) 。 效能分析器中的渲染區域(Rendering Area )提供了更多關於渲染的統計資訊,圖16.2 給出了對圖16.1 中場景的渲染分析結果。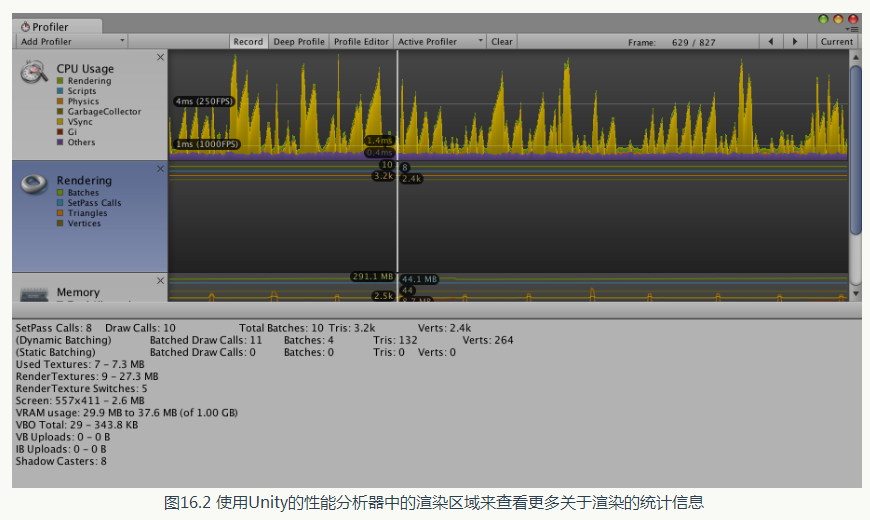
效能分析器顯示了絕大部分在渲染統計視窗中提供的資訊,例如,綠線顯示了批處理數目、藍線顯示了Pass 數目等,同時還給出了許多其他非常有用的資訊,例如, draw call 數目、動態批處理/靜態批處理的數目、渲染紋理的數目和記憶體佔用等。
結合渲染統計視窗和效能分析器,我們可以檢視與渲染相關的絕大多數重要的資料。一個值得注意的現象是,效能分析器給出的draw call 數目和批處理數目、Pass 數目並不相等,並且看起來好像要大於我們估算的數目,這是因為Unity 在背後需要進行很多工作,例如,初始化各個快取、為陰影更新深度紋理和陰影對映紋理等,因此需要花費比“預期”更多的draw call。一個好訊息是,Unity 5 引入了一個新的工具來幫助我們檢視每一個draw call 的工作,這個工具就是幀偵錯程式。
16.3.3 再談幀偵錯程式
我們已經在之前的章節中多次看到幀偵錯程式(Frame Debugger) 的應用,例如5.5.3 節中解釋瞭如何使用幀偵錯程式來對Shader 進行除錯。我們可以通過Window -> Frame Debugger 來開啟它。在這個視窗中,我們可以清楚地看到每一個draw call 的工作和結果,如圖16.3 所示。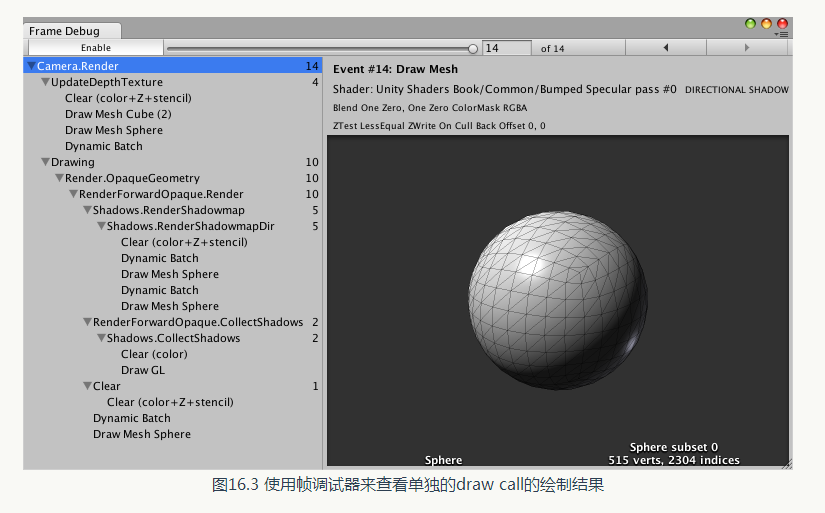 幀偵錯程式的除錯面板上顯示了渲染這一幀所需要的所有的渲染事件,在本例中,事件數目為14,而其中包含了10 個draw call 事件〈其他渲染事件多為清空快取等〉。通過單擊面板上的每個事件,我們可以在Game 檢視檢視該事件的繪製結果,同時渲染統計面板上的資料也會顯示成截止到當前事件為止的各個渲染統計資料。以本例為例〈場景如圖16.1 所示〉,要渲染一幀共需要花費10 個draw call,其中4 個draw call 用於更新深度紋理(對應UpdateDepthTexture), 4 個draw call 用於渲染平行光的陰影對映紋理,1 個draw call 用於繪製動態批處理後的3 個立方體模型, 1 個draw call 用於繪製球體。
幀偵錯程式的除錯面板上顯示了渲染這一幀所需要的所有的渲染事件,在本例中,事件數目為14,而其中包含了10 個draw call 事件〈其他渲染事件多為清空快取等〉。通過單擊面板上的每個事件,我們可以在Game 檢視檢視該事件的繪製結果,同時渲染統計面板上的資料也會顯示成截止到當前事件為止的各個渲染統計資料。以本例為例〈場景如圖16.1 所示〉,要渲染一幀共需要花費10 個draw call,其中4 個draw call 用於更新深度紋理(對應UpdateDepthTexture), 4 個draw call 用於渲染平行光的陰影對映紋理,1 個draw call 用於繪製動態批處理後的3 個立方體模型, 1 個draw call 用於繪製球體。在Unity 的渲染統計視窗、分析器和幀偵錯程式這3 個利器的幫助下,我們可以獲得很多有用的優化資訊。但是,很多諸如渲染時間這樣的資料是基於當前的開發平臺得到的,而非真機上的結果。事實上, Unity 正在和硬體生產商合作,來首先讓使用英偉達圖睿 ( Tegra)的裝置可以出現在Unity 的效能分析器中。我們有理由相信,在後續的Unity 版本中,直接在Unity 中對移動裝置進行效能分析不再是夢想。然而,在這個夢想實現之前,我們仍然需要一些外部的效能分析工具的幫助。
16.3.4 其他效能分析工具
對於移動平臺上的遊戲來說,我們更希望得到在真機上運行遊戲時的效能資料。這時,Unity 目前提供的各個工具可能就不再能滿足我們的需求了。對於Android 平臺來說,高通的Adreno 分析工具可以對不同的測試機進行詳細的效能分析。英偉達提供了NVPerfHUD 工具來幫助我們得到幾乎所有需要的效能分析資料,例如,每個draw call 的GPU 時間,每個shader 花費的cycle 數目等。
對於iOS 平臺來說, Unity 內建的分析器可以得到整個場景花費的GPU 時間。PowerVRAM的 PVRUniSCo shader 分析器也可以給出一個大致的效能評估。Xcode 中的OpenGL ES Driver Instruments 可以給出一些巨集觀上的效能資訊,例如,裝置利用率、渲染器利用率等。但相對於Android 平臺,對iOS 的效能分析更加困難(工具較少)。而且PowerVR 晶片採用了基於瓦片的延遲渲染器,因此,想要得到每個draw call 花費的GPU 時間是幾乎不可能的。這時,一些巨集觀上的統計資料可能更有參考價值。
一些其他的效能分析工具可以在Unity 的官方手冊( http://docs.unity3d.com/Manual/MobileProfiling.html )中找到。當找到了效能瓶頸後,我們就可以針對這些方面進行特定的優化。
16.4 減少draw call 數目
讀者最常看到的優化技術大概就是批處理( batching )了。批處理的實現原理就是為了減少每一幀需要的draw call 數目。為了把一個物件渲染到螢幕上, CPU 需要檢查哪些光源影響了該物體,繫結shader 並設定它的引數,再把渲染命令傳送給GPU。當場景中包含了大量物件時,這些操作就會非常耗時。一個極端的例子是,如果我們需要渲染一千個三角形,把它們按一千個單獨的網格進行渲染所花費的時間要遠遠大於渲染一個包含了一千個三角形的網格。在這兩種情況下,GPU 的效能消耗其實並沒有多大的區別,但CPU 的draw call 數目就會成為效能瓶頸。因此,批處理的思想很簡單,就是在每次面對draw call 時儘可能多地處理多個物體。我們已經在2.2 節和 2.4.3 節中詳細地講述了draw call 和批處理之間的聯絡,本節旨在介紹如何在Unity 中利用批處理技術來優化渲染。那麼,什麼樣的物體可以一起處理呢?答案就是使用同一個材質的物體。這是因為,對於使用同一個材質的物體,它們之間的不同僅僅在於頂點資料的差別。我們可以把這些頂點資料合併在一起,再一起傳送給GPU,就可以完成一次批處理。
Unity 中支援兩種批處理方式:一種是動態批處理,另一種是靜態批處理。對於動態批處理來說,優點是一切處理都是Unity 自動完成的,不需要我們自己做任何操作,而且物體是可以移動的,但缺點是,限制很多,可能一不小心就會破壞了這種機制,導致Unity 無法動態批處理一些使用了相同材質的物體。而對於靜態批處理來說,它的優點是自由度很高,限制很少;但缺點是可能會佔用更多的記憶體,而且經過靜態批處理後的所有物體都不可以再移動了(即便在指令碼中嘗試改變物體的位置也是無效的〉。
16.4.1 動態批處理
如果場景中有一些模型共享了同一個材質並滿足一些條件, Unity 就可以自動把它們進行批處理,從而只需要花費一個draw call 就可以渲染所有的模型。動態批處理的基本原理是,每一幀把可以進行批處理的模型網格進行合併,再把合併後模型資料傳遞給GPU然後使用同一個材質對其渲染。除了實現方便,動態批處理的另一個好處是,經過批處理的物體仍然可以移動,這是由於在處理每幀時Unity 都會重新合併一次網格。雖然Unity 的動態批處理不需要我們進行任何額外工作,但只有滿足條件的模型和材質才可以被動態批處理。需要注意的是,隨著Unity 版本的變化,這些條件也有一些改變。在本節中,我們給出一些主要的條件限制。
- 能夠進行動態批處理的網格的頂點屬性規模要小於900 。例如,如果shader 中需要使用頂點位置、法線和紋理座標這3 個頂點屬性,那麼要想讓模型能夠被動態批處理,它的頂點數目不能超過300。需要注意的是,這個數字在未來有可能會發生變化,因此不要依賴這個資料。
- 一般來說,所有物件都需要使用同一個縮放尺度(可以是(1, 1, 1 )、( 1, 2, 3)、(1.5, 1.4,1.3)等,但必須都一樣〉。一個例外情況是,如果所有的物體都使用了不同的非統一縮放,那麼它們也是可以被動態批處理的。但在Unity 5 中,這種對模型縮放的限制已經不存在了。
- 使用光照紋理(lightmap )的物體需要小心處理。這些物體需要額外的渲染引數,例如,在光照紋理上的索引、偏移量和縮放資訊等。因此,為了讓這些物體可以被動態批處理,我們需要保證它們指向光照紋理中的同一個位置。
- 多Pass 的shader 會中斷批處理。在前向渲染中,我們有時需要使用額外的Pass 來為模型新增更多的光照效果,但這樣一來模型就不會被動態批處理了。
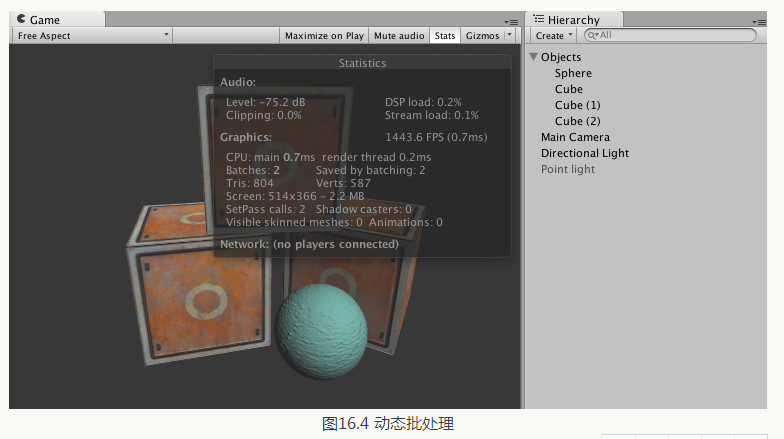 從圖16.4 中可以看出,要渲染這樣一個包含了4 個物體的場景共需要兩個批處理。其中, 一個批處理用於繪製經過動態批處理合並後的3 個立方體網格,另一個批處理用於繪製球體。我們可以從Save by batching看出批處理幫我們節省了兩個draw Call。
從圖16.4 中可以看出,要渲染這樣一個包含了4 個物體的場景共需要兩個批處理。其中, 一個批處理用於繪製經過動態批處理合並後的3 個立方體網格,另一個批處理用於繪製球體。我們可以從Save by batching看出批處理幫我們節省了兩個draw Call。現在,我們再向場景中新增一個點光源,並調整它的位置使它可以照亮場景中的4 個物體。由於場景中的物體都使用了多個Pass 的shader,因此,點光源會對它們產生光照影響。圖16.5 給出了新增點光源後的渲染統計資料。
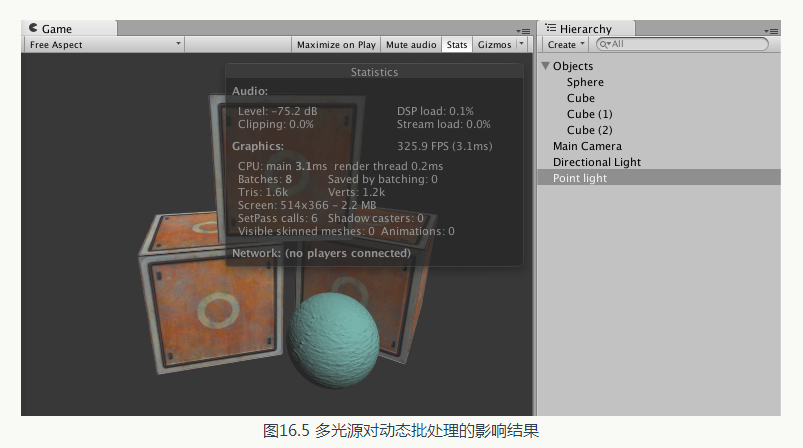
從圖16.5 中可以看出,渲染一幀所需的批處理數目增大到了8 ,而Save by batching的數目也變成了0。這是因為,使用了多個Pass 的shader 在需要應用多個光照的情況下,破壞了動態批處理的機制, 導致Unity 不能對這些物體進行動態批處理。而由於平行光和點光源需要對4 個物體分別產生影響,因此, 需要2×4 個批處理操作。需要注意的是,只有物體在點光源的影響範圍內,Unity 才會呼叫額外的Pass 來處理它。因此, 如果場景中點光源距離物體很遠,那麼它們仍然會被動態批處理的。
動態批處理的限制條件比較多,例如很多時候,我們的模型資料往往會超過900 的頂點屬性限制。這種時候依賴動態批處理來減少draw call 顯然已經不能夠滿足我們的需求了。這時,我們可以使用Unity 的靜態批處理技術。
16.4.2 靜態批處理
Unity 提供了另一種批處理方式, 即靜態批處理。相比於動態批處理來說,靜態批處理適用任何大小的幾何模型。它的實現原理是, 只在執行開始階段, 把需要進行靜態批處理的模型合併到一個新的網格結構中, 注意味著這些模型不可以在執行時刻被移動。但由於它只需要進行一次合併操作, 因此, 比動態批處理更加高效。靜態批處理的另一個缺點在於,它往往需要佔用更多的記憶體來儲存合併後的幾何結構。這是因為,如果在靜態批處理前一些物體共享了相同的網格,那麼在記憶體中每一個物體都會對應一個該網格的複製品,即一個網格會變成多個網格再發送給GPU 。如果這類使用同一網格的物件很多, 那麼這就會成為一個性能瓶頸了。例如,如果在一個使用了1 000 個相同樹模型的森林中使用靜態批處理,那麼,就會多使用1 000 倍的記憶體, 這會造成嚴重的記憶體影響。這種時候, 解決方法要麼忍受這種犧牲記憶體換取效能的方法,要麼不要使用靜態批處理,而使用動態批處理技術(但要小心控制模型的頂點屬性數目),或者自己編寫批處理的方法。在本書資源的Scene_16_3_2 場景中,我們給出了一個測試靜態批處理的場景。場景中包含了3 個Teapot 模型, 它們使用同一個材質,同時還包含了一個使用不同材質的立方體。場景中還包含了一個平行光,但我們關閉了它的陰影效果,以避免陰影計算對批處理數目的影響。在執行前,這樣一個場景的渲染統計資料如圖16.6 所示。
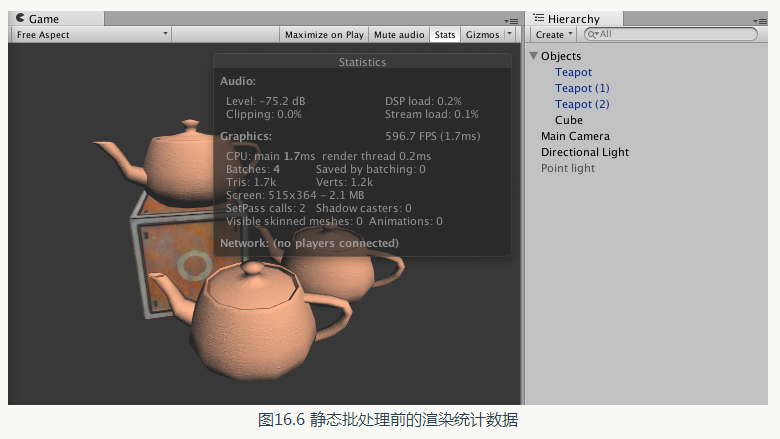 從圖16.6 中可以看出, 儘管3 個Teapot 模型使用了相同的材質, 但它們仍然沒有被動態批處理。這是因為, Teapot 模型包含的頂點數目是393 , 而它們使用的shader 中需要使用4 個頂點屬性(頂點位置、法線方向、切線方向和紋理座標〉,超過了動態批處理中限定的900 限制。此時,要想減少draw call 就需要使用靜態批處理。
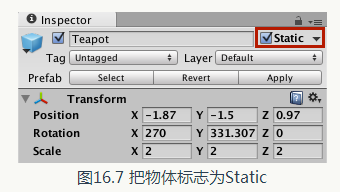
從圖16.6 中可以看出, 儘管3 個Teapot 模型使用了相同的材質, 但它們仍然沒有被動態批處理。這是因為, Teapot 模型包含的頂點數目是393 , 而它們使用的shader 中需要使用4 個頂點屬性(頂點位置、法線方向、切線方向和紋理座標〉,超過了動態批處理中限定的900 限制。此時,要想減少draw call 就需要使用靜態批處理。靜態批處理的實現非常簡單, 只需要把物體面板上的Static 複選框句選上即可(實際上我們只需要勾選Batching Static 即可),如圖16.7 所示。
 這時,我們再觀察渲染統計視窗中的批處理數目,還是沒有變化。但是不要急,執行程式後,變化就出現了,如圖16.8 所示。
這時,我們再觀察渲染統計視窗中的批處理數目,還是沒有變化。但是不要急,執行程式後,變化就出現了,如圖16.8 所示。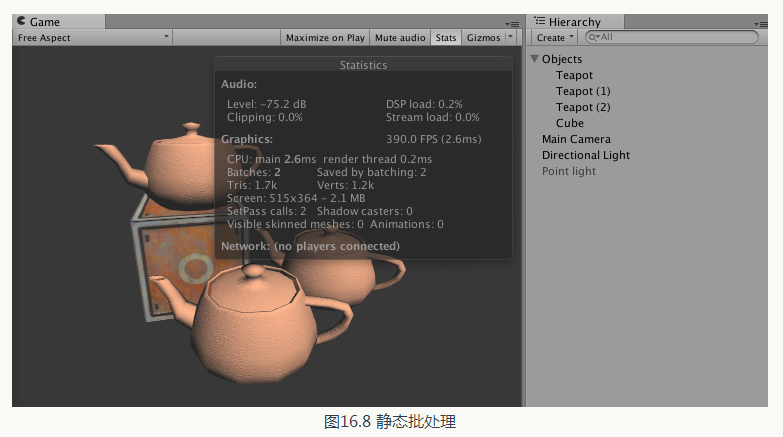
從圖16.8 中可以看出,現在的批處理數目變成了2,而Save by batching 數目也顯示為2。此時,如果我們在執行時檢視每個模型使用的網格,會發現它們都變成了一個名為Combined Mesh (root: scene)的東西,如圖16.9 所示。
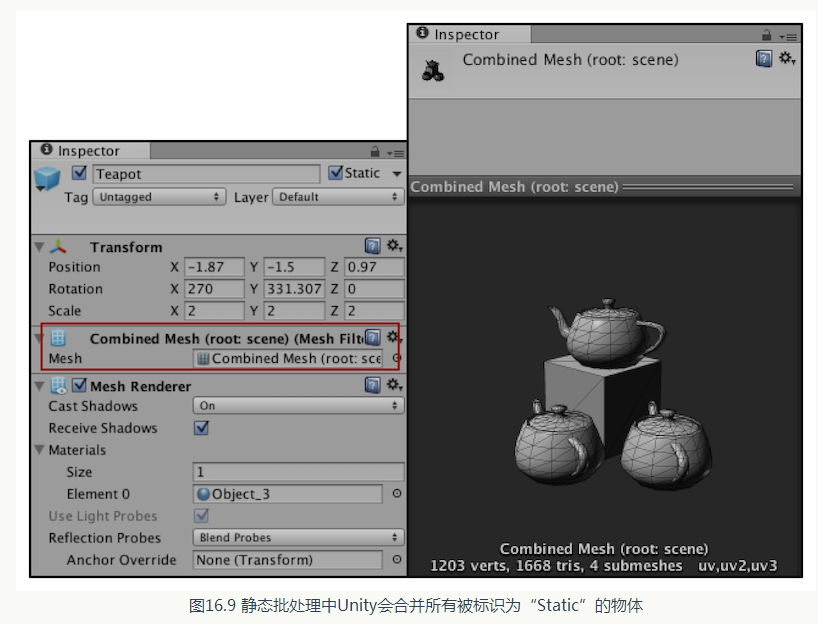
這個網格是Unity 合併了所有被標識為“Static”的物體的結果,在我們的例子裡,就是3 個Teapot 和一個立方體。讀者可能會有一個疑問,這4 個物件明明不是都使用了一個材質,為什麼可以合併成一個呢?如果你仔細觀看圖16.9 的結果,會發現在圖16.9 的右下方標明瞭“4 submeshes”,也就是說,這個合併後的網格其實包含了4 個子網格,即場景中的4 個物件。
對於合併後的網格, Unity 會判斷其中使用同一個材質的子網格,然後對它們進行批處理。
在內部實現上,Unity 首先把這些靜態物體變換到世界空間下,然後為它們構建一個更大的頂點和索引快取。對於使用了同一材質的物體,Unity 只需要呼叫一個draw call 就可以繪製全部物體。而對於使用了不同材質的物體,靜態批處理同樣可以提升渲染效能。儘管這些物體仍然需要呼叫多個draw call ,但靜態批處理可以減少這些draw call 之間的狀態切換,而這些切換往往是費時的操作。從合併後的網格結構中我們還可以發現,儘管3 個Teapot 物件使用了同一個網格,但合併後卻變成了3 個獨立網格。

而且,我們可以從Unity 的分析器中觀察到在應用靜態批處理前後VBO total的變化,從圖16.10 所示中可以看出,VBO ( Vertex Buffer Object,頂點緩衝物件〉的數目變大了。這正是因為靜態批處理會佔用更多記憶體的緣故,正如本節一開頭所講,靜態批處理需要佔用更多的記憶體來儲存合併後的幾何結構,如果一些物體共享了相同的網格,那麼在記憶體中每一個物體都會對應一個該網格的複製品。
如果場景中包含了除了平行光以外的其他光源,並且在shader 中定義了額外的Pass 來處理它們,這些額外的Pass 部分是不會被批處理的。圖16.11 顯示了在場景中添加了一個會影響4 個物體的點光源之後,渲染統計視窗的資料變化。
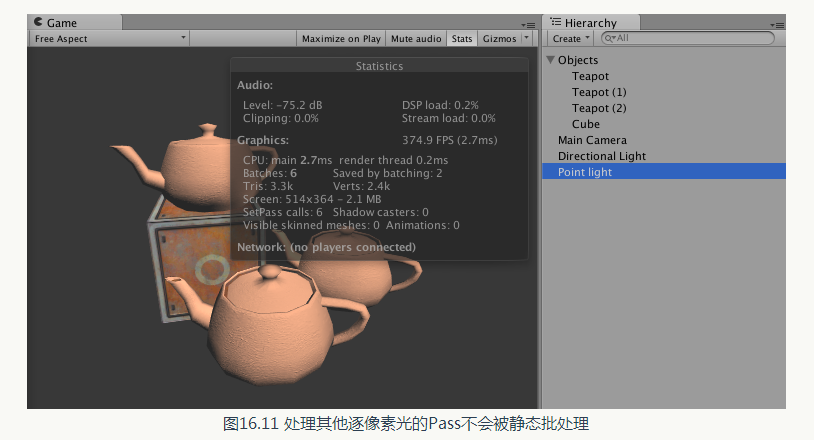
但是,處理平行光的Base Pass 部分仍然會被靜態批處理,因此,我們仍然可以節省兩個draw call.
16.4.3 共享材質
從之前的內容可以看出,無論是動態批處理還是靜態批處理,都要求模型之間需要共享同一個材質。但不同的模型之間總會需要有不同的渲染屬性,例如,使用不同的紋理、顏色等。這時,我們需要一些策略來儘可能地合併材質。如果兩個材質之間只有使用的紋理不同,我們可以把這些紋理合併到一張更大的紋理中,這張更大的紋理被稱為是一張圖集( atlas )。一旦使用了同一張紋理,我們就可以使用同一個材質,再使用不同的取樣座標對紋理取樣即可。
但有時,除了紋理不同外,不同的物體在材質上還有一些微小的引數變化,例如,顏色不同、某些浮點屬性不同。但是,不管是動態批處理還是靜態批處理,它們的前提都是要使用同一個材質。是同一個,而不是使用了同一種Shader 的材質,也就是說它們指向的材質必須是同一個實體。這意味著,只要我們調整了引數,就會影響到所有使用這個材質的物件。那麼想要微小的調整怎麼辦呢?一種常用的方法就是使用網格的頂點資料(最常見的就是頂點顏色資料〉來儲存這些引數。
前面說過,經過批處理後的物體會被處理成更大的VBO 傳送給GPU, VBO 中的資料可以作為輸入傳遞給頂點著色器,因此,我們可以巧妙地對VBO 中的資料進行控制,從而達到不同效果的目的。一個例子是,森林場景中所有的樹使用了同一種材質,我們希望它們可以通過批處理來減少draw call ,但不同樹的顏色可能不同。這時,我們可以利用網格的頂點的顏色資料來調整。
需要注意的是,如果我們需要在指令碼中訪問共享材質,應該使用Renderer.sharedMaterial 來保證修改的是和其他物體共享的材質,但這意味著修改會應用到所有使用該材質的物體上。另一個類似的API 是Renderer.material ,如果使用Renderer.material 來修改材質, Unity 會建立一個該材質的複製品,從而破壞批處理在該物體上的應用,這可能並不是我們希望看到的。
16.4.4 批處理的注意事項
在選擇使用動態批處理還是靜態批處理時,我們有一些小小的建設。- 儘可能選擇靜態批處理,但得時刻小心對記憶體的消耗,並且記住經過靜態批處理的物體不可以再被移動。
- 如果無法進行靜態批處理,而要使用動態批處理的話,那麼請小心上面提到的各種條件限制。例如,儘可能讓這樣的物體少並且儘可能讓這些物體包含少量的頂點屬性和頂點數目。
- 對於遊戲中的小道具,例如可以撿拾的金幣等,可以使用動態批處理。
- 對於包含動畫的這類物體,我們無法全部使用靜態批處理,但其中如果有不動的部分,可以把這部分標識成“Static”。
儘管在Unity 5.2 中,只實現了對一些渲染部分的批處理。而諸如渲染攝像機的深度紋理等部分,還沒有實現批處理。但我們相信,在後續的Unity 版本中,批處理會應用到越來越多的渲染部分中。
16.5 減少需要處理的頂點數目
儘管draw call 是一個重要的效能指標,但頂點數目同樣有可能成為GPU 的效能瓶頸。在本節中,我們將給出3 個常用的頂點優化策略。16.5.1 優化幾何體
3D 遊戲製作通常都是由模型製作開始的。而在建模時,有一條規則我們需要記住:儘可能減少模型中三角面片的數目, 一些對於模型沒有影響、或是肉眼非常難察覺到區別的頂點都要儘可能去掉。為了儘可能減少模型中的頂點數目,美工人員往往需要優化網格結構。在很多三維建模軟體中,都有相應的優化選項,可以自動優化網格結構。在Unity 的渲染統計視窗中,我們可以檢視到渲染當前幀需要的三角面片數目和頂點數目。需要注意的是, Unity 中顯示的數目往往要多於建模軟體裡顯示的頂點數,通常Unity 中顯示的數目要大很多。誰才是對的呢?其實,這是因為在不同的角度上計算的,都有各自的道理,但我們真正應該關心的是Unity 裡顯示的數目。
我們在這裡簡單解釋一下造成這種不同的原因。三維軟體更多地是站在我們人類的角度理解頂點的,即組成幾何體的每一個點就是一個單獨的點。而Unity 是站在GPU 的角度上去計算頂點數的。在GPU 看來,有時需要把一個頂點拆分成兩個或更多的頂點。這種將頂點一分為多的原因主要有兩個:一個是為了分離紋理座標(uv splits), 另一個是為了產生平滑的邊界(smoothing splits).它們的本質,其實都是因為對於GPU 來說,頂點的每一個屬性和頂點之間必須是一對一的關係。而分離紋理座標,是因為建模時一個頂點的紋理座標有多個。例如,對於一個立方體,它的6 個面之間雖然使用了一些相同的頂點,但在不同面上,同一個頂點的紋理座標可能並不相同。對於GPU 來說,這是不可理解的,因此,它必須把這個頂點拆分成多個具有不同紋理座標的頂點。而平滑邊界也是類似的,不同的是,此時一個頂點可能會對應多個法線資訊或切線資訊。這通常是因為我們要決定一個邊是一條硬邊 ( hard edge )還是一條平滑邊(smooth edge )。
對於GPU 來說,它本質上只關心有多少個頂點。因此,儘可能減少頂點的數目其實才是我們真正需要關心的事情。因此,最後一條几何體優化建議就是:移除不必要的硬邊以及紋理銜接,避免邊界平滑和紋理分離。
16.5.2 模型的LOO 技術
另一個減少頂點數目的方法是使用LOD (Level of Detail) 技術。這種技術的原理是,當一個物體離攝像機很遠時,模型上的很多細節是無法被察覺到的。因此,LOD 允許當物件逐漸遠離攝像機時,減少模型上的面片數量,從而提高效能。在Unity 中,我們可以使用LOD Group 元件來為一個物體構建一個LOD。我們需要為同一個物件準備多個包含不同細節程式的模型,然後把它們賦給LOD Group 元件中的不同等級, Unity就會自動判斷當前位置上需要使用哪個等級的模型。
16.5.3 遮擋剔除技術
我們最後要介紹的頂點優化策略就是遮擋剔除( Occlusion culling)技術。遮擋剔除可以用來消除那些在其他物件後面看不到的物件,這意味著資源不會浪費在計算那些看不到的頂點上,進而提升效能。我們需要把遮擋剔除和攝像機的視錐體剔除( Frustum Culling )區分開來。視錐體剔除只會剔除掉那些不在攝像機的視野範圍內的物件,但不會判斷視野中是否有物體被其他物體擋住。而遮擋剔除會使用一個虛擬的攝像機來遍歷場景,從而構建一個潛在可見的物件集合的層級結構。
在執行時刻,每個攝像機將會使用這個資料來識別哪些物體是可見的,而哪些被其他物體擋住不可見。使用遮擋剔除技術,不僅可以減少處理的頂點數目,還可以減少overdraw,提高遊戲效能。
要在Unity 中使用遮擋剔除技術,我們需要進行一系列額外的處理工作。具體步驟可以參見Unity 手冊的相關內容 (http://docs.unity3d.com/Manual/OcclusionCulling.html ),本書不再贅述。
模型的LOD 技術和遮擋剔除技術可以同時減少CPU 和GPU 的負荷。CPU 可以提交更少的draw call ,而GPU 需要處理的頂點和片元數目也減少了。
16.6 減少需要處理的片元數目
另一個造成GPU 瓶頸的是需要處理過多的片元。這部分優化的重點在於減少overdraw 。簡單來說, overdraw 指的就是同一個畫素被繪製了多次。Unity 還提供了檢視overdraw 的檢視,我們可以在Scene 檢視左上方的下拉選單中選中Overdraw 即可。實際上,這裡的檢視只是提供了檢視物體相互遮擋的層數,並不是真正的最終螢幕繪製的overdraw 。也就是說,可以理解為它顯示的是,如果沒有使用任何深度測試和其他優化策略時的overdraw 。這種檢視是通過把所有物件都渲染成一個透明的輪廓,通過檢視透明顏色的累計程度,來判斷物體之間的遮擋。當然,我們可以使用一些措施來防止這種最壞情況的出現。
16.6.1 控制繪製順序
為了最大限度地避免overdraw, 一個重要的優化策略就是控制繪製順序。由於深度測試的存在,如果我們可以保證物體都是從前往後繪製的,那麼就可以很大程度上減少overdraw。這是因為,在後面繪製的物體由於無法通過深度測試,因此,就不會再進行後面的渲染處理。在Unity 中,那些渲染佇列數目小於2 500 (如“Background" "Geometry ”和“Alpha Test")的物件都被認為是不透明( opaque )的物體,這些物體總體上是從前往後繪製的,而使用其他的佇列(如“ Transparent "“ Overlay"等)的物體,則是從後往前繪製的。這意味著,我們可以儘可能地把物體的佇列設定為不透明物體的渲染佇列,而儘量避免使用半透明佇列。
而且,我們還可以充分利用Unity 的渲染佇列來控制繪製順序。例如,在第一人稱射擊遊戲中,對於遊戲中的主要人物角色來說,他們使用的shader 往往比較複雜,但是,由於他們通常會擋住螢幕的很大一部分割槽域,因此我們可以先繪製它們(使用更小的渲染佇列〉。而對於一些敵方角色,它們通常會出現在各種掩體後面,因此,我們可以在所有常規的不透明物體後面渲染它們(使用更大的渲染佇列〉。而對於天空盒子來說, 它幾乎覆蓋了所有的畫素,而且我們知道它本遠會出現在所有物體的後面,因此, 它的佇列可以設定為“ Geometry+ 1 ”。這樣,就可以保證不會因為它而造成overdraw 。
這些排序的思想往往可以節省掉很多渲染時間。
16.6.2 時刻警惕透明物體
對於半透明物件來說,由於它們沒有開啟深度寫入,因此,如果要得到正確的渲染效果,就必須從後往前渲染。這意味著,半透明物體幾乎一定會造成overdraw。如果我們不注意這一點,在一些機器上可能會造成嚴重的效能下降。例如,對於GUI 物件來說,它們大多被設定成了半透明,如果螢幕中GUI 佔據的比例太多,而主攝像機又沒有進行調整而是投影整個螢幕,那麼GUI就會造成大量overdraw 。因此,如果場景中包含了大面積的半透明物件,或者有很多層相互覆蓋的半透明物件(即使它們每個的面積可能都不大〉,或者是透明的粒子效果, 在移動裝置上也會造成大量的overdraw 。這是應該儘量避免的。
對於上述GUI 的這種情況,我們可以儘量減少視窗中GUI 所佔的面積。如果實在無能為力,我們可以把GUI的繪製和三維場景的繪製交給不同的攝像機, 而其中負責三維場景的攝像機的視角範圍儘量不要和GUI的相互重疊。當然,這樣會對遊戲的美觀度產生一定影響,因此,我們可以在程式碼中對機器的效能進行判斷,例如,首先關閉一些耗費效能的功能,如果發現這個機器表現非常良好,再嘗試開啟一些特效功能。
在移動平臺上, 透明度測試也會影響遊戲效能。雖然透明度測試沒有關閉深度測試, 但由於它的實現使用了discard 或clip 操作, 而這些操作會導致一些硬體的優化策略失效。例如, 我們之前講過PowerVR 使用的基於瓦片的延遲渲染技術, 為了減少overdraw 它會在呼叫片元著色器前就判斷哪些瓦片被真正渲染的。但是,由於透明度測試在片元著色器中使用了discard 函式改變了片元是否會被渲染的結果,因此, GPU 就無法使用上述的優化策略了。也就是說,只要在執行了所有的片元著色器後, GPU 才知道哪些片元會被真正渲染到螢幕上, 這樣, 原先那些可以減少overdraw 的優化就都無效了。這種時候, 使用透明度混合的效能往往比使用透明度測試更好。
16.6.3 減少實時光照和陰影
實時光照對於移動平臺是一種非常昂貴的操作。如果場景中包含了過多的點光源,並且使用了多個Pass 的Shader,那麼很有可能會造成效能下降。例如,一個場景裡如果包含了3 個逐畫素的點光源,而且使用了逐畫素的Shader,那麼很有可能將draw call 數目( CPU 的瓶頸〉提高3倍,同時也會增加overdraw ( GPU 的瓶頸)。這是因為, 對於逐畫素的光源來說, 被這些光源照亮的物體需要被再渲染一次。更糟糕的是,無論是靜態批處理還是動態批處理,對於這種額外的處理逐畫素光源的Pass 都無法進行批處理,也就是說,它們會中斷批處理。當然,遊戲場景還是需要光照才能得到出色的畫面效果。我們看到很多成功的移動平臺的遊戲,它們的畫面效果看起來好像包含了很多光源,但其實這都是騙人的。這些遊戲往往使用了烘焙技術,把光照提前烘焙到一張光照紋理(lightmap )中, 然後在執行時刻只需要根據紋理取樣得到光照結果即可。另一個模擬光源的方法是使用God Ray 。場景中很多小型光源的效果都是靠這種方法模擬的。它們一般並不是真的光源, 很多情況是通過透明紋理模擬得到的。更多資訊可以參見本章的擴充套件閱讀部分。在移動平臺上, 一個物體使用的逐畫素光源數目應該小於1(不包括平行光) 。如果一定要使用更多的實時光,可以選擇用逐頂點光照來代替。
在遊戲《ShadowGun》中,遊戲角色看起來使用了非常複雜高階的光照計算, 但這實際上是優化後的結果。開發者們把複雜的光照計算儲存到一張查詢紋理(lookup texture,也被稱為查詢表, lookup table, LUT )中。然後在執行時刻,我們只需要使用光源方向、視角方向、法線方向等引數,對LUT 取樣得到光照結果即可。使用這樣的查詢紋理,不僅可以讓我們使用更出色的光照模型,例如,更加複雜的BRDF 模型,還可以利用查詢紋理的大小來進一步優化效能,例如,主要角色可以使用更大解析度的LUT,而一些NPC 就使用較小的LUT 。《ShadowGun》的開發者開發了一個LUT 烘倍工具,來幫助美工人員快速調整光照模型,並把結果儲存到LUT 中。
實時陰影同樣是一個非常消耗效能的效果。不僅是CPU 需要提交更多的draw call, GPU 也需要進行更多的處理。因此,我們應該儘量減少實時陰影,例如,使用烘焙把靜態物體的陰影資訊儲存到光照紋理中,而只對場景中的動態物體使用適當的實時陰影。
16.7 節省頻寬
大量使用未經壓縮的紋理以及使用過大的解析度都會造成由於頻寬而引發的效能瓶頸。16.7.1 減少紋理大小
之前提到過,使用紋理圖集可以幫助我們減少draw call 的數目,而這些紋理的大小同樣是一個需要考慮的問題。需要注意的是,所有紋理的長寬比最好是正方形,而且長寬值最好是2 的整數幕。這是因為有很多優化策略只有在這種時候才可以發揮最大效用。 在Unity5 中,即便我們匯入的紋理長寬值並不是2 的整數幕, Unity 也會自動把長寬轉換到離它最近的2 的整數幕值。但我們仍然應該在製作美術資源時就把這條規則謹記在心,防止由於放縮而造成不好的影響。除此之外,我們還應該儘可能使用多級漸遠紋理技術( mipmapping )和紋理壓縮。在Unity 中,我們可以通過紋理匯入面板來檢視紋理的各個匯入屬性。通過把紋理型別設定為Advanced,就可以自定義許多選項,例如,是否生成多級漸遠紋理( mipmaps ),如圖16.12 所示。
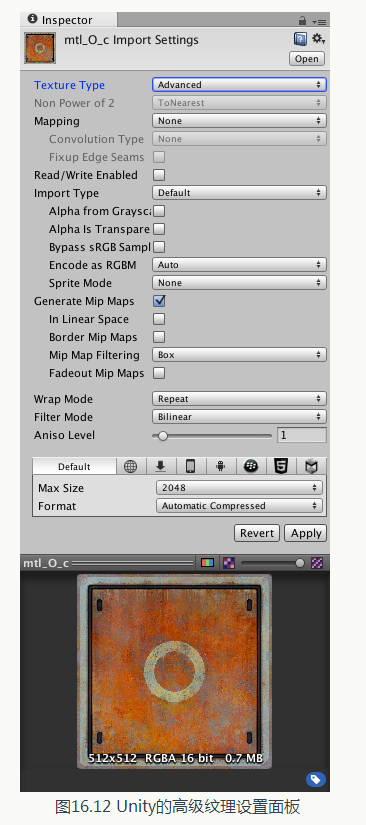
當勾選了Generate Mip Maps選項後, Unity 就會為同一張紋理創建出很多不同大小的小紋理,構成一個紋理金字塔。而在遊戲執行中就可以根據距離物體的遠近,來動態選擇使用哪一個紋理。這是因為,在距離物體很遠的時候,就算我們使用了非常精細的紋理,但肉眼也是分辨不出來的。這種時候,我們完全可以使用更小、更模糊的紋理來代替,這可以讓GPU 使用解析度更小的紋理,大量節省訪問的畫素數目。在某些裝置上,關閉多級漸遠紋理往往會造成嚴重的效能問題。因此,除非我們確定該紋理不會發生縮放, 例如GUI 和2D 遊戲中使用的紋理等,都應該為紋理生成相應的多級漸遠紋理。 紋理壓縮同樣可以節省頻寬。但對於像Android 這樣的平臺,有很多不同架構的GPU,紋理壓縮就變得有點複雜,因為不同的GPU 架構有它自己的紋理壓縮格式,例如, PowerVRAM 的PVRTC 格式、Tegra 的DXT 格式、Adreno 的ATC 格式。所幸的是, Unity 可以根據不同的裝置選擇不同的壓縮格式,而我們只需要把紋理壓縮格式設定為自動壓縮即可。但是, GUI 型別的紋理同樣是個例外,一些時候由於對畫質的要求,我們不希望對這些紋理進行壓縮。
16.7.2 利用解析度縮放
過高的螢幕解析度也是造成效能下降的原因之一,尤其是對於很多低端手機,除了解析度高其他硬體條件並不盡如人意,而這恰恰是遊戲效能的兩個瓶頸: 過大的螢幕解析度和糟糕的GPU。因此,我們可能需要對於特定機器進行解析度的放縮。當然,這樣可能會造成遊戲效果的下降,但效能和畫面之間永遠是個需要權衡的話題。在Unity 中設定螢幕解析度可以直接呼叫Screen.SetResolution。實際使用中可能會遇到一些情況,雨鬆MOMO 有一篇文章 ( http://www.xuanyusong.com/archives/3205 )詳細講解了如何使用這種技術,讀者可參考。
16.8 減少計算複雜度
計算複雜度同樣會影響遊戲的渲染效能。在本節中, 我們會介紹兩個方面的技術來減少計算複雜度。16.8.1 Shader 的LOD 技術
和16.5.2 節提到的模型的 LOD 技術類似, Shader 的 LOD 技術可以控制使用的Shader 等級。它的原理是,只有Shader 的 LOD 值小於某個設定的值,這個Shader 才會被使用,而使用了那些超過設定值的Shader 的物體將不會被渲染。我們通常會在SubShader 中使用類似下面的語句來指明該shader 的LOD 值:
SubShader {
Tags {”RenderType”=”Opaque”}
LOO 20016.8.2 程式碼方面的優化
在實現遊戲效果時,我們可以選擇在哪裡進行某些特定的運算。通常來講, 遊戲需要計算的物件、頂點和畫素的數目排序是
物件數 < 頂點數<畫素數。因此, 我們應該儘可能地把計算放在每個物件或逐頂點上。例如,在第13 章實現高斯模糊和邊緣檢測時,我們把取樣座標的計算放在了頂點著色器中,這樣的做法遠好於把它們放在片元著色器中。
而在具體的程式碼編寫上,不同的硬體甚至需要不同的處理。因此,一些普遍的規則在某些硬件上可能並不成立。更不幸的是,通常Shader 程式碼的優化並不那麼直觀,尤其是一些平臺上缺少相關的分析器, 例如iOS 平臺。儘管如此,在本節我們還是會給出一些被認為是普遍成立的優化策略,但讀者如果發現在某些裝置上效能反而有所下降的話,這並不奇怪。
首先第一點是,儘可能使用低精度的浮點值進行運算。最高精度的float/highp 適用於儲存諸如頂點座標等變數, 但它的計算速度是最慢的,我們應該儘量避免在片元著色器中使用這種精度進行計算。而half/mediump 適用於一些標量、紋理座標等變數,它的計算速度大約是float 的兩倍。而 fixed/lowp 適用於絕大多數顏色變數和歸一化後的方向向量,在進行一些對精度要求不高的計算時,我們應該儘量使用這種精度的變數。它的計算速度大約是float 的4 倍,但要避免對這些低精度變數進行頻繁的swizzle 操作(如color.xwxw )。還需要注意的是,我們應當儘量避免在不同精度之間的轉換,這有可能會造成一定的效能下降。
對於絕大多數GPU 來說,在使用插值暫存器把資料從頂點著色器傳遞給下一個階段時,我們應該使用盡可能少的插值變數。例如,如果需要對兩個紋理座標進行插值,我們通常會把它們打包在同一個float4 型別的變數中,兩個紋理座標分別對應了xy 分量和 zw 分量。然而,對於PowerVR平臺來說,這種插值變數是非常廉價的,直接把不同的紋理座標儲存在不同的插值變數中,有時反而效能更好。尤其是, 如果在PowerVR 上使用類似 tex2D(_MainTex, uv.zw)這樣的語句來進行紋理取樣, GPU 就無法進行一些紋理的預讀取, 因為它會認為這些紋理取樣是需要依賴其他資料的。因此,如果我們特別關心遊戲在PowerVR 上的效能, 就不應該把兩個紋理座標打包在同一個四維變數中。
儘可能不要使用全屏的屏幕後處理效果。如果美術風格實在是需要使用類似Bloom、熱擾動這樣的螢幕特效,我們應該儘量使用 fixed/lowp 進行低精度運算(紋理座標除外,可以使用 half/mediump )。那些高精度的運算可以使用查詢表(LUT)或者轉移到頂點著色器中進行處理。除此之外, 儘量把多個特效合併到一個Shader 中。例如,我們可以把顏色校正和新增噪聲等螢幕特效在Bloom 特效的最後一個Pass 中進行合成。還有一個方法就是使用16.8.3 節中介紹的縮放思想, 來選擇性地開啟特效。
還有一些讀者經常會聽到的程式碼優化規則。
- 儘可能不要使用分支語句和迴圈語句。
- 儘可能避免使用類似sin 、tan、pow、log 等較為複雜的數學運算。我們可以使用查詢表來作為替代。
- 儘可能不要使用discard 操作,因為這會影響硬體的某些優化。
16.8.3 根據硬體條件進行縮放
諸如iOS 和 Android 這樣的移動平臺,不同裝置之間的效能千差萬別。我們很容易可以找到一臺手機的渲染效能是另一臺手機的10 倍。那麼,如何確保遊戲可以同時流暢地執行在不同效能的移動裝置上呢? 一個非常簡單且實用的方式是使用所謂的放縮(scaling)思想。我們首先保證遊戲最基本的配置可以在所有的平臺上執行良好,而對於一些具有更高表現能力的裝置,我們可以開啟一些更“養眼”的效果,比如使用更高的解析度,開啟屏幕後處理特效,開啟粒子效果等。
16.9 擴充套件閱讀
Unity 官方手冊的移動平臺優化實踐指南 (http://docs.unity3d.com/Manual/MobileOptimizationPracticalGuide.html )一文給出了一些針對移動平臺的優化技術,包括渲染和圖形方面的優化,以及指令碼優化等。手冊中另一個針對影象效能優化的文件是優化影象性(http://docs.unity3d.com/Manual/OptimizingGraphicsPerformance.html)一文,在這個文件中,Unity 給出了常見的效能瓶頸以及一些相應的優化技術。除此之外, 文件列出了一個清單,包含了優化遊戲效能的常見做法和約束。在SIGGRAPH 2011 上, Unity 進行了一個關於移動平臺上 Shader 優化的演講 (http://blogs.unity3d.com/2011/08/18/fast-mobile-shaders-talk-at-siggraph/)。在這個演講中,作者給出了各個主流移動GPU 的架構特點,並給出了相應的shader 優化細節, 還結合了真實的Unity 遊戲專案來進行例項學習。在Unite 2013 會議上, Unity 呈現了一個名為針對移動平臺優化Unity 遊戲的演講,在這個簡短的演講中,作者對造成效能瓶頸的原因進行了分類,並給出了一些常見的優化技術。在GDC 2014 上, Unity 展示瞭如何使用內建的分析器分析移動平臺的遊戲效能,讀者可以在Youtube上找到相應的視訊。在最近的SIGGRAPH 2015 會議上, Unity 進行了一系列演講和課程。在Unity和來自高通、ARM 等公司的開發人員共同呈現的名為Moving Mobile Graphics 的課程中,來自Unity 的Renaldas Zioma 講解了移動平臺上PBR 的優化技術。更多Unity 在SIGGRAPH 2015 上的演講,讀者可以參見Unity 的部落格。
除了手冊和演講資料外,成功的移動平臺中的遊戲同樣是非常好的學習資料。《ShadowGun》是由MadFinger 在2011 年釋出的一款移動平臺的第三人稱射擊遊戲, 使用的開發工具正是Unity 。在Unite 2011 上,該遊戲的開發者給出了《ShadowGun》中使用的渲染和優化技術,讀者可以在Youtube 上面找到這個視訊。更難能可貴的是,在2012 年, 《ShadowGun》的開發者放出了示例
場景,來讓更多的開發者學習如何優化移動平臺上的shader。另一個非常好的遊戲優化例項是Unity 自帶的專案《Angry Bots》, 讀者可以直接在Unity 資源商店下載到完整的專案原始碼。