
系統學習NLP(六)--語義分析
轉自:https://www.jianshu.com/p/7463267b0106
對於不同的語言單位,語義分析的任務各不相同。在詞的層次上,語義分析的基本任務是進行詞義消歧(WSD),在句子層面上是語義角色標註(SRL),在篇章層面上是指代消歧,也稱共指消解。
詞義消歧
由於詞是能夠獨立運用的最小語言單位,句子中的每個詞的含義及其在特定語境下的相互作用構成了整個句子的含義,因此,詞義消歧是句子和篇章語義理解的基礎,詞義消歧有時也稱為詞義標註,其任務就是確定一個多義詞在給定上下文語境中的具體含義。
詞義消歧的方法也分為有監督的消歧方法和無監督的消歧方法,在有監督的消歧方法中,訓練資料是已知的,即每個詞的詞義是被標註了的;而在無監督的消歧方法中,訓練資料是未經標註的。
多義詞的詞義識別問題實際上就是該詞的上下文分類問題,還記得詞性一致性識別的過程嗎,同樣也是根據詞的上下文來判斷詞的詞性。
有監督詞義消歧根據上下文和標註結果完成分類任務。而無監督詞義消歧通常被稱為聚類任務,使用聚類演算法對同一個多義詞的所有上下文進行等價類劃分,在詞義識別的時候,將該詞的上下文與各個詞義對應上下文的等價類進行比較,通過上下文對應的等價類來確定詞的詞義。此外,除了有監督和無監督的詞義消歧,還有一種基於詞典的消歧方法。
在詞義消歧方法研究中,我們需要大量測試資料,為了避免手工標註的困難,我們通過人工製造資料的方法來獲得大規模訓練資料和測試資料。其基本思路是將兩個自然詞彙合併,建立一個偽詞來替代所有出現在語料中的原詞彙。帶有偽詞的文字作為歧義原文字,最初的文字作為消歧後的文字。
有監督的詞義消歧方法
有監督的詞義消歧方法通過建立分類器,用劃分多義詞上下文類別的方法來區分多義詞的詞義。
基於互資訊的消歧方法
基於互資訊的消歧方法基本思路是,對每個需要消歧的多義詞尋找一個上下文特徵,這個特徵能夠可靠地指示該多義詞在特定上下文語境中使用的是哪種語義。
互資訊是兩個隨機變數X和Y之間的相關性,X與Y關聯越大,越相關,則互資訊越大。
這裡簡單介紹用在機器翻譯中的Flip-Flop演算法,這種演算法適用於這樣的條件,A語言中有一個詞,它本身有兩種意思,到B語言之後,有兩種以上的翻譯。
我們現在有的,是B語言中該詞的多種翻譯,以及每種翻譯所對應的上下文特徵。
我們需要得到的,是B語言中的哪些翻譯對應義項1,哪些對應義項2。
這個問題複雜的地方在於,對於普通的詞義消歧,比如有兩個義項的多義詞,詞都是同一個,上下文有很多,我們把這些上下文劃分為兩個等價類;而這種跨語言的,不僅要解決上下文的劃分,在這之前還要解決兩個義項多種詞翻譯的劃分。
這裡面最麻煩的就是要先找到兩種義項分別對應的詞翻譯,和這兩種義項分別對應的詞翻譯所對應的上下文特徵,以及他們之間的對應關係。
想象一下,地上有兩個圈,代表兩個義項;這兩個圈裡,分別有若干個球,代表了每個義項對應的詞翻譯;然後這兩個圈裡還有若干個方塊,代表了每個義項在該語言中對應的上下文。然後球和方塊之間有線連著(球與球,方塊與方塊之間沒有),隨便連線,球可以連多個方塊,方塊也可以連多個球。然後,圈沒了,兩個圈裡的球和方塊都混在了一起,亂七八糟的,你該怎麼把屬於這兩個圈的球和方塊分開。
Flip-Flop演算法給出的方法是,試試。把方塊分成兩個集合,球也分成兩個集合,然後看看情況怎麼樣,如果情況不好就繼續試,找到最好的劃分。然後需要解決的問題就是,怎麼判定分的好不好?用互資訊。
如果兩個上下文集(方塊集)和兩個詞翻譯集(球集)之間的互資訊大,那我們就認為他們的之間相關關係大,也就與原來兩個義項完美劃分更接近。
實際上,基於互資訊的這種方法直接把詞翻譯的義項劃分也做好了。
基於貝葉斯分類器的消歧方法
基於貝葉斯分類器的消歧方法的思想與《淺談機器學習基礎》中講的樸素貝葉斯分類演算法相同,當時是用來判定垃圾郵件和正常郵件,這裡則是用來判定不同義項(義項數可以大於2),我們只需要計算給定上下文語境下,概率最大的詞義就好了。
根據貝葉斯公式,兩種情況下,分母都可以忽略,所要計算的就是分子,找最大的分子,在垃圾郵件識別中,分子是P(當前郵件所出現的詞語|垃圾郵件)P(垃圾郵件),那麼乘起來就是垃圾郵件和當前郵件詞語出現的聯合分佈概率,正常郵件同理;而在這裡分子是P(當前詞語所存在的上下文|某一義項)P(某一義項),這樣計算出來的就是某一義項和上下文的聯合分佈概率,再除以分母P(當前詞語所存在的上下文),計算出來的結果就是P(某一義項|當前詞語所存在的上下文),就能根據上下文去求得概率最大的義項了。
基於最大熵的詞義消歧方法
利用最大熵模型進行詞義消歧的基本思想也是把詞義消歧看做一個分類問題,即對於某個多義詞根據其特定的上下文條件(用特徵表示)確定該詞的義項。
基於詞典的詞義消歧方法
基於詞典語義定義的消歧方法
M. Lesk 認為詞典中的詞條本身的定義就可以作為判斷其詞義的一個很好的條件,就比如英文中的core,在詞典中有兩個定義,一個是『松樹的球果』,另一個是指『用於盛放其它東西的錐形物,比如盛放冰激凌的錐形薄餅』。如果在文字中,出現了『樹』、或者出現了『冰』,那麼這個core的詞義就可以確定了。
我們可以計算詞典中不同義項的定義和詞語在文字中上下文的相似度,就可以選擇最相關的詞義了。
基於義類詞典的消歧方法
和前面基於詞典語義的消歧方法相似,只是採用的不是詞典裡義項的定義文字,而是採用的整個義項所屬的義類,比如ANMINAL、MACHINERY等,不同的上下文語義類有不同的共現詞,依靠這個來對多義詞的義項進行消歧。
無監督的詞義消歧方法
嚴格地講,利用完全無監督的消歧方法進行詞義標註是不可能的,因為詞義標註畢竟需要提供一些關於語義特徵的描述資訊,但是,詞義辨識可以利用完全無監督的機器學習方法實現。
其關鍵思想在於上下文聚類,計算多義詞所出現的語境向量的相似性就可以實現上下文聚類,從而實現詞義區分。
語義角色標註概述
語義角色標註是一種淺層語義分析技術,它以句子為單位,不對句子所包含的予以資訊進行深入分析,而只是分析句子的謂詞-論元結構。具體一點講,語義角色標註的任務就是以句子的謂詞為中心,研究句子中各成分與謂詞之間的關係,並且用語義角色來描述它們之間的關係。比如:
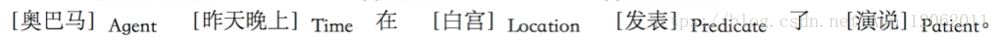
實際上就是填槽吧,找到句子中的時間、地點、施事者、受事者和核心謂詞。
目前語義角色標註方法過於依賴句法分析的結果,而且領域適應性也太差。
自動語義角色標註是在句法分析的基礎上進行的,而句法分析包括短語結構分析、淺層句法分析和依存關係分析,因此,語義角色標註方法也分為基於短語結構樹的語義角色標註方法、基於淺層句法分析結果的語義角色標註方法和基於依存句法分析結果的語義角色標註方法三種。
它們的基本流程類似,在研究中一般都假定謂詞是給定的,所要做的就是找出給定謂詞的各個論元,也就是說任務是確定的,找出這個任務所需的各個槽位的值。其流程一般都由4個階段組成:

候選論元剪除的目的就是要從大量的候選項中剪除掉那些不可能成為論元的項,從而減少候選項的數目。
論元辨識階段的任務是從剪除後的候選項中識別出哪些是真正的論元。論元識別通常被作為一個二值分類問題來解決,即判斷一個候選項是否是真正的論元。該階段不需要對論元的語義角色進行標註。
論元標註階段要為前一階段識別出來的論元標註語義角色。論元標註通常被作為一個多值分類問題來解決,其類別集合就是所有的語義角色標籤。
最終,後處理階段的作用是對前面得到的語義角色標註結果進行處理,包括刪除語義角色重複的論元等。
基於短語結構樹的語義角色標註方法
首先是第一步,候選論元剪除,具體方法如下:
將謂詞作為當前結點,依次考察它的兄弟結點:如果一個兄弟結點和當前結點在句法結構上不是並列的關係,則將它作為候選項。如果該兄弟結點的句法標籤是介詞短語,則將它的所有子節點都作為候選項。
將當前結點的父結點設為當前結點,重複上一個步驟,直至當前結點是句法樹的根結點。
舉個例子,候選論元就是圖上畫圈的:
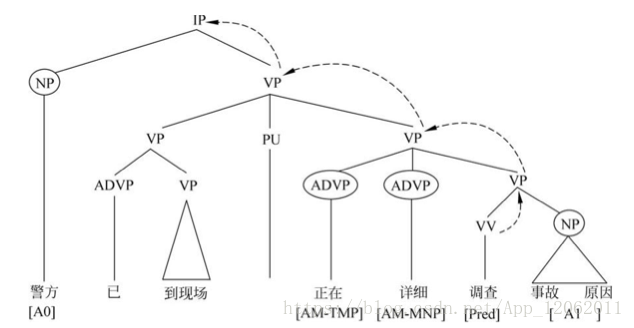
經過剪除得到候選論元之後,進入論元識別階段,為分類器選擇有效的特徵。人們總結出了一些常見的有效特徵,比如謂詞本身、路徑、短語型別、位置、語態、中心詞、從屬類別、論元的第一個詞和最後一個詞、組合特徵等等。
然後進行論元標註,這裡也需要找一些對應的特徵。然後後處理並不是必須的。
基於依存關係樹的語義角色標註方法
該語義角色標註方法是基於依存分析樹進行的。由於短語結構樹與依存結構樹不同,所以基於二者的語義角色標註方法也有不同。
在基於短語結構樹的語義角色標方法中,論元被表示為連續的幾個詞和一個語義角色標籤,比如上面圖給的『事故 原因』,這兩個詞一起作為論元A1;而在基於依存關係樹的語義角色標註方法中,一個論元被表示為一箇中心詞和一個語義角色標籤,就比如在依存關係樹中,『原因』是『事故』的中心詞,那隻要標註出『原因』是A1論元就可以了,也即謂詞-論元關係可以表示為謂詞和論元中心詞之間的關係。
下面給一個例子:
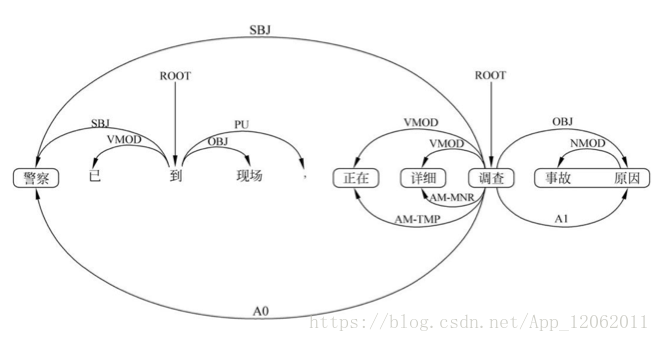
句子上方的是原來的依存關係樹,句子下方的則是謂詞『調查』和它的各個論元之間的關係。
第一步仍然是論元剪除,具體方法如下:
將謂詞作為當前結點
將當前結點的所有子結點都作為候選項
將當前結點的父結點設為當前結點,如果新當前結點是依存句法樹的根結點,剪除過程結束,如果不是,執行上一步
論元識別和論元標註仍然是基於特徵的分類問題,也有一些人們總結出來的常見特徵。這裡不詳述。
基於語塊的語義角色標註方法
我們前面知道,淺層語法分析的結果是base NP標註序列,採用的方法之一是IOB表示法,I表示base NP詞中,O表示詞外,B表示詞首。
基於語塊的語義角色標註方法將語義角色標註作為一個序列標註問題來解決。
基於語塊的語義角色標註方法一般沒有論元剪除這個過程,因為O相當於已經剪除了大量非base NP,也即不可能為論元的內容。論元辨識通常也不需要了,base NP就可以認為是論元。
我們需要做的就是論元標註,為所有的base NP標註好語義角色。與基於短語結構樹或依存關係樹的語義角色標註方法相比,基於語塊的語義角色標註是一個相對簡單的過程。
當然,因為沒有了樹形結構,只是普通序列的話,與前兩種結構相比,丟失掉了一部分資訊,比如從屬關係等。
語義角色標註的融合方法
由於語義角色標註對句法分析的結果有嚴重的依賴,句法分析產生的錯誤會直接影響語義角色標註的結果,而進行語義角色標註系統融合是減輕句法分析錯誤對語義角色標註影響的有效方法。
這裡所說的系統融合是將多個語義角色標註系統的結果進行融合,利用不同語義角色標註結果之間的差異性和互補性,綜合獲得一個最好的結果。
在這種方法中,一般首先根據多個不同語義角色標註結果進行語義角色標註,得到多個語義角色標註結果,然後通過融合技術將每個語義角色標註結果中正確的部分組合起來,獲得一個全部正確的語義角色標註結果。
融合方法這裡簡單說一種基於整數線性規劃模型的語義角色標註融合方法,該方法需要被融合的系統輸出每個論元的概率,其基本思想是將融合過程作為一個推斷問題處理,建立一個帶約束的最優化模型,優化目標一般就是讓最終語義角色標註結果中所有論元的概率之和最大了,而模型的約束條件則一般來源於人們根據語言學規律和知識所總結出來的經驗。
除了基於整數線性規劃模型的融合方法之外,人們還研究了若干種其他融合方法,比如最小錯誤加權的系統融合方法。其基本思想是認為,不應該對所有融合的標註結果都一視同仁,我們在進行融合時應當更多的信賴總體結果較好的系統。