
詳解生成器、迭代器
原文:http://www.cnblogs.com/vipchenwei/p/6991204.html
本文講述了以下幾個方面:
1.何為迭代,何為可迭代物件,何為生成器,何為迭代器?
2.可迭代物件與迭代器之間的區別
3.生成器內部原理解析,for迴圈迭代內部原理解析
4.可迭代物件,迭代器,生成器,生成器函式之間關係
1.迭代
要搞清楚什麼關於迭代器,生成器,可迭代物件,前提是我們要理解何為迭代。
第一,迭代需要重複進行某一操作
第二,本次迭代的要依賴上一次的結果繼續往下做,如果中途有任何停頓,都不能算是迭代.
下面來看看幾個例子,你就會更能理解迭代的含義。
# example1
# 非迭代
count = 0
while count < 10:
print("hello world")
count += 1# example2
# 迭代
count = 0
while count < 10:
print(count)
count += 1例子1,僅僅只是在重複一件事,那就是不停的列印"hello world",並且,這個列印的結果並不依賴上一次輸出的值。而例子2,就很好地說明迭代的含義,重複+繼續。
2.可迭代物件
按照上面迭代的含義,我們應該能夠知道何為可迭代物件。顧名思義,就是一個物件能夠被迭代的使用。那麼我們該如何判斷一個物件是否可迭代呢?
Python提供了模組collections,其中有一個isinstance(obj,string)的函式,可以判斷一個物件是否為可迭代物件。看下面例項:
from collections import Iterable f = open('a.txt') i = 1 s = '1234' d = {'abc':1} t = (1,2,344) m = {1,2,34,} print(isinstance(i, Iterable)) # 判斷整型是否為可迭代物件 print(isinstance(s, Iterable)) # 判斷字串物件是否為可迭代物件 print(isinstance(d, Iterable)) # 判斷字典物件是否為可迭代物件 print(isinstance(t, Iterable)) # 判斷元組物件是否為可迭代物件 print(isinstance(m, Iterable)) # 判斷集合物件是否為可迭代物件 print(isinstance(f, Iterable)) # 判斷檔案物件是否為可迭代物件 ########輸出結果######### False True True True True True
由上面得出,除了整型之外,python內的基本資料型別都是可迭代物件,包括檔案物件。那麼,python內部是如何知道一個物件是否為可迭代物件呢?答案是,在每一種資料型別物件中,都會有有一個__iter__()方法,正是因為這個方法,才使得這些基本資料型別變為可迭代。
如果不信,我們可以來看看下面程式碼片段:
f = open('a.txt')
i = 1
s = '1234'
d = {'abc':1}
t = (1,2,344)
m = {1,2,34,}
# hasattr(obj,string) 判斷物件中是否存在string方法
print(hasattr(i, '__iter__'))
print(hasattr(s, '__iter__'))
print(hasattr(d, '__iter__'))
print(hasattr(t, '__iter__'))
print(hasattr(m, '__iter__'))
print(hasattr(f, '__iter__'))
#########輸出結果#######
C:\Python35\python3.exe D:/CODE_FILE/python/day21/迭代器.py
False
True
True
True
True
True如果大家還是不信,可以繼續來測試。我們自己來寫一個類,看看有__iter__()方法和沒有此方法的區別。
# 沒有__iter__()方法
class Animal:
def __init__(self):
pass
cat = Animal()
print(isinstance(cat, Iterable))
######輸出結果##########
False
# 有__iter__()方法
class Animal:
def __init__(self):
pass
def __iter__(self):
pass
cat = Animal()
print(isinstance(cat, Iterable))
######輸出結果##########
True從上面,實驗結果可以看出一個物件是否可迭代,關鍵看這個物件是否有__iter__()方法。
3.迭代器
在介紹迭代器之前,我們先來了解一下容器這個概念。
容器是一種把多個元素組織在一起的資料結構,容器中的元素可以逐個地迭代獲取。簡單來說,就好比一個盒子,我們可以往裡面存放資料,也可以從裡面一個一個地取出資料。
在python中,屬於容器型別地有:list,dict,set,str,tuple.....。容器僅僅只是用來存放資料的,我們平常看到的 l = [1,2,3,4]等等,好像我們可以直接從列表這個容器中取出元素,但事實上容器並不提供這種能力,而是可迭代物件賦予了容器這種能力。
說完了容器,我們在來談談迭代器。迭代器與可迭代物件區別在於:__next__()方法。
我們可以採用以下方法來驗證一下:
from collections import Iterator
f = open('a.txt')
i = 1
s = '1234'
d = {'abc':1}
t = (1, 2, 344)
m = {1, 2, 34, }
print(isinstance(i,Iterator))
print(isinstance(s,Iterator))
print(isinstance(d,Iterator))
print(isinstance(t,Iterator))
print(isinstance(m,Iterator))
print(isinstance(f,Iterator))
########輸出結果##########
False
False
False
False
False
True結果顯示:除了檔案物件為迭代器,其餘均不是迭代器
下面,我們進一步來驗證一下:
print(hasattr(i,"__next__"))
print(hasattr(s,"__next__"))
print(hasattr(d,"__next__"))
print(hasattr(t,"__next__"))
print(hasattr(m,"__next__"))
print(hasattr(f,"__next__"))
#######結果###########
False
False
False
False
False
True從輸出結果可以表明,迭代器與可迭代物件僅僅就是__next__()方法的有無。
4.for內部機制剖析
先來看看一段普通的迭代過程:
l = [1,2,3,4,5]
for i in l:
print(i)根據之前的分析,我們知道 l = [1,2,3,4,5]是一個可迭代物件。而且可迭代物件是不可以直接從其中取到元素。那麼為啥我們還能從列表L中取到元素呢?這一切都是因為for迴圈內部實現。在for迴圈內部,首先L會呼叫__iter__()方法,將列表L變為一個迭代器,然後這個迭代器再呼叫其__next__()方法,返回取到的第一個值,這個元素就被賦值給了i,接著就列印輸出了。
下面,我們通過一系列的實驗來證明上述所說的。
l = [1,2,3,4,5,6]
item = l.__iter__() # 將l變為迭代器
print(item.__next__()) # 迭代器呼叫next方法,並且返回取出的元素
print(item.__next__())
print(item.__next__())
print(item.__next__())
print(item.__next__())
print(item.__next__())
print(item.__next__()) # 報錯
#######輸出結果#############
1 2 3 4 5 6
######上面為什麼報錯呢??##########
#當呼叫了最後一個next方法,沒有下一個元素可取
#就會報錯StopIteration異常錯誤。你可能會想會
#為什麼for迴圈沒有報錯?答案很簡單,因為for循
#環內部幫我們捕捉到了這個異常,一旦捕捉到異常
#說明,迭代應該結束了!
###########################上述實驗,與我上面說明的一致。
下面,我們可以while迴圈來模擬for迴圈,輸出列表中的元素。
l = [1,2,3,4,5]
item = l.__iter__() # 生成一個迭代器
while True:
try:
i = item.__next__()
print(i)
except StopIteration: # 捕獲異常,如果有異常,說明應該停止迭代
break由上分析,我們可以總結出:當我們試圖用for迴圈來迭代一個可迭代物件時候,for迴圈在內部進行了兩步操作:第一,將可迭代物件S變為迭代器M;第二,迭代器M呼叫__next__()方法,並且返回其取出的元素給變數i。
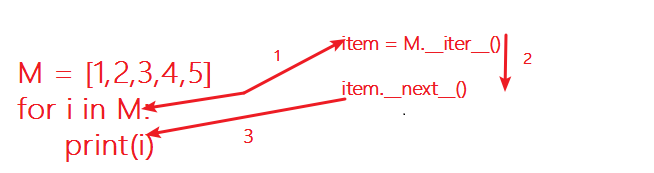
你可能看見過這種寫法,for i in iter(M):xxx ,其實這一步操作和我們上面沒什麼區別。iter()函式,就是將一個可迭代物件M變為迭代器也就是M呼叫__iter__()方法,然後內部在呼叫__next__()方法。也就是說,
M = [1,2,3,4,5]
for i in iter(M): # 等價於 M.__iter()__ 人為顯示呼叫
print(i)
for i in M: # 直譯器隱式呼叫
print(i)
#################
#
#上面輸出的結果完全一樣
#
#################還有next(M)等價於M.__next__。
迭代器優點:
1.節約記憶體
2.不依賴索引取值
3.實現惰性計算(什麼時候需要,在取值出來計算)
5.生成器(本質就是迭代器)
什麼是生成器?可以理解為一種資料型別,這種資料型別自動實現了迭代器協議(其他的資料型別需要呼叫自己內建的__iter__方法)。
按照我們之前所說的,迭代器必須滿足兩個條件:既有__iter__(),又有__next__()方法。那麼生成器是否也有這兩個方法呢?答案是,YES。具體來通過以下程式碼來看看。
def func():
print("one------------->")
yield 1
print("two------------->")
yield 2
print("three----------->")
yield 3
print("four------------>")
yield 4
print(hasattr(func(),'__next__'))
print(hasattr(func(),'__iter__'))
#########輸出結果###########
True
True實驗表明,生成器就是迭代器。
Python有兩種不同的方式提供生成器:
1.生成器函式(函式內部有yield關鍵字):常規函式定義,但是,使用yield語句而不是return語句返回結果。yield語句一次返回一個結果,在每個結果中間,掛起函式的狀態,以便下次重它離開的地方繼續執行
2.生成器表示式:類似於列表推導,但是,生成器返回按需產生結果的一個物件,而不是一次構建一個結果列表
既然生成器就是迭代器,那麼我們是不是也可以通過for迴圈來遍歷出生成器中的內容呢?看下面程式碼.
def func():
print("one------------->")
yield 1
print("two------------->")
yield 2
print("three----------->")
yield 3
print("four------------>")
yield 4
for i in func():
print(i)
#########輸出結果########
one------------->
1
two------------->
2
three----------->
3
four------------>
4很顯然,生成器也可以通過for迴圈來遍歷出其中的內容。
下面我們來看看生成器函式執行流程:
def func():
print("one------------->")
yield 1
print("two------------->")
yield 2
print("three----------->")
yield 3
print("four------------>")
yield 4
g = func() # 生成器 == 迭代器
print(g.__next__())
print(g.__next__())
print(g.__next__())
print(g.__next__())每次呼叫g.__next__()就回去函式內部找yield關鍵字,如果找得到就輸出yield後面的值並且返回;如果沒有找到,就會報出異常。上述程式碼中如果在呼叫g.__next__()就會報錯。
Python使用生成器對延遲操作提供了支援。所謂延遲操作,是指在需要的時候才產生結果,而不是立即產生結果。這也是生成器的主要好處。
| 1 |
|
import time
def tail(filepath):
with open(filepath, encoding='utf-8') as f:
f.seek(0, 2) # 停到末尾開頭 1從當前位置 2從檔案末尾
while True:
line = f.readline()
if line: # 如果有內容讀出
#print(line,end='')
yield line # 遍歷時停在此行,並且將其返回值傳遞出去
else:
time.sleep(0.5) # 如果檔案為空,休眠 等待輸入
def grep(lines, patterns): # lines為生成器型別
for line in lines: # 遍歷生成器
if patterns in line:
yield line
g = grep(tail('a.txt'), 'error') # 動態跟蹤檔案新新增的內容,並且過濾出有patterns的行
g1 = grep(g,'404') # g1為生成器
for i in g1: # 通過for迴圈來隱式呼叫__next__()方法
print(i)生成器小結:
1.是可迭代物件
2.實現了延遲計算,省記憶體啊
3.生成器本質和其他的資料型別一樣,都是實現了迭代器協議,只不過生成器附加了一個延遲計算省記憶體的好處,其餘的可迭代物件可沒有這點好處!
6.可迭代物件、迭代器、生成器關係總結
