
《深入分析JavaWeb技術內幕》之 8-深入分析ClassLoader工作機制
8.1實體記憶體和虛擬記憶體
所謂實體記憶體就是我們通常所說的RAM(隨機儲存器)。在計算機中,還有一個儲存單元叫暫存器,它用於儲存計算單元執行指令(如浮點、整數等運算時)的中間結果。暫存器的大小決定了一次計算可使用的最大數值。
連線處理器和RAM或者處理器和暫存器的是地址匯流排,這個地址匯流排的寬度影響了實體地址的索引範圍,因為匯流排的寬度決定了處理器一次可以從暫存器或者記憶體中獲取多少個bit。同時也決定了處理器最大可以定址的地址空間,如32位地址匯流排可以定址的範圍為0x0000 0000-0xffff ffff。這個範圍是2^32=4294967296個記憶體位置,每個地址會引用一個位元組,所以32位匯流排寬度可以有4GB的記憶體空間。
除了在學校的編譯原理的實踐課或者要開發硬體程式的驅動程式時需要直接通過程式訪問儲存器外,我們大部分情況都呼叫作業系統提供的介面來訪問記憶體,在java中甚至不需要寫和記憶體相關的程式碼。
不管是在Windows系統還是Linxu系統下,我們要執行程式,都要向作業系統先申請記憶體地址。通常作業系統管理記憶體的申請空間是按照程序來管理的,每個程序擁有一段獨立的地址空間,每個程序之間不會相互重合,作業系統也會保證每個程序只能訪問自己的記憶體空間。這主要是從程式的安全性來考慮,也便於作業系統來管理實體記憶體。
8.3在Java中那些元件需要使用記憶體
Java堆
執行緒
JVM執行實際程式的實體是執行緒,當然執行緒需要記憶體空間來儲存一些必要的資料。每個執行緒建立時JVM都會為它建立一個堆疊,堆疊的大小根據不同的JVM實現而不同,通常在256K~756K之間。
執行緒所佔空間相比堆空間來說比較小。但是如果縣城過多,執行緒堆疊的總記憶體使用量可能也非常大。當前有很多應用程式根據CPU的核數來分配建立的執行緒數,如果執行的應用程式的執行緒數量比可用於處理它們的處理器數量多,效率通常很低,並且可能導致比較差的效能和更高的記憶體佔用率。
堆外記憶體
堆外記憶體會自動清理本機緩衝區,但這個過程只能作為Java堆GC的一部分來執行,因此它們不會自動相應施加在本機堆上的壓力。GC僅在Java堆被填滿,以至於無法為堆分配請求提供服務時發生,或者在Java應用程式中顯示請求時發生。可以通過呼叫System.gc()來釋放堆外記憶體。但是這種方式會影響程式的效能,因為會增加GC的次數,一般情況下通過設定-XX:+DisableExplicitGC來控制System.gc()的影響,但是又會導致堆外記憶體洩漏問題。
JNI
JNI技術使得本機程式碼(如C語言程式)可以呼叫Java方法,也就是通常所說的native memory。實際上Java執行時本身也依賴於JNI程式碼來實現類庫功能,如檔案操作、網路I/O操作或者其他系統呼叫。所以JNI也會增加Java執行時的本機記憶體佔用。
8.5.2java中的記憶體分配詳解
從前面的JVM記憶體結構的分析我們可知,JVM記憶體分配主要基於兩種,分別是堆和棧。先來說說java棧是如何分配的。
java棧的分配是和執行緒繫結在一起的,當我們建立一個執行緒時,很顯然,JVM就會為這個執行緒建立一個新的Java棧,一個執行緒的方法呼叫和返回對應於這個Java棧的壓棧和出棧。當執行緒啟用一個Java方法時,JVM就會線上程額Java堆疊裡新壓入一個幀,這個幀自然成了當前幀。在此方法執行期間,這個幀將用來儲存引數、區域性變數、中間計算過程和其他資料。
棧中主要存放一些基本型別的變數資料(int、short、long、byte、float、double、boolean、char)和物件控制代碼(引用)。存取速度比堆要快,僅次於暫存器,棧資料可以共享。缺點是:存在棧中的資料大小與生存期必須是確定的,這也導致缺乏了其靈活性。缺點是:存在棧中的資料大小與生存期是確定的,這也導致缺乏了其靈活性。
如下這段程式碼:
public void stack(String[] arg) {
String str = "junshan";
if (str.equals("junshan")) {
int i = 3;
while (i > 0) {
long j = 1;
i--;
}
} else {
char b = 'a';
System.out.println(b);
}
}
這段程式碼的stack方法中定義了多個變數,這些變數在執行時需要儲存空間,同時在執行指令時JVM也需要知道操作棧的大小,這些資料都會在javac編譯這段程式碼時就已經確定,下面是這個方法對應的class位元組碼:
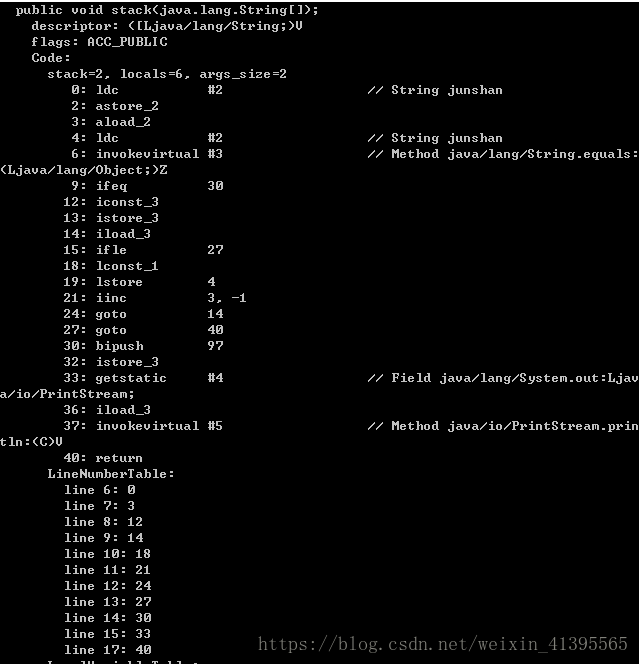
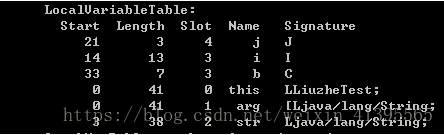
在這個方法的attribute中就已經知道stack和local variable的大小,分別是2和6.還有一點不得不提,就是這裡的大小指定的是最大值,為什麼是最大值呢?因為JVM在真正執行時分配的stack和local variable的空間是可以共用的。舉例來說,上面的6個localvariable除去變數0是this指標外,其他的5個都是在這個方法中定義的,這6個變數需要的Slot是1+1+1+1+2+1,但是實際用到的只有4個,這是因為不同的變數作用範圍如果沒有重合,Slot則可以重複使用。
下面這段程式碼描述物件是如何在堆上分配記憶體的:
public static void main(String[] args) {
new String("hello world");
}
上面的程式碼建立了一個String物件,這個String物件將會在堆上分配記憶體,JVM建立物件的位元組碼指令如下:

先執行new指令,這個new指令根據後面的16位的“#2”常量池索引建立指定型別的物件,而該#2索引所指向的入口型別首先必須是類型別,然後JVM會為這個類的新物件分配一個空間,這個新物件的屬性值都設定為預設值,最後將執行這個新物件的objectref引用壓入棧頂。
new指令執行完成後,得到的物件還沒有初始化,所以這個新物件並沒有建立完成。這個物件的引用在這時不應該複製給str變數,因為invokespecial會消耗掉運算元棧頂的引用作為傳給構造器的“this”引數,所以如果我們希望在invokespecial呼叫後在運算元棧頂還維持有一個指向新建物件的引用,就得在invokespecial之前先“複製”一份引用——這就是這個dup的來源。
在新物件初始化完成後再將這個引用賦值給本地變數。呼叫建構函式是通過invokespecial指令完成的,建構函式如果有引數要傳遞,則先將引數壓棧。建構函式執行完成後再objectref的物件引用賦值為本地變數1,這樣一個新物件才建立完成。
在程式設計中,如C/C++中,所有的方法呼叫都是通過棧來進行的,所有的區域性變數、形式引數都是從棧中非配記憶體空間的。實際上也不是什麼分配,只是從棧頂向上用就行,就好像工廠中的傳送帶一樣,棧指標會自動指引你到放東西的位置,你所要的就是把東西放下來就行。在退出函式時,修改棧指標就可以把棧中的內容銷燬。這樣的模式速度最快。、
堆在應用程式執行時請求作業系統給自己分配記憶體,由於作業系統管理記憶體分配,所以在分配和銷燬時都要佔用時間,因此用哦個堆的效率非常低。但是堆的優點在於,編譯器不必知道要從堆裡分配多少儲存空間,也不必知道儲存的資料在堆裡停留多長時間,因此,用堆儲存資料時會得到更大的靈活性。當然,為達到靈活性,必然也會付出一定代價——在堆裡分配儲存空間時會花掉更長的時間。
8.6垃圾回收
8.6.3如何檢測垃圾
不能通過跟物件可達的就是垃圾物件,那麼這個跟物件集合中都是些什麼呢?雖然跟物件和JVM的具體實現也有關係,但是大都會包含如下一些元素。
- 在方法中區域性變數區的物件的引用:這些跟物件直接儲存在棧幀的區域性變數區中。
- 在Java操作棧中的物件引用:有些物件是直接在操作棧中持有的,所以操作棧肯定也包含根物件集合。
- 在metadata space元資料區中的物件引用。
- 在本地方法中持有的物件引用:有些物件被傳入本地方法中,但是這些物件還麼有被釋放。
- 類的Class物件:當每個類被JVM載入時都會建立一個代表這個類的唯一資料型別的Class物件,而這個Class物件也同樣存放在堆中,而這個類不再被使用時,metadata space中類資料和這個Class物件同樣需要被回收。
暫存器
棧
堆
方法區
本地方法棧
常量池
分配策略

記憶體回收策略:
靜態記憶體分配與回收:編譯時確定
動態記憶體分配與回收:執行時確定
檢測垃圾:
根可達,活動物件
分代垃圾收集:
在young區的survivor中進行from———— to的替換
收集演算法:
一、serial collector
二、 parallel collector
1、ParNewGC
2、parallelGC
3、parallelOldGC
三、CMS collector

問題分析:
1、GC日誌分析
2、堆快照檔案分析
3、JVMCrash日誌分析
