
提升方法總結
1. Boosting
提升方法通過改變訓練樣本權重,學習多個分類器,並將分類器線性組合提高分類效能。Boosting需要做到兩件事,一是在每一輪如何改變訓練資料的權值或概率分佈;二是如何將弱分類器組合成一個強分類器。
2. AdaBoost
為了解決Boosting的兩個要求,adaboost在每一輪提高被錯分的樣本的權值,降低正確分類樣本的權值。在組合分類器的時候,給誤分率小的分類器較大權值,誤分率大的分類器較小權值。一句話概括adaboost就是用樣本權值計算分類器的權值,再用分類器的權值去更新樣本的權值。
AdaBoost的過程如下:
輸入:訓練資料集T ={(x1, y1), (x2, y2), ..., (xN, yN)},其中xi∈X⊆Rn,yi∈Y={-1, +1};
輸出:最終分類器G(x)
1. 初始化訓練資料的權值分佈
2. 在每一輪訓練中,設當前訓練到第m輪
(a) 使用帶權訓練資料學習,得到該輪的基本分類器 G_m(x):X->(-1,1)
(b) 計算當前分類器的誤分類率
(c) 計算當前分類器G_m的權值
(d) 更新樣本的權值
觀察上式,Z_m是的歸一化因子,e是自然對數,e的指數其實就是
的正負項,可以驗證當分類正確的時候指數是負的,當分類錯誤的時候指數是正的,這樣就有對誤分的樣本增大權值,對分類正確的樣本減小權值的效果。
3. 最終分類器是每輪分類器的加權線性組合
adaboost的本質
adaboost是模型為加法模型,損失函式為指數函式,學習演算法為前向分步演算法時的二類分類學習方法。
解釋:http://breezedeus.github.io/2015/07/12/breezedeus-adaboost-exponential-loss.html
3. GBDT
梯度提升樹(Gradient Boosting Decison Tree),和adaboost一樣也是迭代模型,使用了前向分佈演算法,但是弱學習器限定了只能使用CART迴歸樹模型。在迭代的過程中,當前的分類器目標是擬合前一輪分類器的殘差。下面是一個預測年齡的例子,我們限定樹只能有兩層,第一輪預測了15和25(預測值是子節點樣本的均值),第二輪預測的是第一輪的殘差。最後的預測結果是所有樹預測的和。

GBDT過程:
1. 初始化分類器
2. 對迭代1,2....T輪:
(a) 樣本1,2,...m,計算負梯度。注意負梯度是t-1輪模型的負梯度,我們用t-1的負梯度來生成第t輪的樹
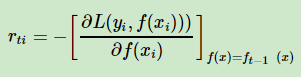
之所以是計算負梯度,和損失函式有關,GBDT常用的損失函式有均方差、絕對損失等,以均方差損失函式為例
梯度是,負梯度正好是預測的殘差,所以說GBDT擬合殘差就是在擬合負梯度
(b) 利用擬合CART迴歸樹,得到第t輪的迴歸樹T
(c) 更新模型
(d) 輸出模型
GBDT分類
由於GBDT使用的是cart迴歸樹,而分類的標籤是離散的標籤,所以實現方法和迴歸不同。分類的GBDT常用損失函式有指數函式和對數損失。當用指數損失函式的時候,GBDT退化為adaboost
當用對數釋然函式的時候,用預測概率和真實概率的差來擬合損失
參考
https://zhuanlan.zhihu.com/p/31639299
https://blog.csdn.net/herr_kun/article/details/81139457
https://www.jianshu.com/p/005a4e6ac775 引數設定
https://www.zhihu.com/question/63560633
https://zhuanlan.zhihu.com/p/25257856