
4、指標&陣列&切片
1、指標
引入:
指標對於效能的影響是不言而喻的,如果你想要做的是系統程式設計、作業系統或者網路應用,指標更是不可或缺的一部分。Go 語言為程式設計師提供了控制資料結構的指標的能力;但是,你不能進行指標運算。
程式在記憶體中儲存它的值,每個記憶體塊(或字)有一個地址,通常用十六進位制數表示,如:0x6b0820,而一個指標變數指向了一個值的記憶體地址。
Go 語言的取地址符是 &;*號來獲取指標所指向的內容,這裡的*號是一個型別更改器。
//一個指標變數在32位機器上佔用4個位元組,在64位機器上佔用8個位元組,並且與它所指向的值的大小無關。當然,可以宣告指標指向任何型別的值來表明它的原始性或結構性;go指標類似於java中的引用。指標建立後,被指向的變數也儲存在記憶體中,直到沒有任何指標指向它們,所以從它們被建立開始就具有相互獨立的生命週期。 一個指標導致的間接引用(一個程序執行了另一個地址),指標的過度頻繁使用也會導致效能下降。
指標的應用:
☆定義一個指標陣列來儲存地址
☆Go 支援指向指標的指標:
可以進行任意深度的巢狀,導致你可以有多級的間接引用,但在大多數情況這會使你的程式碼結構不清晰。
☆通過引用或地址傳參,在函式呼叫時可以改變其值:
這樣不會傳遞變數的拷貝。指標傳遞是很廉價的,只佔用 4 個或 8 個位元組。當程式在工作中需要佔用大量的記憶體,或很多變數,或者兩者都有,使用指標會減少記憶體佔用和提高效率。
2、陣列與切片slice
陣列:
陣列是由一個固定長度的特定型別元素組成的序列,一個數組可以由零個或多個元素組成,陣列元素可以重新賦值。陣列的每個元素都可以通過下標來訪問。元素的數目,也稱為長度或者陣列大小必須是固定的並且在宣告該陣列時就給出(編譯時需要知道陣列長度以便分配記憶體);陣列長度最大為 2Gb。
宣告格式:
var name [size]type
name2 :=[…]int{1,2,3} // 陣列長度根據初始化值的個數來計算(成為切片?)
name3 :=[…]int{99:-1} // 定義一個含有100個元素的陣列,最後一個元素被初始化為-1,其他元素為0
name4 :=[10]{1,2,3} // 從左邊起開始忽略,除了前三個元素外其他元素都為0。
name5 :=new([5]int) // 陣列是值型別,可以通過new函式建立,返回其指標
//陣列長度也是陣列型別的一個組成部分
a :=[3]int{1,2,3}//初始化陣列中 {} 中的元素個數不能大於 [] 中的數字
a=[4]int{1,2,3,4}//編譯錯誤,型別不同
var arr=new([5]int)//型別:*[5]int
arr2:=*arr1
arr2[2]=100
陣列的初始化與遍歷:
//使用for迴圈賦值與遍歷
func main(){
var arr [5]int
for i:=0;i<len(arr);i++{
arr[i]=i*2
}
for i:=0;i<len(arr);i++{
fmt.Printf("index is %d ,value is %d",i,arr[i])
}
}
//for range方式
func main(){
a := […]{1,2,3}
for i :=range a{
fmt.Println("index: ",i,"value: ",a[i])
}
}
多維陣列:
宣告格式與一位陣列相似:
var a [3][6]int
作為函式引數:
因為函式引數傳遞的機制導致傳遞大的陣列型別將是低效的,並且對陣列引數的任何的修改都是發生在複製的陣列上,並不能直接修改呼叫時原始的陣列變數。go語言可以通過指標來傳遞陣列引數,而且也允許在函式內部修改陣列的值,但是陣列依然是僵化的型別,因為陣列的型別包含了僵化的長度資訊。
切片slice:
切片是一個 長度可變的陣列!
一個slice是一個輕量級的資料結構,提供了訪問陣列子序列(或者全部)元素的功能,而且slice的底層確實引用一個數組物件。一個slice由三個部分構成:指標、長度和容量。長度不能超過容量,容量一般是從slice的開始位置到底層資料的結尾位置(容量即陣列的長度)。內建的len和cap函式分別返回slice的長度和容量。多個slice之間可以共享底層的資料,並且引用的陣列部分割槽間可能重疊。
優點:
因為切片是引用,所以它們不需要使用額外的記憶體並且比使用陣列更有效率,所以在 Go 程式碼中 切片比陣列更常
用。
宣告格式:
var r []type // 切片不需要說明長度。未初始化之前預設為 nil,長度為 0。
slice2 := make([]T, length, capacity)// 使用make()函式來建立切片,capacity是可選引數;make(T) 返回一個型別為 T 的初始值,它只適用於3種內建的引用型別:切片、map 和 channel
s :=[] int {1,2,3 } //直接初始化切片,[]表示是切片型別,{1,2,3}初始化值依次是1,2,3.其cap=len=3
s := arr[:] //初始化切片s,是陣列arr的引用
s := arr[startIndex:endIndex] //將arr中從下標startIndex到endIndex-1 下的元素建立為一個新的切片
s := arr[startIndex:] //與string字串截斷類似
s := arr[:endIndex]
s :=make([]int,len,cap)
示意圖:
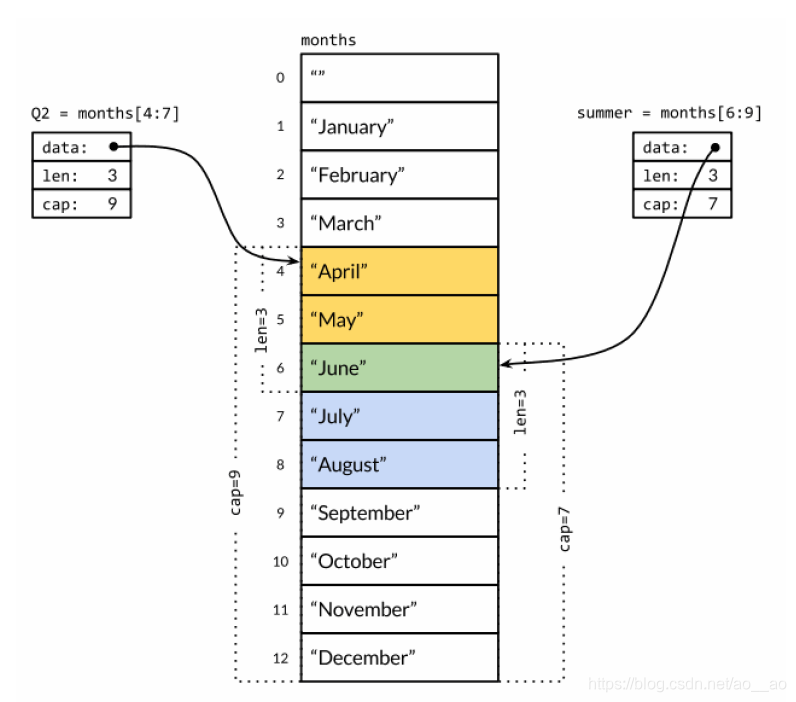
moth是一個數組;slice值包含指向第一個slice元素的指標。(複製一個slice只是對底層的陣列建立了一個新的slice別名)(絕對不要用指標指向 slice。slice並不是一個純粹的引用型別)
切片的比較:
只能與nil相比較,原因:第一個原因,一個slice的元素是間接引用的,一個slice甚至可以包含自身。第二個原因,因為slice的元素是間接引用的,一個固定值的slice在不同的時間可能包含不同的元素,因為底層陣列的元素可能會被修改。如果你需要測試一個slice是否是空的,使用len(s) == 0來判斷,而不應該用s == nil來判斷。除了文件已經明確說明的地方,所有的Go語言函式應該以相同的方式對待nil值的slice和0長度的slice。
內建函式:
func main(){
s := []int{1}
s=append(s,2,3,4,5,6,)//append追加元素
copy(s,s1)//copy複製,兩個slice可以共享同一個底層陣列,甚至有重疊也沒有問題。
fmt.Println(s1)
sl = sl[0:len(sl)+1]//改變切片長度的過程稱之為切片重組 reslicing
}
多維切片:
切片通常也是一維的,但是也可以由一維組合成高維。通過分片的分片(或者切片的陣列),長度可以任意動態變化,所以 Go 語言的多維切片可以任意切分。而且,內層的切片必須單獨分配(通過 make 函式)。
典例bytes包:
讀寫長度未知的 bytes 最好使用bytes包中的buffer型別,這種實現方式比使用 += 要更節省記憶體和 CPU,尤其是要串聯的字串數目特別多的時候。此型別有Read 和 Write 方法。
var buffer bytes.Buffer//宣告
var r *bytes.Buffer = new(bytes.Buffer)//獲取指標
var buffer bytes.Buffer
for {
if s, ok := getNextString(); ok { //method getNextString() not shown here
buffer.WriteString(s)
} else {
break
}
}
fmt.Print(buffer.String(), "\n")
For——range結構:
這種結構常用於陣列和切片
for index,value :=range slice{}//第一個返回值是陣列或者切片的索引,第二個是在該索引位置的值;他們都是僅在 for 迴圈內部可見的區域性變數。value 只是 slice 某個索引位置的值的一個拷貝,不能用來修改 slice 該索引位置的值。
應用:
☆從字串生成位元組切片:
假設 s 是一個字串(本質上是一個位元組陣列),那麼就可以直接通過 c := []byte(s) 來獲取一個位元組的切片 c。還可以通過 copy 函式來達到相同的目的: copy(dst []byte, src string) 。由於Unicode 字元會佔用 2 個位元組,有些甚至需要 3 個或者 4 個位元組來進行表示。如果發現錯誤的 UTF8 字元,可以使用 c := []int32(s) 語法,這樣切片中的每個 int 都會包含對應的 Unicode 程式碼,因為字串中的每次字元都會對應一個整數。類似的,您也可以將字串轉換為元素型別為 rune 的切片: r := []rune(s) 。可以通過程式碼 len([]int32(s)) 來獲得字串中字元的數量,但使用 utf8.RuneCountInString(s) 效率會更高一點。
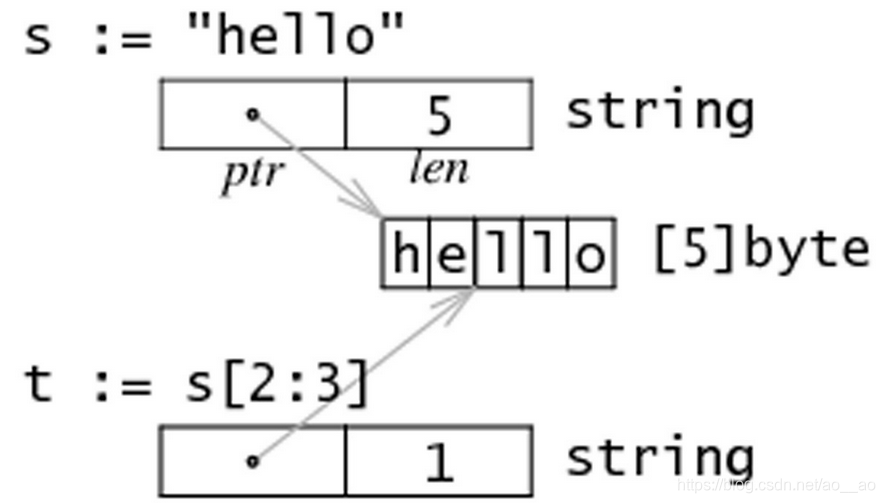
☆字串和切片的記憶體結構:
在記憶體中,一個字串實際上是一個雙字結構,即一個指向實際資料的指標和記錄字串長度的整數。因為指標對使用者來說是完全不可見,因此我們可以依舊把字串看做是一個值型別,也就是一個字元陣列。
☆修改字串中的某個字元:
Go 語言中的字串是不可變的,必須先將字串轉換成位元組陣列,然後再通過修改陣列中的元素值來達到修改字串的目的,最後將位元組陣列轉換回字串格式。
s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) // s2 == "cello"
☆搜尋及排序切片和陣列:
標準庫提供了 sort 包來實現常見的搜尋和排序操作。您可以使用 sort 包中的函式 func Ints(a []int) 來實現對 int型別的切片排序,為了檢查某個陣列是否已經被排序,可以通過函式 IntsAreSorted(a []int) bool 來檢查,如果返回 true 則表示已經被排序。類似的,可以使用函式 func Float64s(a []float64) 來排序 float64 的元素,或使用函式 func Strings(a []string) 排序字串元素。
想要在陣列或切片中搜索一個元素,該陣列或切片必須先被排序(因為標準庫的搜尋演算法使用的是二分法)。然後可以使用函式 func SearchInts(a []int, n int) int 進行搜尋,並返回對應結果的索引值。
☆切片和垃圾回收:
切片的底層指向一個數組,該陣列的實際容量可能要大於切片所定義的容量。只有在沒有任何切片指向的時候,底層的陣列記憶體才會被釋放,這種特性有時會導致程式佔用多餘的記憶體。