
rank() over, dense_rank(), row_number() 的區別
假設現在有一張學生表student,學生表中有姓名、分數、課程編號,現在我需要按照課程對學生的成績進行排序。
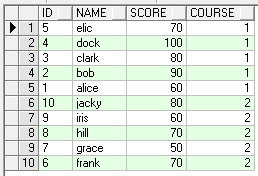
select * from student
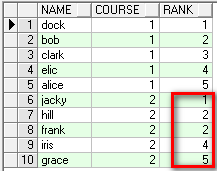
1. rank over ()可以實現對學生排名,特點是成績相同的兩名是並列,如下1 2 2 4 5
select name,
course,
rank() over(partition by course order by score desc) as rank
from student;
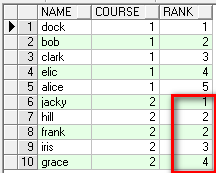
2. dense_rank()和rank over()很像,但學生成績並列後並不會空出並列所佔的名次,如下1 2 2 3 4
select name,
course,
dense_rank() over(partition by course order by score desc) as rank
from student;
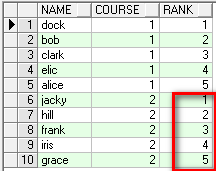
3. row_number這個函式不需要考慮是否並列,那怕根據條件查詢出來的數值相同也會進行連續排名
select name,
course,
row_number() over(partition by course order by score desc) as rank
from student;
答疑:
1. partition by用於給結果集進行分割槽。
2. partition by和group by有何區別?
partition by只是將原始資料進行名次排列(記錄數不變)
group by是對原始資料進行聚合統計(記錄數可能變少, 每組返回一條)
3. 使用rank over()的時候,空值是最大的,如果排序欄位為null, 可能造成null欄位排在最前面,影響排序結果。
可以這樣: rank over(partition by course order by score desc nulls last)
--------------------- 本文來自 zdp072 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/zdp072/article/details/45075293?utm_source=copy