
python+scrapy爬取鬥魚圖片
阿新 • • 發佈:2018-11-11
建立scrapy的專案請參考:https://blog.csdn.net/qq_35723619/article/details/83614670
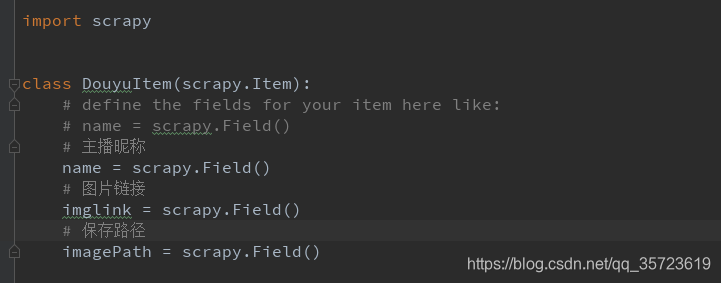
items的實現:
DouyumeinvSpider建立:
這次我們爬去的是json資料包:我們可以通過network監控: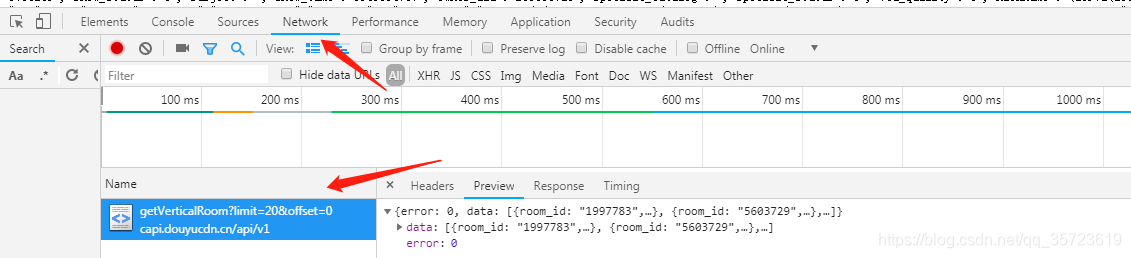
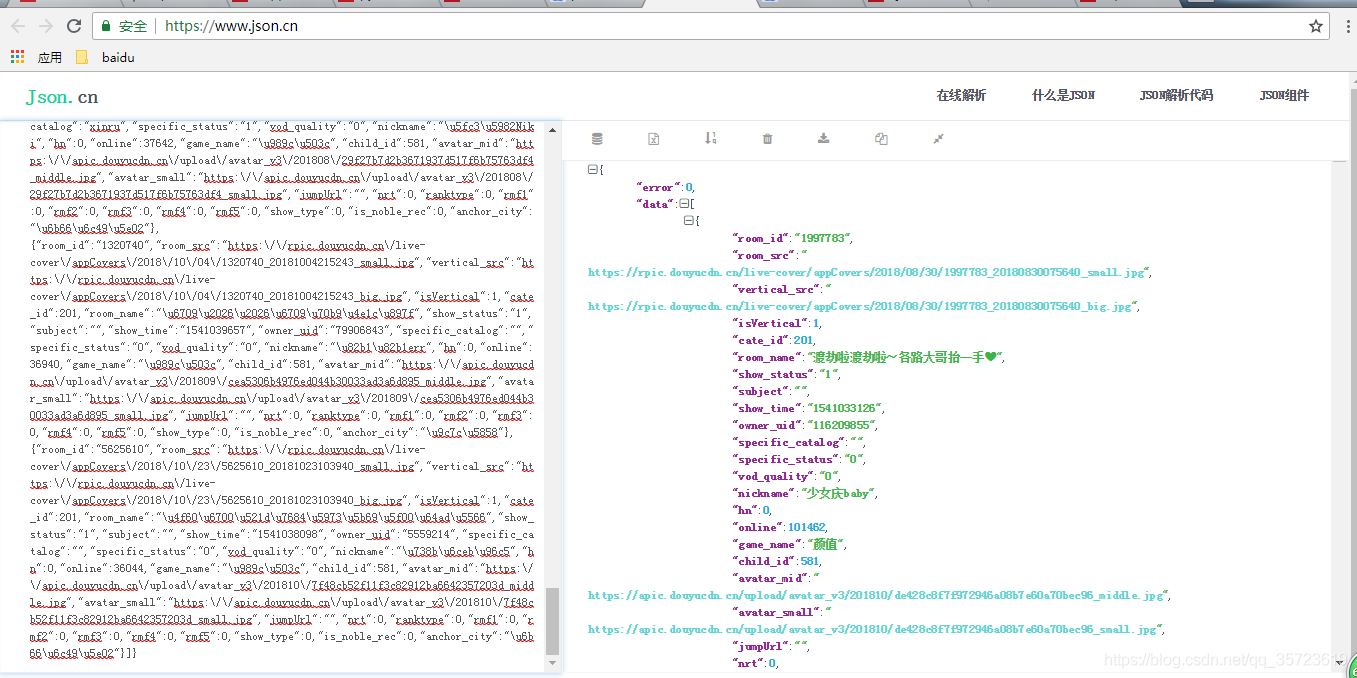
# -*- coding: utf-8 -*- import scrapy import json from douyu.items import DouyuItem class DouyumeinvSpider(scrapy.Spider): name = 'douyumeinv' allowed_domains = ['capi.douyucdn.cn'] offset = 0 url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=" start_urls = [url + str(offset)] def parse(self, response): data = json.loads(response.text)['data'] for each in data: item = DouyuItem() item['name'] = each['nickname'] item['imglink'] = each['vertical_src'] yield item self.offset += 20 yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
配置setting
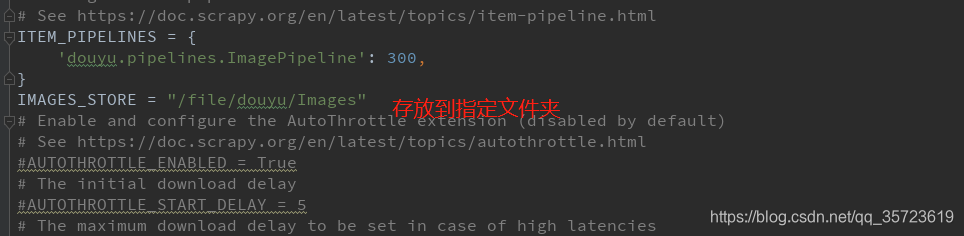
建立ImagePipeline我們這裡繼承了scrapy處理圖片的ImagesPipeline重新構建
get_media_requests(self, item, info)和item_completed(self, results, item, info)方法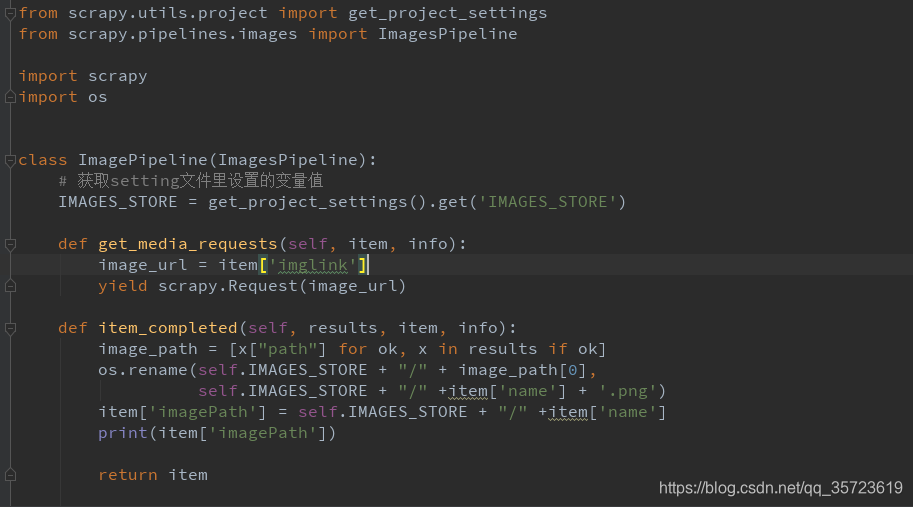
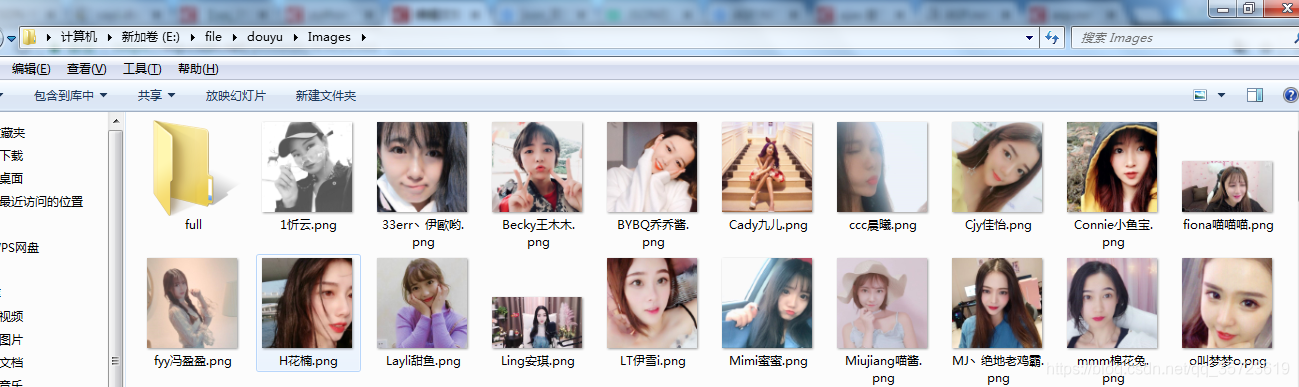
執行結果:
謝謝瀏覽!!!!