
python 讀取excel中單元格的內容
阿新 • • 發佈:2018-11-11
python 讀取excel中單元格的內容
excel檔案內容:
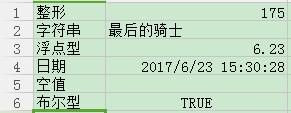
讀取excel程式碼:
# coding=utf-8 import xlrd import sys reload(sys) sys.setdefaultencoding('utf-8') import traceback class excelHandle: def decode(self, filename, sheetname): try: filename = filename.decode('utf-8') sheetname = sheetname.decode('utf-8') except Exception: print traceback.print_exc() return filename, sheetname def read_excel(self, filename, sheetname): filename, sheetname = self.decode(filename, sheetname) rbook = xlrd.open_workbook(filename) sheet = rbook.sheet_by_name(sheetname) rows = sheet.nrows cols = sheet.ncols all_content = [] for i in range(rows): row_content = [] for j in range(cols): cell = sheet.cell_value(i, j) row_content.append(cell) all_content.append(row_content) print '[' + ','.join("'" + str(element) + "'" for element in row_content) + ']' return all_content if __name__ == '__main__': eh = excelHandle() filename = r'G:\test\ctype.xls' sheetname = 'Sheet1' eh.read_excel(filename, sheetname)
輸出 結果:
['整形','175.0']
['字串','最後的騎士']
['浮點型','6.23']
['日期','42909.6461574']
['空值','']
['布林型','1']可以看到,數字一律按浮點型輸出,日期卻輸出成一串小數?!布林型輸出0或1
程式碼稍做改動:來看一看錶格的資料型別
for i in range(rows): row_content = [] for j in range(cols): ctype = sheet.cell(i, j).ctype #表格的資料型別 print ctype, cell = sheet.cell_value(i, j) row_content.append(cell) all_content.append(row_content) print print '[' + ','.join("'" + str(element) + "'" for element in row_content) + ']'
輸出:
2
['整形','175.0']
1
['字串','最後的騎士']
2
['浮點型','6.23']
3
['日期','42909.6461574']
0
['空值','']
4
['布林型','1']python讀取excel中單元格的內容返回的有5種類型,即上面例子中的ctype:
ctype: 0 empty,
1 string,
2 number,
3 date,
4 boolean,
5 error
所以,判斷一下ctype,然後再做相應處理就可以了。
最終的程式碼:
# coding=utf-8 import xlrd import sys reload(sys) sys.setdefaultencoding('utf-8') import traceback from datetime import datetime from xlrd import xldate_as_tuple class excelHandle: def decode(self, filename, sheetname): try: filename = filename.decode('utf-8') sheetname = sheetname.decode('utf-8') except Exception: print traceback.print_exc() return filename, sheetname def read_excel(self, filename, sheetname): filename, sheetname = self.decode(filename, sheetname) rbook = xlrd.open_workbook(filename) sheet = rbook.sheet_by_name(sheetname) rows = sheet.nrows cols = sheet.ncols all_content = [] for i in range(rows): row_content = [] for j in range(cols): ctype = sheet.cell(i, j).ctype # 表格的資料型別 cell = sheet.cell_value(i, j) if ctype == 2 and cell % 1 == 0: # 如果是整形 cell = int(cell) elif ctype == 3: # 轉成datetime物件 date = datetime(*xldate_as_tuple(cell, 0)) cell = date.strftime('%Y/%d/%m %H:%M:%S') elif ctype == 4: cell = True if cell == 1 else False row_content.append(cell) all_content.append(row_content) print '[' + ','.join("'" + str(element) + "'" for element in row_content) + ']' return all_content if __name__ == '__main__': eh = excelHandle() filename = r'G:\test\ctype.xls' sheetname = 'Sheet1' eh.read_excel(filename, sheetname)
輸出:
['整形','175']
['字串','最後的騎士']
['浮點型','6.23']
['日期','2017/23/06 15:30:28']
['空值','']
['布林型','True']更多操作excel可參考:http://www.2cto.com/kf/201501/373655.html
希望對你有幫助!
作者:夜雨西風 致敬
原文地址:http://www.2cto.com/kf/201501/373655.html