
Python BeautifulSoup 爬蟲入門筆記 --- 新聞爬蟲
BeautifulSoup可以解析html檔案,配合request庫可以簡單快速地爬取一些網頁資訊。
BeautifulSoup 參考資料:
https://blog.csdn.net/maverick17/article/details/79610050
https://www.crummy.com/software/BeautifulSoup/bs3/documentation.zh.html
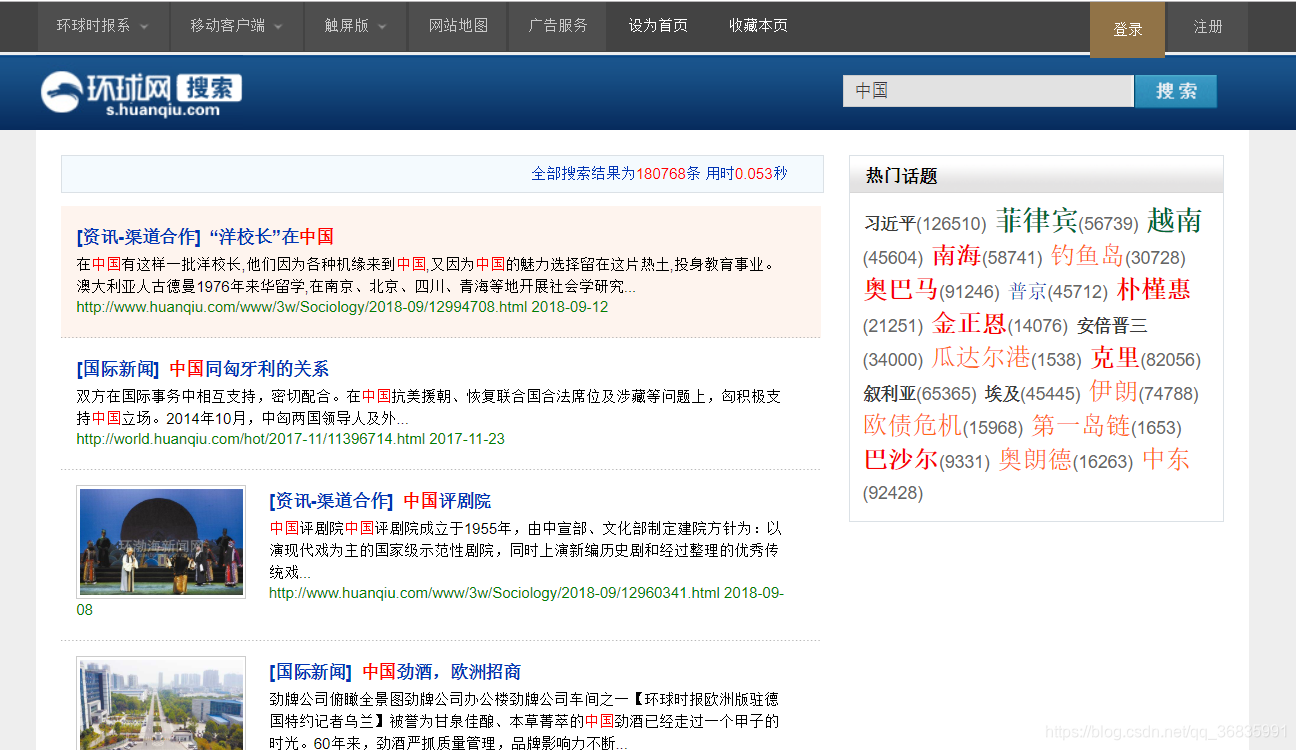
如下圖所示,以爬取環球網中國新聞為例,我們需要與“中國”有關的新聞的標題和正文:
首先根據Python中的request庫,定義一個頁面請求函式,該函式可以返回url對應的html頁面的內容:
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print(url)
print("failed") 然後分析網頁結構:
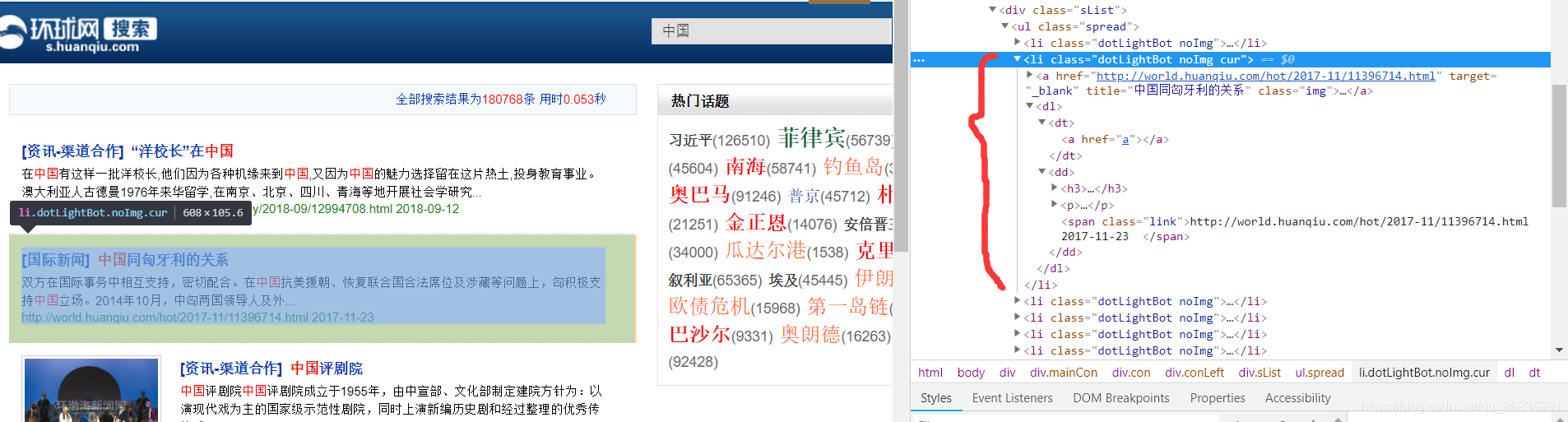
該頁面是一個搜尋結果頁面,所有的搜尋結果都是一個<li>標籤,並且類名為dotLightBot,並且該標籤下的第一個<a>標籤儲存了該條新聞的連結和標題資訊。那麼定義一個函式爬取該搜尋結果下所有新聞的標題和連結。這裡可使用BeautifulSoup中的html.parser解析頁面內容,根據findAll()、find_all()、find()、select()等一系列函式篩選找到我們所需內容的標籤,然後使用get_text()
a['href']直接取得標籤中的屬性值,將其整合成列表後返回。
def findUrls(html):
ulist = []
soup = BeautifulSoup(html, "html.parser")
for item in soup.findAll("li", attrs={"class": "dotLightBot"}):
# 忽略掉圖集新聞
if "圖集" in item.get_text():
continue
a = item.find('a')
try:
ulist.append({'title': a['title'], 'href': a['href']})
except:
print(item)
print(a)
return ulist
此時可得到一系列新聞標題及其對應的超連結,但是我們需要得到新聞的正文,因此需要根據得到的連結再爬取新聞正文,開啟一條新聞的連結對頁面進行分析:
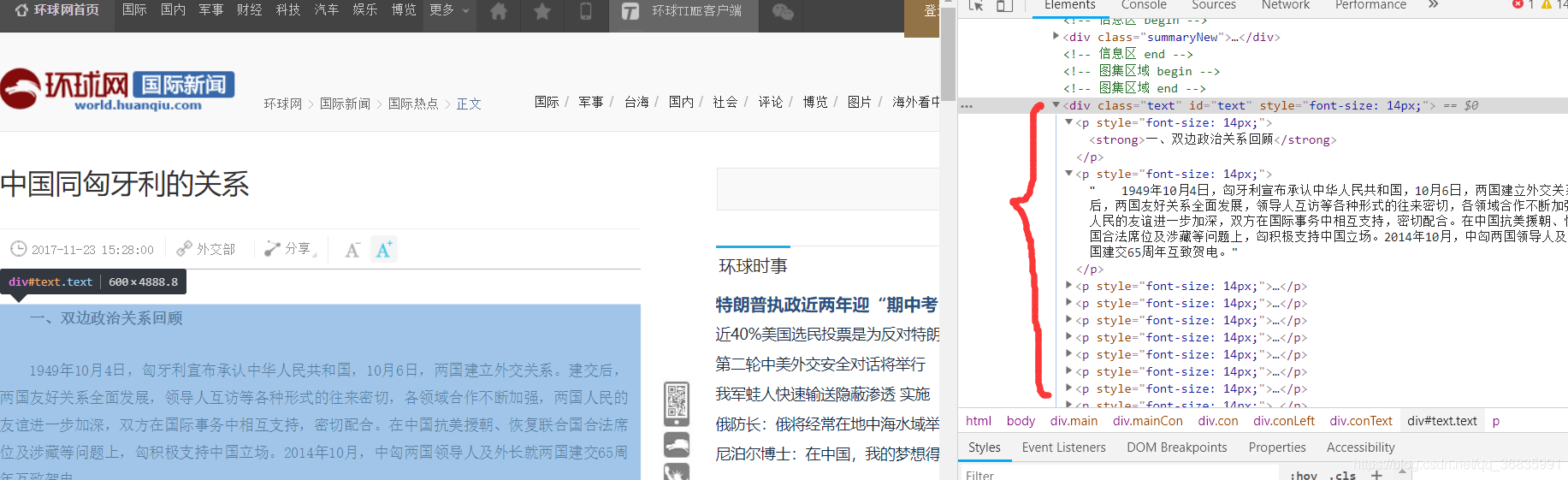
可以發現正文內容均被封裝在id和class都為text的<div>下的<p>標籤中,此時可根據id或類名篩選出所需<div>即可(最好根據所需標籤的唯一屬性進行設定篩選條件,如果同時得到了其他不需要的標籤,需要進一步篩選)。
所以可定義一個函式爬取之前獲得的新聞連結裡的正文內容,首先訪問新聞連結,然後篩選得到所需標籤,獲取其文字內容,然後將其拼接或其他處理即可。
在這個函式中,我將其正文中的空格和回車刪除,拼接成了一長段話。考慮到小標題或者一些其他沒有結尾符的段落,則拼接時對其加上一個句號,防止產生的句子不通順。
def findArticles(ulist):
atlist = []
for url in ulist:
ht = getHTMLText(url['href'])
soup = BeautifulSoup(ht, "html.parser")
# 刪除掉所有的指令碼標籤
[s.extract() for s in soup('script')]
for item in soup.select(".text"):
text = item.get_text().split()
ends = ('。', '?', '!', '。”',"?”", "!”")
article = ""
for s in text:
if s=="":
continue
if s.endswith(ends):
article += s
else:
article += s + '。'
at = {'title': url['title']}
at['article'] = article
if at['article']!="" and at['title']!="":
atlist.append(at)
return atlist
在這個過程中有一個小問題,比如使用a.get_text()或者a.string都可以獲取標籤內容,但是如果該標籤下仍有子標籤,a.string將會報錯,get_text()會將子標籤的內容一起返回。
最後,翻頁時只需要修改初始url即可,一般網站搜尋結果的分頁顯示都是url中的一個page引數遞增記錄的。爬取99頁搜尋結果,並且將所有內容轉化成json檔案,得到結果如下:

所有程式碼如下:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import bs4
import json
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print(url)
print("failed")
return ""
def findUrls(html):
ulist = []
soup = BeautifulSoup(html, "html.parser")
for item in soup.findAll("li", attrs={"class": "dotLightBot"}):
# 忽略掉圖集新聞
if "圖集" in item.get_text():
continue
a = item.find('a')
try:
ulist.append({'title': a['title'], 'href': a['href']})
except:
print(item)
print(a)
return ulist
def findArticles(ulist):
atlist = []
for url in ulist:
ht = getHTMLText(url['href'])
soup = BeautifulSoup(ht, "html.parser")
# 刪除掉所有的指令碼標籤
[s.extract() for s in soup('script')]
for item in soup.select(".text"):
text = item.get_text().split()
ends = ('。', '?', '!', '。”',"?”", "!”")
article = ""
for s in text:
if s=="":
continue
if s.endswith(ends):
article += s
else:
article += s + '。'
at = {'title': url['title']}
at['article'] = article
if at['article']!="" and at['title']!="":
atlist.append(at)
return atlist
def main():
atlist = []
url = "http://s.huanqiu.com/s/?q=%E4%B8%AD%E5%9B%BD&p="
for i in range(99):
print("page is " + str(i+1))
print("json size is " + str(len(atlist)))
html = getHTMLText(url + str(i+1))
ulist = findUrls(html)
at = findArticles(ulist)
atlist.extend(at)
print(len(atlist))
with open("huanqiu.json","w", encoding='utf-8') as fin:
json.dump(atlist, fin, ensure_ascii=False)
main()