
機器學習基石 Lecture8: Noise and Error
機器學習基石 Lecture8: Noise and Error
Noise and Error
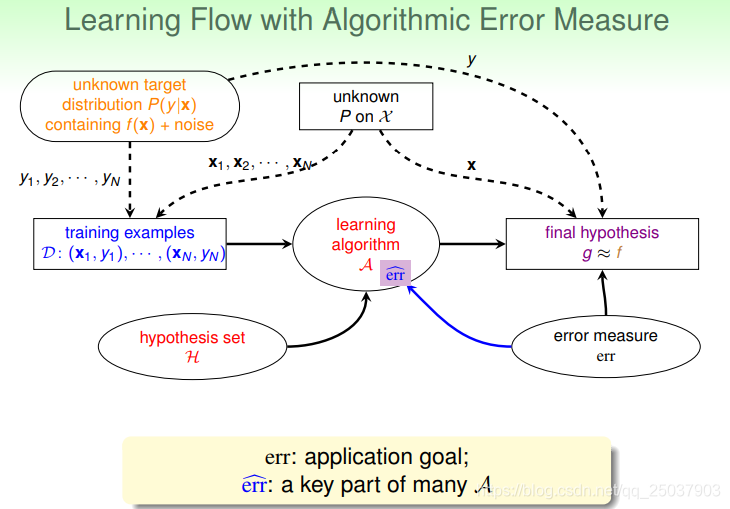
前面講的機器學習的學習流程如下圖所示:
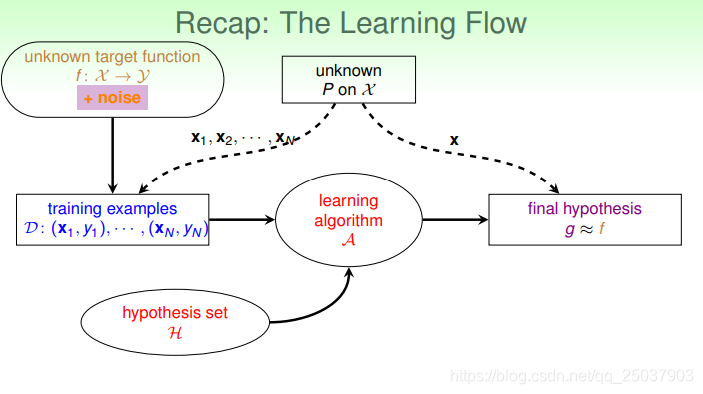
但是這個流程裡假設的都是有一個真實的函式
來生成樣本,但是現實中很有可能樣本里帶有一些噪音,也就是無法單純用一個函式
來刻畫
與
的關係。比如在信用卡問題裡有以下幾種噪音:
- y的噪音:對錶現良好的使用者標記為-1(不發信用卡)
- y的噪音:同樣的使用者不同的標籤
- x的噪音:不準確的使用者資訊
在有噪音的情況下,VC bound的不等式是否依然成立呢?我們可以從頭開始推導,但是要包含有噪音的情況。建模成每個樣本
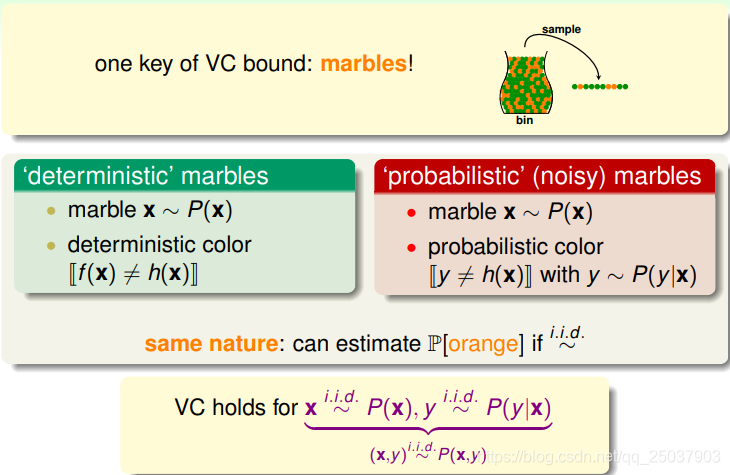
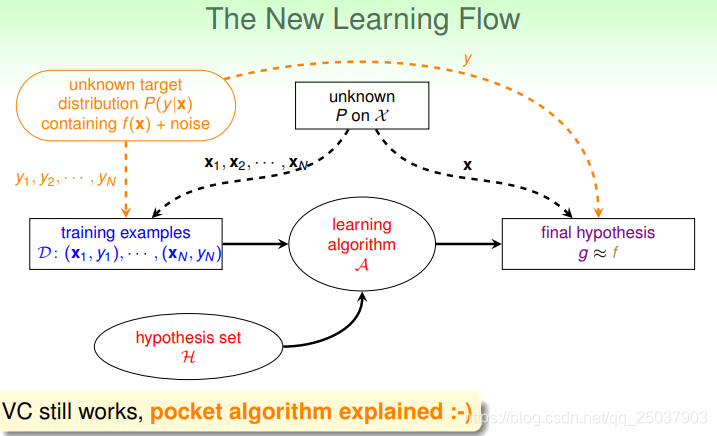
這時候我們機器學習的目標就從學習一個目標函式
變成了學習一個概率分佈
。而對一個給定
有確定性結果
的目標函式
是這樣一個概率分佈的特殊情況。因此我們得到了一個新的機器學習的流程:
Error Measure
當我們得到一個最終的學習結果 的時候需要將其與真實函式 作對比,這樣才能夠知道最終學習到的效果如何。比如之前在PLA裡考慮的在取樣集合之外函式 的錯誤率 就是一種比較方式。更一般的說,這種方式叫做error measure E(g,f)。一般評估錯誤有幾個自然的想法:
- 在資料集外未知的x上測試錯誤率(out-of-sample)

- 在每個單獨的x之上評估再進行平均(pointwise)
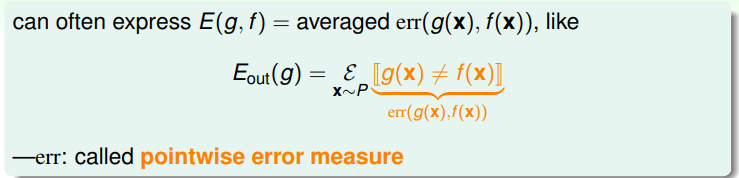
- 使用簡單的是否預測正確來判斷(classification,0/1 error)

0/1 error一般使用在分類中,還有一種重要的error叫做平方誤差,一般用在迴歸中:

比如對於一個簡單的問題而言,使用不同的error就可以針對不同的“最優”的目標函式 :

這樣error measure在機器學習的過程中就能對演算法起到一個引導的作用,引導演算法得到不同的最終結果:

Algorithmic Error Measure
上面的0/1 error中對於不同型別的判斷錯誤同等對待,但是實際應用中不同的錯誤型別可能導致的嚴重後果完全不同。比如如下一個指紋識別的例子。當用在超市會員打折時,false reject可能會導致使用者非常生氣,而false accept導致的結果也沒有很壞。因此可能對不同的錯誤型別賦予不同的權重:

但如果是CIA的指紋識別機,不同的錯誤導致的後果又是與超市完全相反:

因此對於不同的應用場景而言我們會為演算法定義一個新的err來表達對不同錯誤的容忍程度,用
表示(因為和問題裡實際的err有可能還是不一樣)。當定義
時我們需要考慮兩方面,一個是合理性,一個是是否易於實現:

於是對於演算法而言就有了新的
來指導其選擇假設函式,新的機器學習流程如下:
Weighted Classification
對於不同的錯誤分類需要有一個權重來表示它的重要程度,因此新的計算錯誤率的時候需要將係數也加入其中:

於是我們新定義了一個帶權重的集合內錯誤率:
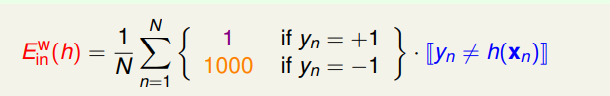
這對於PLA演算法而言沒有影響,因為對於線性可分的資料集,最終得到的結果集合內錯誤率應該是0。但是對於非線性可分的資料集的pocket PLA演算法而言就需要進行對應的修改。修改出現在使用剛更新的
判斷是否需要替代當前最好的係數
的時候。初始的判斷方式是使用集合內的錯誤率
,現在替換為
即可。
但是對於pocket PLA演算法而言,我們能夠保證使用 能得到較好的結果,但是使用 呢?
這個時候只需要將對應錯誤型別的樣例進行正比於係數的虛擬賦值,這樣就將這個使用了
的問題轉化為了一個使用了
錯誤的問題:

轉化之後的問題是當前已經解決的問題,因此對於這個形式的err,pocket PLA演算法的結果也能得到保證。轉化後的問題為:

最後注意一個習題,習題表明了對於正負例比例嚴重失調的時候,使用帶權重的錯誤能夠用來避免演算法只返回一個不變的結果:
