
hashmap技術概覽與擴容在Java7與Java8中的不同實現
hashmap技術概覽:
- 由
陣列 + 連結串列的方式實現,當hash衝突的時候,會將新put值放到連結串列開頭。- 初始化時會初始化容量(capacity)、載入因子(loadfactor)、閾值(threshold),其中
threshold = capacity * loadfactor,預設值分別是:12 = 16*0.75。- 當
count值大於等於閾值(threshold)時,會進行動態擴容,擴容時擴容成原來容量(capacity)的兩倍,並對每個值進行重定位。- Java8後對連結串列進行了優化,如果連結串列長度超過
8,會將連結串列變成紅黑樹。
HashMap大部分的內容是比較好理解的,連結串列的實現是通過一個內部類Node<K,V>實現的:
//實現自Map.Entry<K,V>介面,包含當前值的hash值、key、value、next節點的指標
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//... 省略 ... 這裡我們主要說下在動態擴容時hashmap是怎麼實現的,Java8引入了紅黑樹,擴容方式也換了另一個方法,所以程式碼實現比Java7複雜了不止一倍,但本質差別不大,我們先從7的擴容程式碼resize()來理解擴容的重新定位是如何實現的:
void resize(int newCapacity) { //傳入新的容量
Entry[] oldTable = table; //引用擴容前的Entry陣列
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //擴容前的陣列大小如果已經達到最大(2^30)了 //遍歷每個元素,按新的容量進行rehash,放到新的陣列上
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了舊的Entry陣列
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍歷舊的Entry陣列
Entry<K, V> e = src[j]; //取得舊Entry陣列的每個元素
if (e != null) {
src[j] = null;//釋放舊Entry陣列的物件引用(for迴圈後,舊的Entry陣列不再引用任何物件)
do {
Entry<K, V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新計算每個元素在陣列中的位置
e.next = newTable[i]; //標記[1]
newTable[i] = e; //將元素放在陣列上
e = next; //訪問下一個Entry鏈上的元素
} while (e != null);
}
}
}//呼叫傳入hash值和容量,如:indexFor(e.hash, newCapacity)
static int indexFor(int h, int length) {
return h & (length - 1); //進行與操作,求出,這樣比%求模快,這也是hashmap的容量都是2的次方的原因之一。
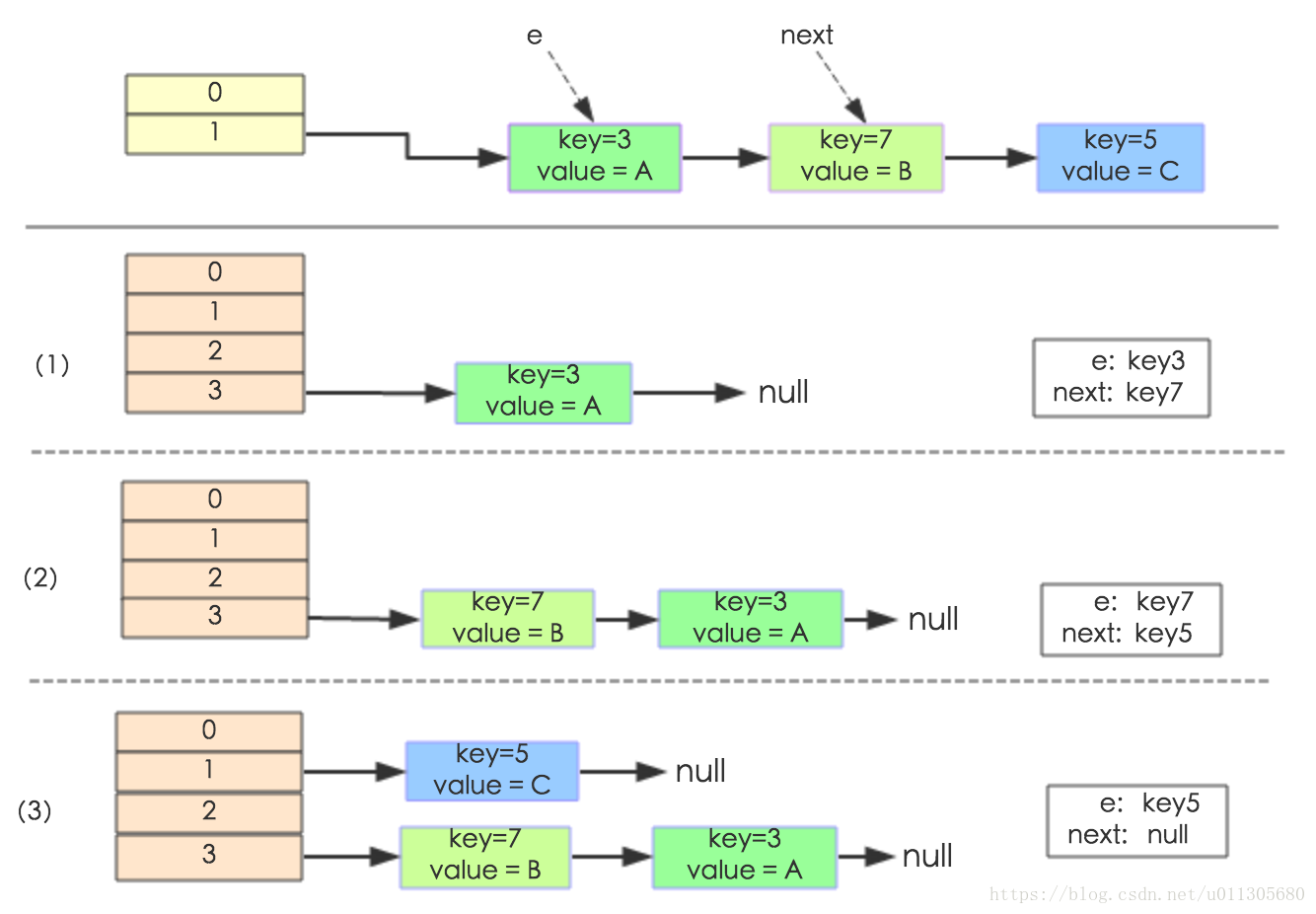
} 其中的雜湊桶陣列table的size=2, 所以key = 3、7、5,put順序依次為 5、7、3。在mod 2以後都衝突在table[1]這裡了。這裡假設負載因子 loadFactor=1,即當鍵值對的實際大小size 大於 table的實際大小時進行擴容。接下來的三個步驟是雜湊桶陣列 resize成4,然後所有的Node重新rehash的過程。
我們再來看下JDK1.8做了哪些優化。經過觀測可以發現,我們使用的是2次冪的擴充套件(指長度擴為原來2倍),所以,經過rehash之後,元素的位置要麼是在原位置,要麼是在原位置再移動2次冪的位置。對應的就是下方的
resize()的註釋。
看下圖可以明白這句話的意思,n為table的長度,圖(a)表示擴容前的key1和key2兩種key確定索引位置的示例,圖(b)表示擴容後key1和key2兩種key確定索引位置的示例,其中hash1是key1對應的雜湊與高位運算結果。
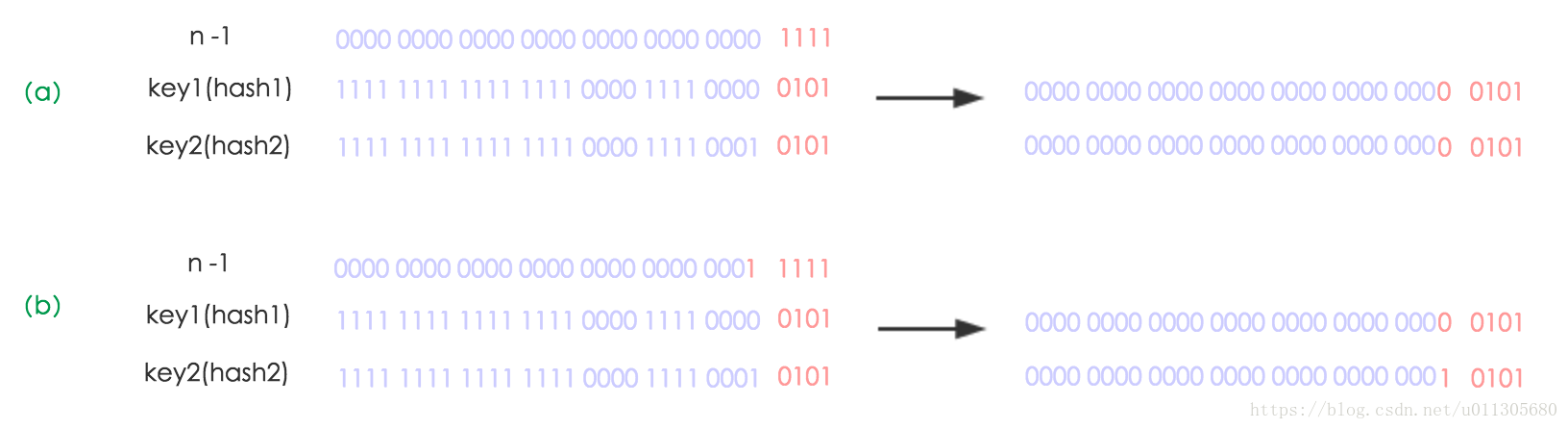
元素在重新計算hash之後,因為n變為2倍,那麼n-1的mask範圍在高位多1bit(紅色),因此新的index就會發生這樣的變化:
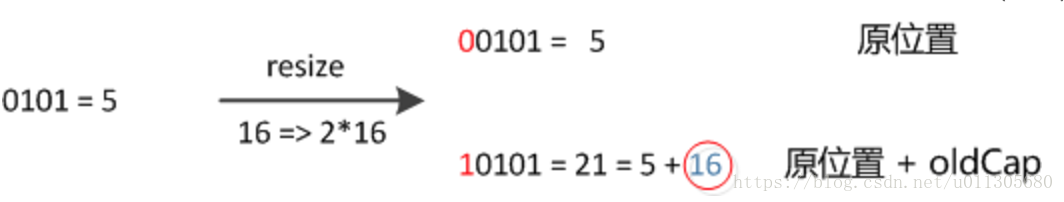
因此,我們在擴充HashMap的時候,不需要像JDK1.7的實現那樣重新計算hash,只需要看看原來的hash值新增的那個bit是1還是0就好了,是0的話索引沒變,是1的話索引變成“原索引+oldCap”,可以看看下圖為16擴充為32的resize示意圖
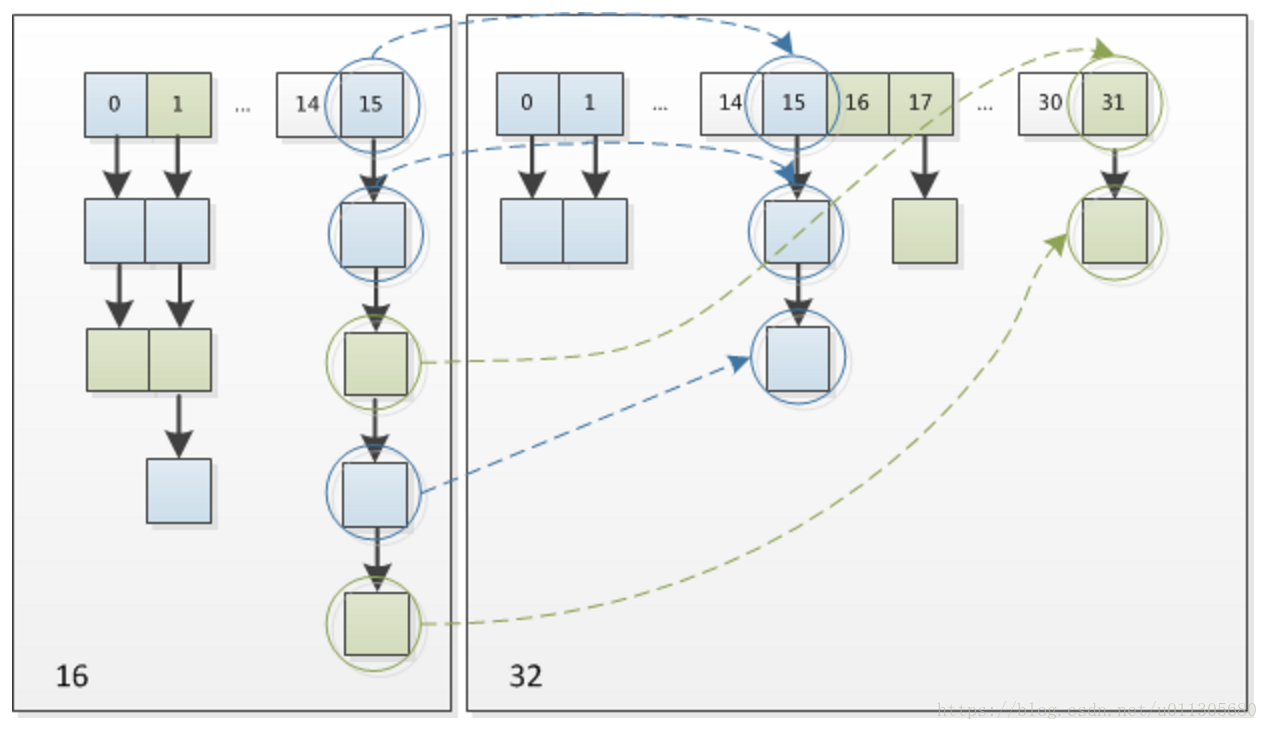
這個設計確實非常的巧妙,既省去了重新計算hash值的時間,而且同時,由於新增的1bit是0還是1可以認為是隨機的,因此resize的過程,均勻的把之前的衝突的節點分散到新的bucket了。這一塊就是JDK1.8新增的優化點。有一點注意區別,JDK1.7中rehash的時候,舊連結串列遷移新連結串列的時候,如果在新表的陣列索引位置相同,則連結串列元素會倒置,但是從上圖可以看出,JDK1.8不會倒置。
Java8 resize()原始碼:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //引用擴容前的node陣列
int oldCap = (oldTab == null) ? 0 : oldTab.length; //舊的容量
int oldThr = threshold; //舊的閾值
int newCap, newThr = 0; //新的容量、閾值初始化為0
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { //如果舊容量已經超過最大容量,讓閾值也等於最大容量,以後不再擴容
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) //如果舊容量翻倍沒有超過最大值,且舊容量不小於初始化容量16,則翻倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold - 初始化容量設定為閾值
newCap = oldThr;
else { // zero initial threshold signifies using defaults - 0的時候使用預設值初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) { //計算新閾值,如果新容量或新閾值大於等於最大容量,則直接使用最大值作為閾值,不再擴容
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; //設定新閾值
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; //建立新的陣列,並引用
//如果老的陣列有資料,也就是是擴容而不是初始化,才執行下面的程式碼,否則初始化的到這裡就可以結束了
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) { //輪詢老陣列所有資料
Node<K,V> e; //以一個新的節點引用當前節點,然後釋放原來的節點的引用
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) //如果e沒有next節點,證明這個節點上沒有hash衝突,則直接把e的引用給到新的陣列位置上
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //!!!如果是紅黑樹,則進行分裂
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do { //從這條連結串列上第一個元素開始輪詢,如果當前元素新增的bit是0,則放在當前這條連結串列上,如果是1,則放在"j+oldcap"這個位置上,生成“低位”和“高位”兩個連結串列
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e; //元素是不斷的加到尾部的,不會像1.7裡面一樣會倒序
loTail = e; //新增的元素永遠是尾元素
}
else { //高位的連結串列與地位的連結串列處理邏輯一樣,不斷的把元素加到連結串列尾部
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) { //低位連結串列放到j這個索引的位置上
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) { //高位連結串列放到(j+oldCap)這個索引的位置上
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}從這裡看,如果沒有紅黑樹,其實1.7與1.8處理邏輯大同小異,區別主要還是在樹節點的分裂((TreeNode<K,V>)e).split() 這個方法上。
//resize時呼叫((TreeNode<K,V>)e).split(this, newTab, j, oldCap);對樹進行擴容或縮容,如果低於閾值會變成連結串列
/**
* Splits nodes in a tree bin into lower and upper tree bins,
* or untreeifies if now too small. Called only from resize;
* see above discussion about split bits and indices.
*
* @param map the map
* @param tab the table for recording bin heads
* @param index the index of the table being split
* @param bit the bit of hash to split on
*/
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this; //當前這個節點的引用,即這個索引上的樹的根節點
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0; //高位低位的初始樹節點個數都設成0
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) { //bit=oldcap,這裡判斷新bit位是0還是1,如果是0就放在低位樹上,如果是1就放在高位樹上,這裡先是一個雙向連結串列
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map); //!!!如果低位的連結串列長度小於閾值6,則把樹變成連結串列,並放到新陣列中j索引位置
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)如果高位樹是空,即整個樹沒變化,那麼樹其實是不用重新調整的
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}//樹轉變為單向連結串列
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}//連結串列轉換為紅黑樹,會根據紅黑樹特性進行平衡、左旋、右旋等
//TODO 這裡不細講了,後續我會寫一篇部落格專講紅黑樹在這裡的實現
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);//對樹進行平衡插入,裡面包括左旋右旋等操作
break;
}
}
}
}
moveRootToFront(tab, root);
}