
Mysql裡的 undo log 和 redo log
轉載自:http://doc.okbase.net/xinysu/archive/259593.html
1 undo
1.1 undo是啥
undo日誌用於存放資料修改被修改前的值,假設修改 tba 表中 id=2的行資料,把Name='B' 修改為Name = 'B2' ,那麼undo日誌就會用來存放Name='B'的記錄,如果這個修改出現異常,可以使用undo日誌來實現回滾操作,保證事務的一致性。
對資料的變更操作,主要來自 INSERT UPDATE DELETE,而UNDO LOG中分為兩種型別,一種是 INSERT_UNDO(INSERT操作),記錄插入的唯一鍵值;一種是 UPDATE_UNDO(包含UPDATE及DELETE操作),記錄修改的唯一鍵值以及old column記錄。
| Id | Name |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
1.2 undo引數
MySQL跟undo有關的引數設定有這些:
1 mysql> show global variables like '%undo%'; 2 +--------------------------+------------+ 3 | Variable_name | Value | 4 +--------------------------+------------+ 5 | innodb_max_undo_log_size | 1073741824 | 6 | innodb_undo_directory | ./ | 7 | innodb_undo_log_truncate | OFF | 8 | innodb_undo_logs | 128 | 9 | innodb_undo_tablespaces | 3 | 10 +--------------------------+------------+ 11 12 mysql> show global variables like '%truncate%'; 13 +--------------------------------------+-------+ 14 | Variable_name | Value | 15 +--------------------------------------+-------+ 16 | innodb_purge_rseg_truncate_frequency | 128 | 17 | innodb_undo_log_truncate | OFF | 18 +--------------------------------------+-------+
- innodb_max_undo_log_size
控制最大undo tablespace檔案的大小,當啟動了innodb_undo_log_truncate 時,undo tablespace 超過innodb_max_undo_log_size 閥值時才會去嘗試truncate。該值預設大小為1G,truncate後的大小預設為10M。
- innodb_undo_tablespaces
設定undo獨立表空間個數,範圍為0-128, 預設為0,0表示表示不開啟獨立undo表空間 且 undo日誌儲存在ibdata檔案中。該引數只能在最開始初始化MySQL例項的時候指定,如果例項已建立,這個引數是不能變動的,如果在資料庫配置文 件 .cnf 中指定innodb_undo_tablespaces 的個數大於例項建立時的指定個數,則會啟動失敗,提示該引數設定有誤。

如果設定了該引數為n(n>0),那麼就會在undo目錄下建立n個undo檔案(undo001,undo002 ...... undo n),每個檔案預設大小為10M.
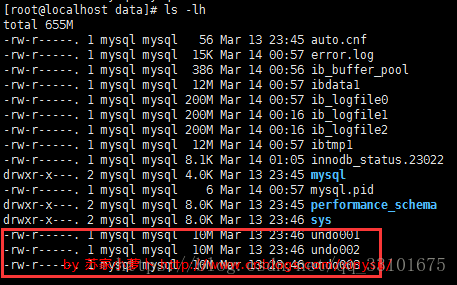
什麼時候需要來設定這個引數呢?
當DB寫壓力較大時,可以設定獨立UNDO表空間,把UNDO LOG從ibdata檔案中分離開來,指定 innodb_undo_directory目錄存放,可以制定到高速磁碟上,加快UNDO LOG 的讀寫效能。
- innodb_undo_log_truncate
InnoDB的purge執行緒,根據innodb_undo_log_truncate設定開啟或關閉、innodb_max_undo_log_size的引數值,以及truncate的頻率來進行空間回收和 undo file 的重新初始化。
該引數生效的前提是,已設定獨立表空間且獨立表空間個數大於等於2個。
purge執行緒在truncate undo log file的過程中,需要檢查該檔案上是否還有活動事務,如果沒有,需要把該undo log file標記為不可分配,這個時候,undo log 都會記錄到其他檔案上,所以至少需要2個獨立表空間檔案,才能進行truncate 操作,標註不可分配後,會建立一個獨立的檔案undo_<space_id>_trunc.log,記錄現在正在truncate 某個undo log檔案,然後開始初始化undo log file到10M,操作結束後,刪除表示truncate動作的 undo_<space_id>_trunc.log 檔案,這個檔案保證了即使在truncate過程中發生了故障重啟資料庫服務,重啟後,服務發現這個檔案,也會繼續完成truncate操作,刪除檔案結束後,標識該undo log file可分配。
- innodb_purge_rseg_truncate_frequency
用於控制purge回滾段的頻度,預設為128。假設設定為n,則說明,當Innodb Purge操作的協調執行緒 purge事務128次時,就會觸發一次History purge,檢查當前的undo log 表空間狀態是否會觸發truncate。
1.3 undo空間管理
如果需要設定獨立表空間,需要在初始化資料庫例項的時候,指定獨立表空間的數量。
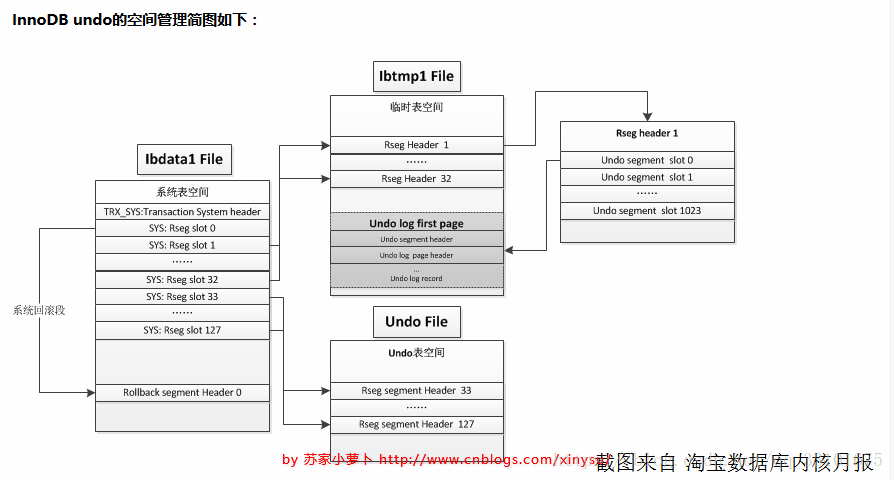
UNDO內部由多個回滾段組成,即 Rollback segment,一共有128個,儲存在ibdata系統表空間中,分別從resg slot0 - resg slot127,每一個resg slot,也就是每一個回滾段,內部由1024個undo segment 組成。
回滾段(rollback segment)分配如下:
- slot 0 ,預留給系統表空間;
- slot 1- 32,預留給臨時表空間,每次資料庫重啟的時候,都會重建臨時表空間;
- slot33-127,如果有獨立表空間,則預留給UNDO獨立表空間;如果沒有,則預留給系統表空間;
回滾段中除去32個提供給臨時表事務使用,剩下的 128-32=96個回滾段,可執行 96*1024 個併發事務操作,每個事務佔用一個 undo segment slot,注意,如果事務中有臨時表事務,還會在臨時表空間中的 undo segment slot 再佔用一個 undo segment slot,即佔用2個undo segment slot。如果錯誤日誌中有:Cannot find a free slot for an undo log。則說明併發的事務太多了,需要考慮下是否要分流業務。
回滾段(rollback segment )採用 輪詢排程的方式來分配使用,如果設定了獨立表空間,那麼就不會使用系統表空間回滾段中undo segment,而是使用獨立表空間的,同時,如果回顧段正在 Truncate操作,則不分配。
2 redo
2.1 redo是啥
當資料庫對資料做修改的時候,需要把資料頁從磁碟讀到buffer pool中,然後在buffer pool中進行修改,那麼這個時候buffer pool中的資料頁就與磁碟上的資料頁內容不一致,稱buffer pool的資料頁為dirty page 髒資料,如果這個時候發生非正常的DB服務重啟,那麼這些資料還沒在記憶體,並沒有同步到磁碟檔案中(注意,同步到磁碟檔案是個隨機IO),也就是會發生資料丟失,如果這個時候,能夠在有一個檔案,當buffer pool 中的data page變更結束後,把相應修改記錄記錄到這個檔案(注意,記錄日誌是順序IO),那麼當DB服務發生crash的情況,恢復DB的時候,也可以根據這個檔案的記錄內容,重新應用到磁碟檔案,資料保持一致。
這個檔案就是redo log ,用於記錄 資料修改後的記錄,順序記錄。它可以帶來這些好處:
- 當buffer pool中的dirty page 還沒有重新整理到磁碟的時候,發生crash,啟動服務後,可通過redo log 找到需要重新重新整理到磁碟檔案的記錄;
- buffer pool中的資料直接flush到disk file,是一個隨機IO,效率較差,而把buffer pool中的資料記錄到redo log,是一個順序IO,可以提高事務提交的速度;
假設修改 tba 表中 id=2的行資料,把Name='B' 修改為Name = 'B2' ,那麼redo日誌就會用來存放Name='B2'的記錄,如果這個修改在flush 到磁碟檔案時出現異常,可以使用redo log實現重做操作,保證事務的永續性。
| Id | Name |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
這裡注意下redo log 跟binary log 的區別,redo log 是儲存引擎層產生的,而binary log是資料庫層產生的。假設一個大事務,對tba做10萬行的記錄插入,在這個過程中,一直不斷的往redo log順序記錄,而binary log不會記錄,知道這個事務提交,才會一次寫入到binary log檔案中。binary log的記錄格式有3種:row,statement跟mixed,不同格式記錄形式不一樣。
2.2 redo 引數
- innodb_log_files_in_group
redo log 檔案的個數,命名方式如:ib_logfile0,iblogfile1... iblogfilen。預設2個,最大100個。
- innodb_log_file_size
檔案設定大小,預設值為 48M,最大值為512G,注意最大值指的是整個 redo log系列檔案之和,即(innodb_log_files_in_group * innodb_log_file_size )不能大於最大值512G。
- innodb_log_group_home_dir
檔案存放路徑
- innodb_log_buffer_size
Redo Log 快取區,預設8M,可設定1-8M。延遲事務日誌寫入磁碟,把redo log 放到該緩衝區,然後根據 innodb_flush_log_at_trx_commit引數的設定,再把日誌從buffer 中flush 到磁碟中。
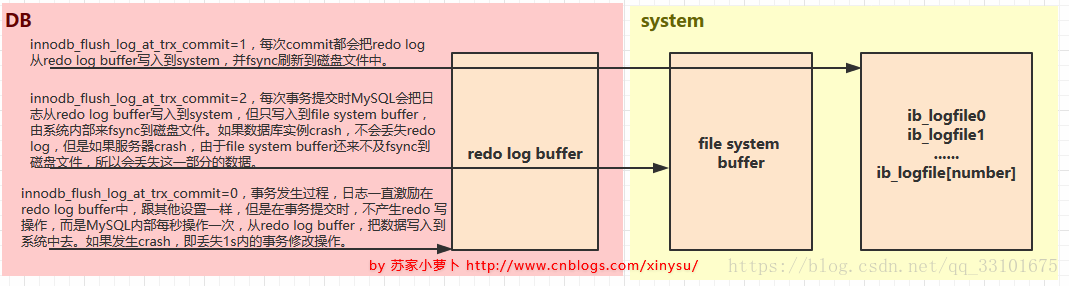
- innodb_flush_log_at_trx_commit
- innodb_flush_log_at_trx_commit=1,每次commit都會把redo log從redo log buffer寫入到system,並fsync重新整理到磁碟檔案中。
- innodb_flush_log_at_trx_commit=2,每次事務提交時MySQL會把日誌從redo log buffer寫入到system,但只寫入到file system buffer,由系統內部來fsync到磁碟檔案。如果資料庫例項crash,不會丟失redo log,但是如果伺服器crash,由於file system buffer還來不及fsync到磁碟檔案,所以會丟失這一部分的資料。
- innodb_flush_log_at_trx_commit=0,事務發生過程,日誌一直激勵在redo log buffer中,跟其他設定一樣,但是在事務提交時,不產生redo 寫操作,而是MySQL內部每秒操作一次,從redo log buffer,把資料寫入到系統中去。如果發生crash,即丟失1s內的事務修改操作。
- 注意:由於程序排程策略問題,這個“每秒執行一次 flush(刷到磁碟)操作”並不是保證100%的“每秒”。
2.3 redo 空間管理
Redo log檔案以ib_logfile[number]命名,Redo log 以順序的方式寫入檔案檔案,寫滿時則回溯到第一個檔案,進行覆蓋寫。(但在做redo checkpoint時,也會更新第一個日誌檔案的頭部checkpoint標記,所以嚴格來講也不算順序寫)。
實際上redo log有兩部分組成:redo log buffer 跟redo log file。buffer pool中把資料修改情況記錄到redo log buffer,出現以下情況,再把redo log刷下到redo log file:
- Redo log buffer空間不足
- 事務提交(依賴innodb_flush_log_at_trx_commit引數設定)
- 後臺執行緒
- 做checkpoint
- 例項shutdown
- binlog切換
3 undo及redo如何記錄事務
這部分內容推薦閱讀這系列的部落格,寫的好好
以下內容部分節選自這部落格,感謝作者總結,深入淺出超好理解。
3.1 Undo + Redo事務的簡化過程
假設有A、B兩個資料,值分別為1,2,開始一個事務,事務的操作內容為:把1修改為3,2修改為4,那麼實際的記錄如下(簡化):
A.事務開始.
B.記錄A=1到undo log.
C.修改A=3.
D.記錄A=3到redo log.
E.記錄B=2到undo log.
F.修改B=4.
G.記錄B=4到redo log.
H.將redo log寫入磁碟。
I.事務提交
3.2 IO影響
Undo + Redo的設計主要考慮的是提升IO效能,增大資料庫吞吐量。可以看出,B D E G H,均是新增操作,但是B D E G 是緩衝到buffer區,只有G是增加了IO操作,為了保證Redo Log能夠有比較好的IO效能,InnoDB 的 Redo Log的設計有以下幾個特點:
A. 儘量保持Redo Log儲存在一段連續的空間上。因此在系統第一次啟動時就會將日誌檔案的空間完全分配。 以順序追加的方式記錄Redo Log,通過順序IO來改善效能。
B. 批量寫入日誌。日誌並不是直接寫入檔案,而是先寫入redo log buffer.當需要將日誌重新整理到磁碟時 (如事務提交),將許多日誌一起寫入磁碟.
C. 併發的事務共享Redo Log的儲存空間,它們的Redo Log按語句的執行順序,依次交替的記錄在一起,
以減少日誌佔用的空間。例如,Redo Log中的記錄內容可能是這樣的:
記錄1: <trx1, insert …>
記錄2: <trx2, update …>
記錄3: <trx1, delete …>
記錄4: <trx3, update …>
記錄5: <trx2, insert …>
D. 因為C的原因,當一個事務將Redo Log寫入磁碟時,也會將其他未提交的事務的日誌寫入磁碟。
E. Redo Log上只進行順序追加的操作,當一個事務需要回滾時,它的Redo Log記錄也不會從Redo Log中刪除掉。
3.3 恢復
前面說到未提交的事務和回滾了的事務也會記錄Redo Log,因此在進行恢復時,這些事務要進行特殊的的處理。有2種不同的恢復策略:
A. 進行恢復時,只重做已經提交了的事務。
B. 進行恢復時,重做所有事務包括未提交的事務和回滾了的事務。然後通過Undo Log回滾那些
未提交的事務。
MySQL資料庫InnoDB儲存引擎使用了B策略, InnoDB儲存引擎中的恢復機制有幾個特點:
A. 在重做Redo Log時,並不關心事務性。 恢復時,沒有BEGIN,也沒有COMMIT,ROLLBACK的行為。也不關心每個日誌是哪個事務的。儘管事務ID等事務相關的內容會記入Redo Log,這些內容只是被當作要操作的資料的一部分。
B. 使用B策略就必須要將Undo Log持久化,而且必須要在寫Redo Log之前將對應的Undo Log寫入磁碟。Undo和Redo Log的這種關聯,使得持久化變得複雜起來。為了降低複雜度,InnoDB將Undo Log看作資料,因此記錄Undo Log的操作也會記錄到redo log中。這樣undo log就可以象資料一樣快取起來,而不用在redo log之前寫入磁碟了。
包含Undo Log操作的Redo Log,看起來是這樣的:
記錄1: <trx1, Undo log insert <undo_insert …>>
記錄2: <trx1, insert …>
記錄3: <trx2, Undo log insert <undo_update …>>
記錄4: <trx2, update …>
記錄5: <trx3, Undo log insert <undo_delete …>>
記錄6: <trx3, delete …>
C. 到這裡,還有一個問題沒有弄清楚。既然Redo沒有事務性,那豈不是會重新執行被回滾了的事務?
確實是這樣。同時Innodb也會將事務回滾時的操作也記錄到redo log中。回滾操作本質上也是
對資料進行修改,因此回滾時對資料的操作也會記錄到Redo Log中。
一個回滾了的事務的Redo Log,看起來是這樣的:
記錄1: <trx1, Undo log insert <undo_insert …>>
記錄2: <trx1, insert A…>
記錄3: <trx1, Undo log insert <undo_update …>>
記錄4: <trx1, update B…>
記錄5: <trx1, Undo log insert <undo_delete …>>
記錄6: <trx1, delete C…>
記錄7: <trx1, insert C>
記錄8: <trx1, update B to old value>
記錄9: <trx1, delete A>
一個被回滾了的事務在恢復時的操作就是先redo再undo,因此不會破壞資料的一致性。
參考文章:
http://mysql.taobao.org/monthly/2016/07/01/
https://yq.aliyun.com/articles/50747
http://www.zhdba.com/mysqlops/2012/04/06/innodb-log1/