
【待修改】[HDFS_1] HDFS 的概念和特性
0. 參考
1. HDFS 是什麼
HDFS :一種分散式檔案系統,可提供對應用程式資料的高吞吐量訪問,解決海量資料儲存問題。
2. HDFS 產生的背景 & 設計前提
隨著網際網路的發展,資料產生的數量越來越大,速度越來越快。傳統的檔案系統所依賴的伺服器價格昂貴,提高其處理效能成本較高且已達到技術瓶頸,縱向擴充套件並不符合當今需求。
HDFS 它的設計目標就是把超大的資料集儲存到多臺普通計算機上(橫向擴充套件),並且可以提供高可靠性和高吞吐量的服務,支援通過新增節點的方式對叢集進行擴容。所以 HDFS 有著它自己的設計前提:
對儲存大檔案支援很好,不適用於儲存大量小檔案
通過流式訪問資料,保證高吞吐量而不是低延時的使用者響應
簡單一致性,使用場景應為一次寫入多次讀取,不支援多使用者寫入,不支援任意修改檔案。
冗餘備份機制,空間換可靠性(Hadoop3中引入糾刪碼機制,糾刪碼需通過計算恢復資料,實為通過時間換空間,有興趣的可以檢視 RAID 的實現)
移動計算優於移動資料,為支援大資料處理主張移動計算優於移動資料,提供相關介面。
3. HDFS 的優缺點
3.1 HDFS 的優點
HDFS 被設計成適合執行在通用和廉價硬體上的分散式檔案系統。它和現有的分散式檔案系統有很多共同點,但他和其它分散式檔案系統的區別也是明顯的。HDFS 是基於流式資料模式訪問和處理超大檔案的需求而開發的,其主要特點如下:
【1. 處理超大檔案】
這裡的超大檔案通常指的是 GB、TB 甚至 PB 大小的檔案。通過將超大檔案拆分為小的 HDFS,並分配給數以百計、千計甚至萬計的的節點,Hadoop 可以很容易地擴充套件並處理這些超大檔案。
【2. 運行於廉價的商用機器叢集上】
HDFS 設計對硬體需求比較低,只需執行在低廉的的商用機器叢集上,而無須使用昂貴的高可用機器。在設計 HDFS 時要充分考慮資料的可靠性、安全性和高可用性。
【3. 高容錯性和高可靠性】
HDFS 設計中就考慮到低廉硬體的不可靠性,一份資料會自動儲存多個副本(具體可用設定,通常三個副本),通過增加副本的數量來保證它的容錯性。如果某一個副本丟失,HDFS 會自動複製其它機器上的副本。
當然,有可能多個副本都會出現問題,但是 HDFS 儲存的時候會自動跨節點和跨機架,因此這種概率非常低,HDFS 同時也提供了各種副本放置策略來滿足不同級別的容錯需求。
【4. 流式的訪問資料】
HDFS 的設計建立在更多低相應 “一次寫入,多次讀寫” 任務的基礎上,這意味著一個數據集一旦有資料來源生成,就會被複制分發到不同的儲存節點中,然後響應各種各種的資料分析任務需求。在多數情況下,分析任務都會涉及資料集的大部分資料,也就是說,對 HDFS 來說,請求讀取整個資料集比請求讀取單條記錄會更加高效。
3.2 HDFS 的缺點
HDFS 的上述種種特點非常適合於大資料量的批處理,但是對於一些特點問題不但沒有優勢,而且有一定的侷限性,主要表現以下幾個方面:
【1. 不適合低延遲資料訪問】
如果要處理一些使用者要求時間比較短的低延遲應用請求(比如毫秒級、秒級的響應時間),則 HDFS 不適合。HDFS 是為了處理大型資料集而設計的,主要是為了達到高的資料吞吐量而設計的,延遲時間通常是在分鐘乃至小時級別。
對於那些有低延遲要求的應用程式,HBase 是一個更好的選擇,尤其是對於海量資料集進行訪問要求毫秒級響應的情況,單 HBase 的設計是對單行或少量資料集的訪問,對 HBase 的訪問必須提供主鍵或主鍵範圍。
【2. 無法高效儲存大量小檔案】
【3. 不支援多使用者寫入和隨機檔案修改】
在 HDFS 的一個檔案中只有一個寫入者,而且寫操作只能在檔案末尾完成,即只能執行追加操作。
4. HDFS 架構
【HDFS 架構圖 】
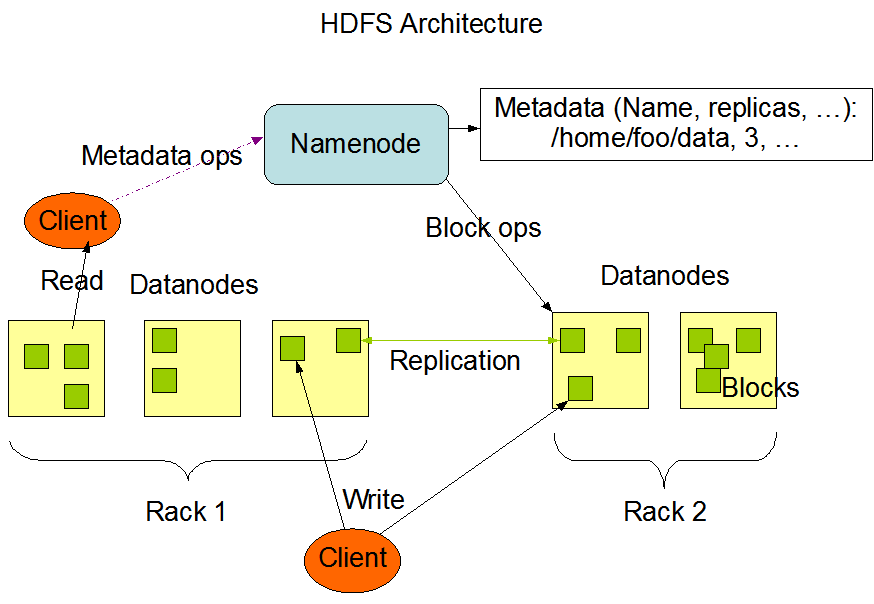
HDFS 負責分散式儲存。
HDFS 採用了主從(Master/Slave)的結構模型,一個 HDFS 叢集是由一個 NameNode 和若干個 DataNode 組成的。
1. HDFS Client
客戶端可以通過一些命令訪問 HDFS,通過訪問 NameNode 獲取檔案的元資料資訊,與 DataNode 互動讀取檔案。
客戶端同時負責對檔案的切分,在檔案上傳時,客戶端將檔案切分成Block進行儲存。
2. NameNode
NameNode 作為 Master,用於儲存檔案的元資料資訊(檔案型別、大小、路徑、許可權等),它也負責資料塊到具體 DataNode 的對映。
NameNode 執行檔案系統的名稱空間操作,比如開啟、關閉、重新命名檔案或目錄等。
3. DataNode
DataNode 作為 Slave,負責處理檔案系統客戶端的檔案讀寫請求,並在 NameNode 的統一排程下進行資料塊的建立、刪除和複製工作。
叢集中 DataNode 管理儲存的資料。HDFS 允許使用者以檔案的形式儲存資料。從內部來看,檔案被分成若干資料塊,而且這若干個資料塊存放在一組 DataNode 上。
4. Secondary NameNode
Secondary NameNode 作為 NameNode 的輔助節點,在 NameNode 無法正常執行的情況下輔助 NameNode 恢復。
他的主要任務是合併 NameNode 的 edit logs 到 fsimage 檔案中。
4. HDFS 檔案塊(Block)的大小
Hadoop1.x 的 HDFS 預設塊大小為 64MB;Hadoop2.x 的預設塊大小為 128MB。
如果進行資料塊的自定義需要修改 hdfs-site.xml 檔案,例如:
待補充。。。