
TCP BBR演算法中Pacing,cwnd,fq以及TSQ對RTT的影響
阿新 • • 發佈:2018-11-12
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
無論多忙,一週至少寫一篇作文的時間必須要擠出來的,而且還不能讓質量打折扣,所以,本文依然會探討一個大多數人沒有意識到的很偏的問題,我的文章一如既往地會寫一些別的地方搜不到的疑難雜症的解法,希望大家多提寶貴意見,多跟我討論技術問題,多PK...說實話,要不是有人問我一個問題,我也不會寫下此文。首先,祝老婆5月20日生日快樂!生於這天,並且肯嫁給我,是我的榮幸,再次折腰!
問題
上週倉促間寫了《
使用TCP時序圖解釋BBR擁塞控制演算法的幾個細節》,有細心的朋友仔細讀了該文,事後給我發了一封郵件,提出了一個非常好的問題,這也是本文的主要內容。問題大致被我整理如下:
依下圖所示的原理:
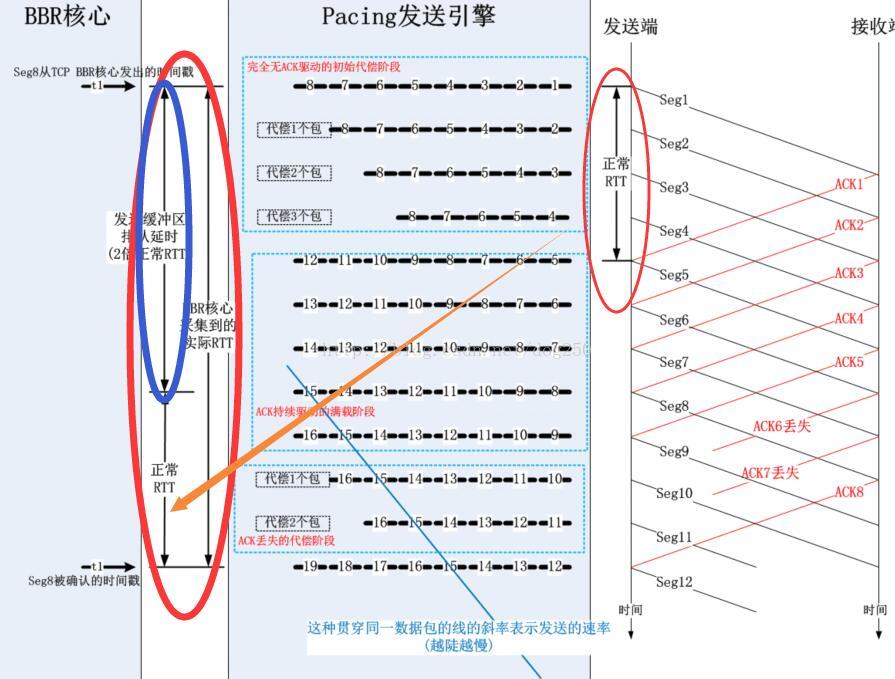
------------------------------
這個問題非常好!其實我最初接觸fq的時候也是循著這個思路來學習的,由於fq和TCP不在一個層次,而是在Qdisc層,所以TCP層傳送資料到Qdsic一定會面臨資訊不對稱的問題,TCP由於擁塞視窗足夠,認為依然可以傳送資料包,然而這個擁塞視窗的計算是BDP和一個補償係數的乘積,該係數是大於1的(為了補償ACK丟失,聚集,延遲...),這個擁塞視窗是比實際的BDP大的,這就必然會引起在Qdisc的fq裡面排隊,所有的資料包都會淨增一個在fq裡面的排隊延遲。
------------------------------
真的是這樣嗎?並不是!理由是什麼呢?
解釋
首先,要知道淨增了fq裡的排隊延遲,是不會影響傳輸速率的,請自行分析。一會兒如果有時間我會用時序圖簡單分析一下。
其次,我們想象一下,視窗增益2倍的BDP,難道就意味著這2倍BDP的資料一定要一次性灌進到Pacing傳送引擎fq的傳送緩衝區嗎?要知道這個視窗在BBR中的意義只是為了保證時刻有包可發,而不是真正的BDP估算,所以它要比BDP大,在真的有包可發的時候,它並不一定非得一次性灌進到fq。這正是是TCP Samll Queue要做的限制。
來看一段關於TSQ的註釋:
直接解答了本文一開始那位哥們兒的疑問,在fq中是不會快取太多的資料包的,這並不是為了擔心會降低效能,事實上根本不會降低效能,而是為了增強公平性。fq的傳送緩衝區空間是有限的,如果一個流快取了太多的包,那麼其它的流所傳送的包將會面臨丟包的風險,這是個和TCP有聯動的“本地佇列管理”機制,直接從源頭抑制了本地佇列的擁塞(路由器能做到嗎?哦,當然有ECN,對了,還有上學時學到的理論上完美但幾乎沒有被實踐過的源抑制...)!/* TCP Small Queues : * Control number of packets in qdisc/devices to two packets / or ~1 ms. * (These limits are doubled for retransmits) * This allows for : * - better RTT estimation and ACK scheduling * - faster recovery * - high rates * Alas, some drivers / subsystems require a fair amount * of queued bytes to ensure line rate. * One example is wifi aggregation (802.11 AMPDU) */
Linux版本的TCP實現中,TCP發包由以下的邏輯控制:
while(true) { skb = next_packet_from_queue; # 判斷是否擁塞視窗允許 if (inflight >= CWND) break; # 判斷是否通告視窗允許 if (skb->end_sequence <= una + WND) break; # 判斷是否TSQ限制 if (TSQ_check_forbidden(skb)) break; # 均無限制,那麼傳送 send_packet_to_IP_Qdisc(skb)}如果你親自試一下,就會發現,無論你怎麼折騰,你都很難讓一個視窗的資料包填滿整個Qdisc的fq佇列,因此你根本就觀察不到由於平添的本地排隊延遲導致的RTT增加。為了觀察到這種現象,僅僅修改擁塞控制演算法是不夠的,從現在起到本文止,去TMD的BBR吧!我們來重新寫一個擁塞演算法:
...unsigned cwnd = TCP_INIT_CWND;module_param(speed_cwnd, uint, 0644);unsigned rate = 1000*1460;module_param(rate, uint, 0644);static void tmd_main(struct sock *sk, const struct rate_sample *rs){ struct tcp_sock *tp = tcp_sk(sk); tp->snd_cwnd = cwnd; tp->sk_pacing_rate = rate;}static u32 tmd_ssthresh(struct sock *sk){ return TCP_INFINITE_SSTHRESH;}static struct tcp_congestion_ops tcp_bbr_cong_ops __read_mostly = { .name = "tmd", .owner = THIS_MODULE, .cong_control = tmd_main, .ssthresh = tmd_ssthresh,};...同時,必須增加一個開關,以支援可以關閉TSQ,只需修改tcp_write_xmit函式即可,在tcp_small_queue_check前增加一個開關:
if (sysctl_tsq_enable && tcp_small_queue_check(sk, skb, 0)) break;當我們把TSQ關掉的時候,嘗試把tmd擁塞演算法的cwnd設定成超級大,然後把rate設定成超級小,用以下命令看看RTT的變化情況:
ss -itnp
此時由於TSQ的限制已然不再,那麼事情完全就取決於BDP恆等式了。按照這個恆等式:
BDP=cwnd=rate*RTT
如果cwnd越大,而rate越小,則RTT會變大,這是顯然的。你會發現,隨著你把rate調高,cwnd保持不變,RTT有下降的趨勢,這也是符合邏輯推理的。在進行這個測試之前,強調兩點:
1.為了免除通告視窗作為限制因素出現,建議將接收方快取調大,並且增加Scale。
2.為了避免fq滿載丟包,請將fq的limit引數設定大一些,至少要和cwnd一樣,以可以至少容納cwnd個數據包。
現在,我們已經知道了一半的真相,現在我們加上TSQ的限制,即Qdisc佇列裡不允許排隊那麼多的資料包,那麼BDP恆等式還成立嗎?當然成立!分兩種情況:
1.只有一個流的情況
由於TSQ的限制,排隊延遲幾乎不存在,那麼從BDP=rate*RTT=cwnd/2可以看出,儲存rate不變的情況下,RTT變小了,cwnd自然也不需要那麼大了,而cwnd在BBR演算法中是通過rate*RTT乘積再乘以一個係數2計算得到的,所以這就是所謂的自適應。即便是cwnd已經是BDP的2倍,由於TSQ的限制,也不會有2個視窗的資料包一次性灌入到fq。
以下說一個細節。
把BBR研究的比較深的人可能還在糾結為什麼cwnd_gain增益加速比是2,如果換成更大的數值,通過BDP計算出來的視窗會更大,會不會造成fq排隊延遲增加呢?不會,還是因為有TSQ限制!
雖然cwnd算出來很大,但是由於TSQ完全基於pacing rate來計算可以一次進入fq傳送緩衝區多少個數據包,所以不會排隊很多的資料包從而增加本地排隊延遲。但是如果把TSQ限制去掉呢?照樣不會!But Why?
我們知道,Qdisc排隊不會帶來效能的損耗,因此對於BBR而言,每次採集到的Deliver Rate不會有任何變化,計算BDP的RTT是min RTT,這是一個擁有bbr_min_rtt_win_sec秒時間視窗的“堅持變數”,在bbr_min_rtt_win_sec秒內堅持著不會更新,因此在netperf測試5秒的場景下,它不會變大,故而BDP不會變大,也因此新一輪的cwnd不會變大,所以這不是一個正反饋,cwnd不會越來越大。
那麼,如果netperf測試超過10秒呢?比如測試100秒的時間,由於fq排隊造成了RTT的增加,10秒後的min RTT將發生變化,即更新為比較大的RTT,然而此時的視窗將強制限定為4個MSS,進入Probe RTT狀態,這種小視窗便可以隨即清空排在fq裡面的資料包,這是一個典型的負反饋。
順便指出一點bbr_min_rtt_win_sec這個“堅持變數”對測量RTT的影響以及對BBR演算法本身的影響。如果你將它設定的比較短,比如從預設的10秒改為更小的比方說100毫秒,在禁用TSQ的情況下,你會明顯觀察到Qdisc排隊延遲導致的RTT增加,而在使用相對比較大的“堅持時間段”時並不會,這是因為“堅持變數”會一直堅持使用“堅持時間段”內最小的RTT來計算cwnd,這樣做的意義在於,在“堅持時間段”內,會給Qdisc一個機會排空佇列,至少是不再增加排隊。理解了這個,便於我們理解BBR的“最小堅持RTT”的本質。對於本地佇列,比如說Qdisc層的佇列,即便沒有使用“堅持變數”,TSQ機制也可以保證Qdisc層fq的佇列不會變長,但是誰也不能保證中間路由器交換機會有類似的TSQ機制,事實上,由於中間裝置對端到端的無感知,其對應的TSQ機制是很難實現的,因此正是“最小堅持RTT”在一定程度上保證了RTT不使用持續變大的瞬時RTT值,進而由BDP恆等式計算的cwnd便不會持續變大,
這就限制了inflight的值不會持續變大,最終減緩了Buffer bloat!這就是我上一段的末尾提到這個負反饋的實質。
現在知道Probe RTT的作用了嗎?事實上,它不光可以搞定並清空中間路由器交換機等裝置的佇列,還可以幫助本地的Qdisc佇列(即傳送緩衝區)維持在一個可以可以接受的佇列長度。
綜合起來看,溫州皮鞋廠老闆所謂的取消Probe RTT狀態以換取不降窗的方法並不可取,因為它可能會帶來不可收拾的正反饋結局,引發佇列(不管是本地fq佇列還是中間節點的佇列)暴漲導致的大量丟包。在本文的最後,我還會說一點關於CoDel佇列管理的細節,但是現在,我要繼續BBR演算法和BDP恆等式的話題。
綜上所述,採用更大的cwnd_gain,不會引發gain正反饋造成Qdisc的fq佇列暴漲而發生丟包,採用2倍速加速比成功解決“無包可發”的問題又不至於浪費視窗。如果你把BBR的Probe RTT狀態去掉,那麼你會發現,只要你增加cwnd_gain的值,便會引發RTT的增加,視窗的增加,進而引發擁塞視窗的正反饋風暴,越來越大,最終Qdisc丟包。
在只有一個流的情況下,TSQ和BDP恆等式二者讓資料流的傳送可以自適應頻寬,而這個自適應頻寬的細節是BBR演算法的不排隊特徵來保證的,BBR既能在不主動排隊(通過“堅持RTT變數”)情況下充分利用頻寬,又和TSQ一起在本地有包可發的前提下保持管道滿載,配合地相當精妙。
2.存在多個流的情況
如果Qdisc佇列長度為100,如果沒有TSQ的限制,那麼先到的突發流將會佔據幾乎所有的佇列快取,造成後到的流無法入隊...TSQ保證了每一個流都不能佔用太多的Qdisc佇列快取,保證大家都有的用,TSQ保證了Qdisc層的fq引擎所謂的“公平”,這就是TSQ的一個主要作用。
這裡穿插點有感而發的題外話,不適者可以忽略。如果你想提高效能,哪裡有涉及公平性考慮的因素,無視它就可以了。我們中國沒有發明TCP協議,但是卻發明了不下100種TCP加速策略,沒有一種知道什麼是收斂的價值!褒貶自有論斷,都是鑽空子,只要是降速降窗,那就一定是不好的事,只要是加速升窗,那就是一切的意義。中國人沒有發明汽車和公路,但是卻開了加塞,別車,闖紅燈的先河,一樣的論斷,一樣的道理,一樣的本質!先到先佔坑,而且儘可能多的搶佔資源,能搶便是道德,可你可知曉,如果本是同根生,那麼相煎何太急?!寫字樓的坊間流傳著各類TCP效能優化傳說,在善於辯論,精通理論,急功近利的國內業界,一個人說一大堆話,你不能證明他錯,也無法肯定他對,那麼誰說的越多,在主流媒體就越吃香,結果大家都跟著他的思路走,其實很多都是毫無事實根據的妄言,只是因為他的抑揚頓挫,關聯詞語背後的假邏輯為其編織了一層華麗性感但毫無任何防護作用的外衣。這種人我鄙視的多了,評論股票的,評論南海的,評論國防的,評論足球的...
沒有實際資料和模型而空談理論,都是扯淡。
按照徐曉東的做法,行不行,打一架便知,可是有誰敢真打呢?打一架怕是會露陷吧...然而到頭來,徐曉東和雷雷都歇菜了,所以宣稱自己很猛的,以及宣稱自己站在道德巔峰很神祕的,都是假的,假的對假的,雙贏還是雙輸,總之,好看。我記得在哪裡看到過一句話,太極練到最猛就落實到了“你打我,我的太極能讓你自己打自己...”,結果,徐曉東真的把自己給“打了”,唉...
總之,面對扯者,不與之扯,不聽其扯,聽其胡扯與其互扯則必導致悲哀,欺世盜名者心中都有一個太極。
------------------------------
以上證明了BDP恆等式在Qdisc佇列存在時的有效性,如果在TCP實現了Pacing rate引擎,那麼就不必使用TSQ了,記住關掉TSQ哦!TSQ是一定公平性因子,不是效能因子。
附:為什麼本地排隊不影響傳輸速率
現在還有點時間,簡單解釋一下為什麼排隊不影響傳輸速率。其實,本地排隊只是影響首包到佇列限制的資料包到達佇列的時間,而不會影響資料包到達接收端的時間。只需看一張時序圖便可知:
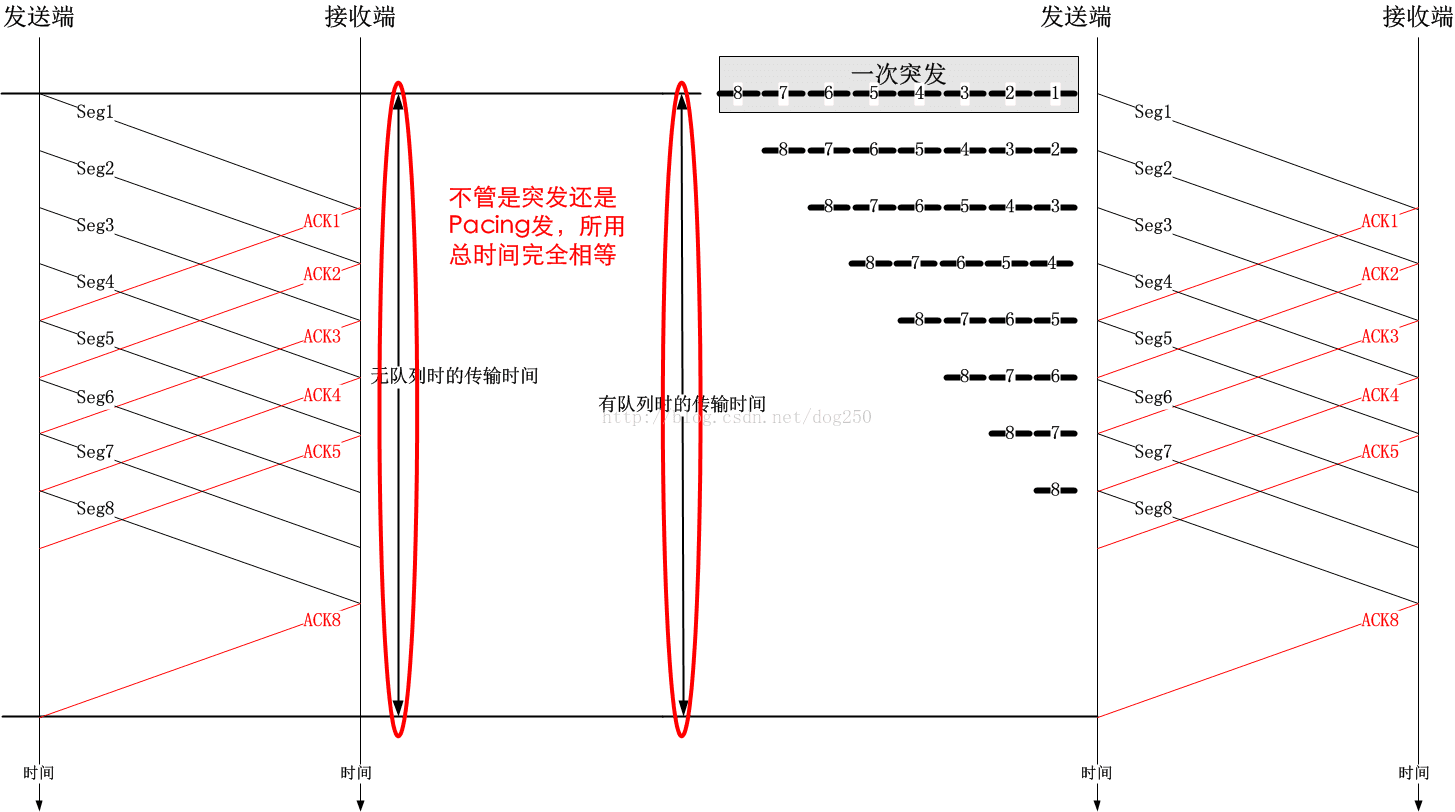
佇列不會增加總的傳輸時間,但是卻可以改變資料的傳輸行為,而這種行為影響著使用者的體驗。基本上所有的流量整型器都是用佇列實現的,當然,這又是另外一個比較複雜的話題了。
這個週末有點假,本文寫於週日午夜前。在週六的一整天,我上午為老婆的生日在家裡準備了火鍋,中午家裡來了客人,與老婆同年同月同日生的有緣人(女性...),大家一起慶祝了生日。
下午實在有點困,小憩了個把小時,起來後開始搞令人噁心的TCP,隨後在傍晚外出跟朋友聚餐,回來後繼續噁心TCP,一直折騰到了午夜。
溫州老闆呢?皮鞋廠都不要了,我還矯情個毛線!
---寫於2017/05/21,週末加班以及家庭瑣事,未能及時發出。
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
