
Operation not permitted引發的驚魂72小時
阿新 • • 發佈:2018-11-12
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
0.問題及描述
在測試產品的時候,莫名其妙發現了我們的主程序VPNd會出現以下的報錯:2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
2013-07-18 13:05:13 www.1.com/192.168.200.220:65527 write UDPv4 []: Operation not permitted (code=1)
這種報錯“但不經常,也不絕對”,上週末測試了兩天,沒有報錯,可是週一就不行了,狂報錯誤!這種棘手的問題最可惡了。
我排查問題的時候,第一步絕對是google,如果沒有結果再按照自己的風格深入進去,能多深入就多深入,一旦有了解決的辦法,我會發表在我所有部落格上,這樣以後別人再google的時候就會多一個答案,網際網路時代的知識其實就是如此方式積累的。
google了好久,沒有什麼創造性的結論,大量的關於這個錯誤的描述都是iptables DROP掉了資料包。其實我十分想找到一個和iptables無關的答案,直覺告訴我一旦找到了,錯誤原因基本就是那個(因為我的iptables規則根本就沒有DROP掉任何東西),可是我沒有找到!沒法發,只能自己來了。驚魂72小時就這樣開始了!三天內,我連續兩天搞到深夜,白天也幾乎不想搭理任何人,要不是因為昨晚喝酒後作業,估計要減少10小時吧,不管這麼說,這72小時還是值得紀念的。
ftrace是一個好東西,這個我早就說過,它很簡單,一般的發行版都支援,於是我做了下面的動作企圖得到除錯資訊:
mount -t debugfs debug /sys/kernel/debugecho skb:kfree_skb >/sys/kernel/debug/tracing/set_event<...>-14297 [002] 1286.492153: kfree_skb: skbaddr=ffff88007c1e0100 protocol=2048 location=$kfree_skb呼叫的地址
怎麼辦呢?由於無法tracestack,那就就只能將上述的“kfree_skb呼叫的地址”在/proc/kallsyms中找了,注意,/proc/kallsyms中不可能有哪個函式完全匹配上面“kfree_skb呼叫的地址”,因為kallsyms中是核心函式的地址,而kfree_skb僅僅是核心函式中的呼叫,因此需要在“kfree_skb呼叫的地址”下方找最接近的函式。
按照上面的過濾方式,一次次的發現正常的kfree_skb,然後將其echo到下面的檔案中:
/sys/kernel/debug/tracing/event/skb/kfree_skb/filter
最終我得到了一個很長的過濾表示式:
echo "location!=0xffffffffa026d04a && location!=0xffffffffa026c82a &&location!=0xffffffff812d6a6f && location !=0xffffffff812a092c &&location!=0xffffffff812aa03e && location != 0xffffffff812f726f &&location!=0xffffffffa01ee3af &&location!=0xffffffff812aaf82 && location!=0xffffffff812965a3 &&location != 0xffffffff812f622c &&location!=0xffffffff812c8324 && location!=0xffffffff812aace1 && location!=0xffffffff81294ef7 && location!=0xffffffff812a12b8 &&location!=0xffffffffa026d04a" >/sys/kernel/debug/tracing/event/skb/kfree_skb/filter echo 1 >/sys/kernel/debug/tracing/event/skb/kfree_skb/enablewhile true; do echo $(date); cat trace|grep -v FUNCTION|grep -v "tracer: nop"|grep -v "# | | |"|grep -v "#";>trace;sleep 4;done然後就是漫長的等待,等待問題的重現。成小時成小時的等待...終於重現了,結果就是大量的:
<VPNd>-xx [002] 2876.582821: kfree_skb: skbaddr=ffff88007c1e0100 protocol=2048 location=ffffffff812b2887
查詢kallsyms,發現它真的就是nf_hook_slow,而這個函式正是Netfilter的核心函式,難道真的是iptables導致的?我還是不相信!但是不能有更詳細的資訊了,要是能把stack打出來該多好啊!!
2.需要更加詳細的資訊
很顯然,沒有function trace支援的核心無法通過ftrace得到更加詳細的資訊了,其實我現在就是想得到問題重現時呼叫nf_hook_slow時的堆疊。重新編譯核心肯定能解決,但是場面過於巨集大,於是想辦法自己hack一個,於是編寫了下面的模組:#include <linux/types.h>#include <linux/module.h>#include <linux/smp_lock.h>//#include <linux/netfilter.h>MODULE_LICENSE("GPL");MODULE_AUTHOR("ZhaoYa <[email protected]>");MODULE_DESCRIPTION("Xtables: DNAT from ip-pool");//準備替換掉nf_hook_slowint (*orig_nf_hook_slow) (u_int8_t, unsigned int, struct sk_buff*, struct net_device*, struct net_device*, int (*okfn)(struct sk_buff *), int) = 0xffffffff8126a910;char code[200] = {0};int (*_nf_hook_slow) (u_int8_t, unsigned int, struct sk_buff*, struct net_device*, struct net_device*, int (*okfn)(structsk_buff *), int);int new_nf_hook_slow(u_int8_t pf, unsigned int hook, struct sk_buff *skb, struct net_device *indev, struct net_device *outdev, int (*okfn)(struct sk_buff *), int hook_thresh){ //先呼叫原來的nf_hook_slow int ret = _nf_hook_slow(pf, hook, skb, indev, outdev, okfn, hook_thresh); //如果被DROP了就列印堆疊 if (ret = 1) { dump_stack(); } return ret;}static int __init pool_target_init(void){ //0xffffffff8126a910是原始nf_hook_slow的地址, //由於還要使用該處的程式碼,覆蓋前先儲存在別處 char *addr = 0xffffffff8126a910; //由於需要重寫0xffffffff8126a910,防止核心設定了只讀, //故需要修改PTE頁表項 char *pte = 0xfffffffff126a161; lock_kernel(); unsigned long value =*pte; value = value|0x02; *pte = value; //先將原始函式儲存在code裡面,200這個長度是原始nf_hook_slow的地址 //和它下面一個函式地址的差值多一點,由於程式碼中肯定有return,因此多 //複製一些沒關係,少了就不行。 memcpy(code, orig_nf_hook_slow, sizeof(code)); //用新的nf_hook_slow覆蓋原來函式的地址 memcpy(addr, new_nf_hook_slow, 40); //儲存原始函式的新地址 _nf_hook_slow = code; unlock_kernel(); return 0;}static void __exit pool_target_exit(void){ char *addr = 0xffffffff8126a910; lock_kernel(); memcpy(addr, code, sizeof(code)); unlock_kernel();}module_init(pool_target_init);module_exit(pool_target_exit);程式碼亂七八糟的,由於在原有的一個nat模組上更改(便於使用它的Makefile),因此命名也不合常理。載入之,報錯,panic!!
...
直到現在仍然沒有編譯新核心的勇氣
...
心中的氣憤達到了要崩潰的地步,終於決定重新編譯核心了!
3.重新配置並編譯核心以及所有模組
下午2點開始,重新配置核心,新增的配置如下:< CONFIG_FRAME_POINTER=y
< CONFIG_HAVE_FTRACE_NMI_ENTER=y
< CONFIG_FTRACE_NMI_ENTER=y
< CONFIG_FUNCTION_TRACER=y
< CONFIG_FUNCTION_GRAPH_TRACER=y
< CONFIG_FTRACE_SYSCALLS=y
< CONFIG_STACK_TRACER=y
< CONFIG_WORKQUEUE_TRACER=y
< CONFIG_DYNAMIC_FTRACE=y
< CONFIG_FUNCTION_PROFILER=y
< CONFIG_FTRACE_MCOUNT_RECORD=y
這樣就可以支援function trace了!然後make-kpkg編譯之。漫長3小時後,還沒有編譯完,我的虛擬機器真的不行了。要下班了,匆匆回家,以前從來沒有這麼早過,在路上可以換換心情。發現我的心理素質還不錯,路上結掉了《羅馬人的故事:最後一搏》,超級崇拜君士坦丁!
回家吃完晚飯,又開始了驚魂之旅,通過VPN接入公司的機器,發現終於編譯完成,於是趕緊先提交到SVN上,大概九點多,準備用新核心除錯,由於興奮喝了半瓶酒,酒後作業不管幹什麼都很危險,不僅僅是開車。在升級核心時,一下子把grub也給換掉了,reboot沒有成功,公司機器又不支援IPMI遠端開機,這下悲催了...只能早早睡了!
4.新的ftrace以及stack trace
今天早上趕緊到公司,配置好了新的環境,升級了新的核心,終於可以一窺究竟了,等待問題重現後,列印了以下資訊:<...>-27369 [002] 2876.582821: kfree_skb: skbaddr=ffff88007c1e0100 protocol=2048 location=ffffffff812ad914
<...>-27369 [002] 2876.582825: <stack trace>
=> kfree_skb
=> nf_hook_slow
=> T.889
=> ip_output
=> ip_local_out
=> ip_push_pending_frames
=> udp_push_pending_frames
=> udp_sendmsg
<...>-27369 [002] 2876.583069: kfree_skb: skbaddr=ffff88007c1e0c00 protocol=2048 location=ffffffff812ad914
<...>-27369 [002] 2876.583074: <stack trace>
=> kfree_skb
=> nf_hook_slow
=> T.889
=> ip_output
=> ip_local_out
=> ip_push_pending_frames
=> udp_push_pending_frames
=> udp_sendmsg
<idle>-0 [002] 11979.770335: kfree_skb: skbaddr=ffff88002f3f5200 protocol=2048 location=ffffffff812ad914
<idle>-0 [002] 11979.770338: <stack trace>
=> kfree_skb
=> nf_hook_slow
=> ip_local_deliver
=> ip_rcv_finish
=> ip_rcv
=> netif_receive_skb
=> br_handle_frame_finish
=> br_nf_pre_routing_finish
.....大量的br_nf_pre_routing_finish起始的stack到達ip_local_deliver後被Netfilter丟棄
起初,我以為都是VPNd發出的資料包被DROP,現在看來bridge接收的資料包也會被DROP(此時的程序是核心本身即0號idle程序,其實它並不idle,新核心的所有核心執行緒都在idle的工作佇列裡),從以上堆疊看,ip_local_deliver以及ip_output對應的HOOK點分別應該是INPUT以及POSTROUGING,由於我並沒有在這兩個Chain上新增任何iptables的DROP策略,鑑於對Netfilter的理解比較深入,因此我覺得是核心本身隱含的一些HOOK函式導致的,為了找到是哪個隱含的HOOK函式,就有必要跟一下程式碼,由於使用ftrace輸出大量的資訊會遇到薛定諤貓的問題,因此決定靜態瀏覽程式碼。
這裡有一個疑點,那就是起初我以為丟包都是VPNd程序造成的,可是從ftrace的結果看來,大量的丟包是ilde程序的softirq中造成的,很明顯是資料包的接收程序造成了丟包;還有一個疑點,那就是通過檢視/proc/net/snmp檔案,發現其OutDiscards欄位在問題重現即Operation not permitted的時候有所增加,而OutDiscards的增加僅僅在確定的地方被呼叫。在沒有全面分析問題之前,這兩個疑點說明了兩個問題,一是ip_local_out函式確實有丟包,二是可能是一個全域性問題導致了這個丟包,因為並不是僅僅在傳送資料的時候丟包。
註解:如果看上述堆疊,會發現br_nf_pre_routing_finish-br_handle_frame_finish-netif_receive_skb跟實際不一樣,這是因為我修改了nf_bridge的緣故,我的目標是先讓bridge去call iptables的PREROUTING,然後再基於mark絕對是否進行bridge的redirect。
5.遍歷Netfilter的OUTPUT以及POSTROUTING
遍歷程式碼的過程是痛苦的,無非就是找到核心隱含的HOOK函式中,在什麼情況下會DROP掉資料包,並且還要在INPUT以及POSTROUTING這兩個點上。最後__nf_conntrack_confirm引起了我的注意,因為資料包在離開協議棧的時候,會呼叫confirm,這個是為了將NEW狀態的conntrack新增到conntrack雜湊中,恰恰這個confirm也正是在INPUT以及POSTROUTING這兩個點上,這兩個點正是資料包離開協議棧的點!更加幸運的是,竟然在該函式中找到了DROP:int__nf_conntrack_confirm(struct sk_buff *skb){ ... //如果標示為NEW的conn在雙向的雜湊表中找到了相同的,則DROP hlist_nulls_for_each_entry(h, n, &net->ct.hash[hash], hnnode) if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple, &h->tuple)) goto out; hlist_nulls_for_each_entry(h, n, &net->ct.hash[repl_hash], hnnode) if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_REPLY].tuple, &h->tuple)) goto out;...out: NF_CT_STAT_INC(net, insert_failed); spin_unlock_bh(&nf_conntrack_lock); return NF_DROP;}NF_CT_STAT_INC(net, insert_failed);
這是一個核心計數器,名稱是insert_failed,於是藉助於procfs的net/stat目錄觀測。
6.定位到insert_failed計數器
通過檢視/proc/net/stat/nf_conntrack,發現了下面的事實:XXXX-SSL-GATEWAY:/proc/net# cat stat/nf_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete
00002236 00692e45 024a9466 001e1713 00008ab5 00008007 001cad74 001c9b8d 001e087b 00000e7f 00000000 00000000 000004a1 00000000 00000000 00000000
00002236 0067bfee 0241465c 001db7e0 00008853 00007756 001f1fe9 001f1265 001daab2 00000d19 00000000 00000000 0000049b 00000000 00000000 00000000
00002236 00656b68 02332e99 001d3312 00008026 00007795 001d9498 001d8a18 001d2575 00000d8f 00000000 00000000 00000482 00000000 00000000 00000000
00002236 0062d343 02261842 001cccef 00007ca2 0000792a 001c4ac9 001c3e58 001cbff6 00000ceb 00000000 00000000 000004a5 00000000 00000000 00000000
# 此處的時間內,問題重現了
XXXX-SSL-GATEWAY:/proc/net# cat stat/nf_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete
000021c9 006b559d 0259312e 001ecf50 00008e14 00008023 001d83fa 001d7298 001ec0b8 00000e7f 00000000 00000000 000004a3 00000000 00000000 00000000
000021c9 0069b52e 024fdc33 001e6eb1 00008be5 00007760 001fb89d 001faa7c 001e6181 00000dab 00000000 00000000 000004a1 00000000 00000000 00000000
000021c9 006765ca 02416a16 001de7ab 0000835f 000077a8 001e49e8 001e3f81 001dda05 00000d98 00000000 00000000 00000485 00000000 00000000 00000000
000021c9 0064d066 0233c2d7 001d7e55 00007f83 0000792c 001cfbb9 001cef3c 001d715c 00000ceb 00000000 00000000 000004a5 00000000 00000000 00000000
注意上面的insert_failed計數器的遞增,說明什麼?說明正是那個__nf_conntrack_confirm函式將資料包DROP了。
問題定位了,下面就是解決它了!出去抽根菸,理一下思路。
7.丟棄ftrace,開始用conntrack工具
至此,不再需要ftrace了,暫時不需要了,因為下面的工作我很自信,也會用比較YD的方式去解決,關掉ftrace以防薛定諤貓的驚現!echo 0 >/sys/kernel/debug/tracing/event/skb/kfree_skb/enableumount /sys/kernel/debugconntrack -E -e DESTROYWARNING: We have hit ENOBUFS! We are losing events.
This message means that the current netlink socket buffer size is too small.
Please, check --buffer-size in conntrack(8) manpage.
conntrack v1.0.0 (conntrack-tools): Operation failed: No buffer space available
這下沒轍了,於是又寫了一個命令:
while true;do echo $(date);cat ip_conntrack|grep 192.168.200.220|grep udp;echo ;echo;sleep 2;done2013年 07月 18日 星期四 13:02:15 CST
udp 17 179 src=192.168.200.220 dst=192.168.101.242 sport=16796 dport=61194 packets=161510 bytes=27474312 src=192.168.101.242 dst=192.168.200.220 sport=61194 dport=16796 packets=140004 bytes=36911621 [ASSURED] mark=100 secmark=0 use=2
2013年 07月 18日 星期四 13:02:18 CST
2013年 07月 18日 星期四 13:02:22 CST
conntrack突然消失了,這就不對了,還剩下179秒才到期,怎麼會被刪除呢?下一步其實又要看程式碼了,看一下都在哪裡呼叫刪除conntrack的動作,但是我覺得已經沒有必要了,因為我已經知道了答案,在我們的產品中,前期為了解決一個問題,呼叫了conntrack -F命令...
實際上,即使我不知道呼叫conntrack -F,也還是能定位了確實有人呼叫了conntrack -F的。通過觀察上面的ftrace輸出就會發現,每次只要udp_sendmsg造成的DROP的同時,都會有大量的br_nf_pre_routing_finish造成的DROP,反過來也一樣,導致我曾經想過二者是不是一方的發生導致了另一方的發生,後來我發現它們沒有什麼關係,那麼這能證明什麼呢?--------------- 證明一定有大量的conntrack同時被刪除的情況------------ 如果核心中有自動的大量資訊被同時刪除,那一定是缺陷,設計者不會做如此不平滑的事情的。一般而言都是丟棄當前的。這就說明一定是使用者態有人通過系統提供的介面手工呼叫了刪除操作,罪魁禍首,當然是conntrack -F了!
8.沒辦法了,只靠想了
現在問題還沒有解決,需要想一下就是conntrack被刪除,如何能導致資料包在__nf_conntrack_confirm被DROP呢?這樣反過來確認一下,可以儘可能排除其它的因素。這個也沒辦法再除錯了,只能靠想了,但是前提是你需要對Netfilter對conntrack的處理極其精通,我給出一張時序圖來說明問題吧:注意__nf_conntrack_confirm的註釋“如果標示為NEW的conn在雙向的雜湊表中找到了相同的,則DROP”
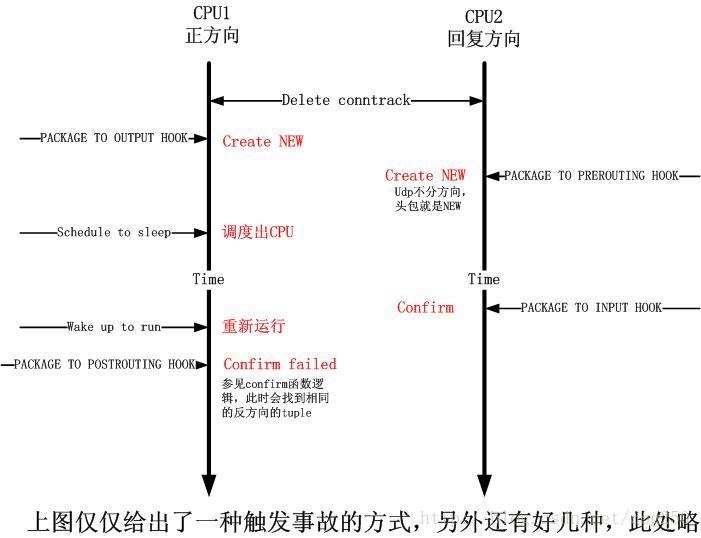
連線是雙向的,而conntrack卻只有一個是問題的關鍵,由此看來,還是TCP的有狀態conntrack比較完美。
這個問題真的很不好重現,我試著手工呼叫了幾次conntrack -F,並不是每次都能重現,甚至連續好幾次執行才能重現。必須卡在上圖的那些時間點,問題才能重現,因此這是個“但不經常,也不絕對”的問題!!
通過上圖,我們可以發現,在多處理器環境下更容易發生這個問題,因為在多處理器情況下,問題的重現不僅僅取決於udp傳送程序的
schedule,還取決於其它處理器上網路資料包接收程序的執行。
9.尷尬的解決方式
為何尷尬?問題不是解決了嗎?是的,問題解決了,但是解決方式確實很尷尬,就是去掉了conntrack -F而已,太TMD沒有技術含量了。然而對於技術痴迷者而言,這驚魂72小時確實讓我學到了很多東西,也讓我明白以後應該試著不把簡單問題複雜化,到底哪裡出了問題的另一個問法其實就是“我到底添加了哪些功能”,在沒有問題發生到有問題出現的時間段內的任何更改都可能導致各種奇異的問題。作為一個bug的定位和解決,確實很尷尬,但是對於一個技術痴迷者而言,重要的是知其所以然,是為所以然。
10.經驗
沒有什麼經驗,唯一的經驗就是在加入一個功能的時候,一定要徹底瞭解該功能所用到的所有的技術細節,否則就很有可能引入新的問題!對待技術問題決不能模稜兩可,要麼不用,要用就要徹底摸清!11.關於標題
本文之所以取這麼一個名字,是因為希望別人比較容易搜到這篇文章,因為我在起初解決問題google的時候,花了大量的時間沒有結果,不管國內國外的高手,都沒有切入重點。因此我希望我這篇驚魂72小時可以對大家有所幫助,畢竟我起初也是希望能直接在網上找到答案,懷著這麼一種僥倖心理,不想自己努力,只是沒有找到結果以後,不得已才自己摸索的。這樣的人我相信是大多數,因此我希望大家都能繼續嘗試這種方式,畢竟是懶人創造了世界,懶人並不懶惰,懶人不重新造輪子,但是在迫不得已不得不重新造輪子的時候,他的目的是不希望別人-別的懶人重新造輪子!12.72小時內的生活
我感覺自己就是雙核,我可以在72小時內保持緊張去排查這個問題,然而另一方面,我又有自己其它方面的收穫:1.結掉了第9本《羅馬人的故事》,是為最後的一搏,為戴克裡先感到悲哀。
2.查閱了君士坦丁的相關資料,理解了他為何結束了羅馬帝國,建立了中世紀。
3.靠地利優勢可以勝過天時和人和。
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
