
7.Hadoop的學習(Hadoop的配置(偽分散式的搭建)-3(啟動守護程序))
阿新 • • 發佈:2018-11-12
1.經過前面的兩節,我們就可以使用HDFS檔案系統了
2.首先要對檔案系統進行格式化:
執行格式化的命令: hadoop namenode -format
3. 啟動守護程序
進入到 ssh localhost
啟動HDFS: start-dfs.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo
啟動YARN: start-yarn.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo
啟動完之後,輸入jps

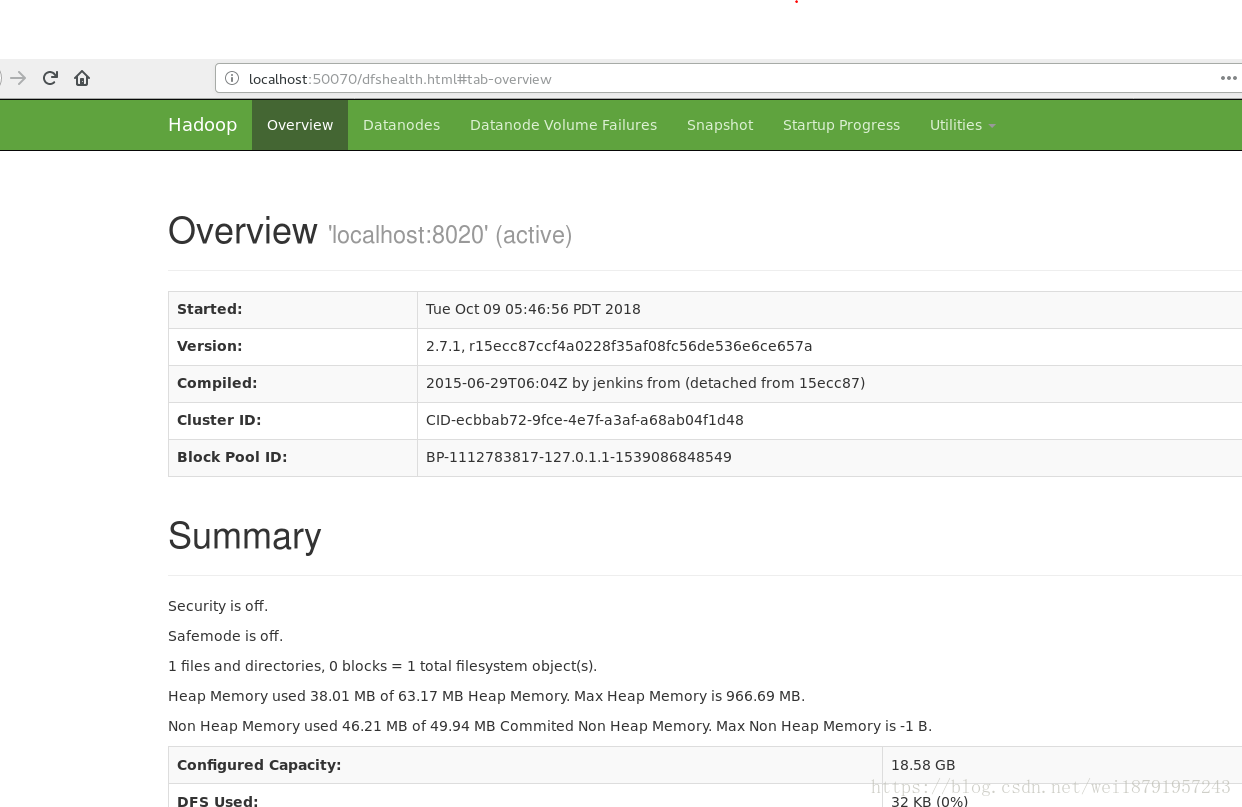
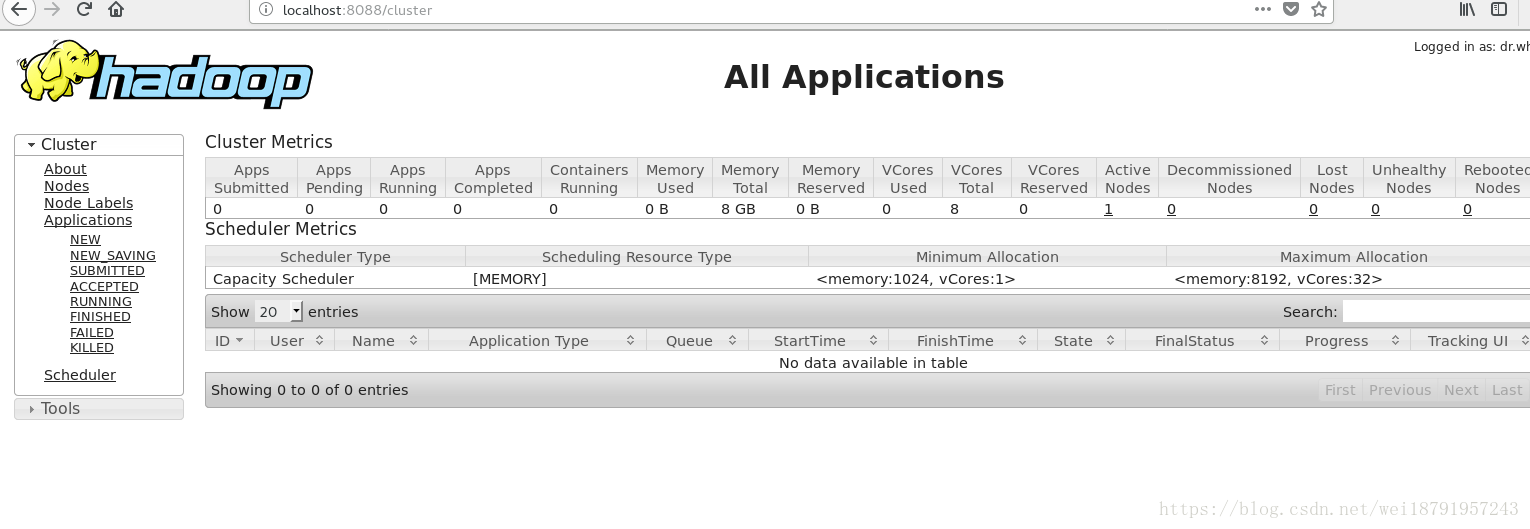
4.可以開啟Ubuntu系統的瀏覽器 有如下兩個圖就啟動成功了
輸入http://localhost:50070/ 可以看見名稱節點等,裡面有點版本資訊等
輸入 http://localhost:8088 可以看見資料節點
5.也可以ssh localhost 之後:
輸入 start-all.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo 一個命令全部啟動