
Batch-Normalization深入解析
BN:總的來說,BN通過將每一層網路的輸入進行normalization,保證輸入分佈的均值與方差固定在一定範圍內,減少了網路中的Internal Covariate Shift問題,並在一定程度上緩解了梯度消失,加速了模型收斂;並且BN使得網路對引數、啟用函式更加具有魯棒性,降低了神經網路模型訓練和調參的複雜度;最後BN訓練過程中由於使用mini-batch的mean/variance每次都不同,引入了隨機噪聲,在一定程度上對模型起到了正則化的效果。
Normalization
字面上意思就是標準化,也就是對輸入的資料做標準化,可以用下面的公式表示(這裡 代表輸入資料, n代表訓練集大小):
以上可以看出, 標準化以後的資料服從均值為0,方差為1的正態分佈
為什麼要進行Normalization?
在介紹BN之前,先說說為什麼要進行Normalization
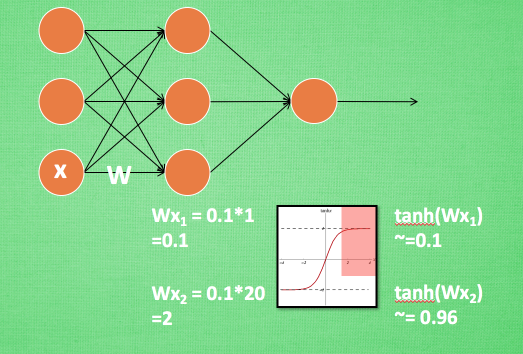
在神經網路中, 資料分佈對訓練會產生影響. 比如某個神經元 x 的值為1, 某個 Weights 的初始值為 0.1, 這樣後一層神經元計算結果就是 Wx = 0.1; 又或者 x = 20, 這樣 Wx 的結果就為 2. 現在還不能看出什麼問題, 但是, 當我們加上一層激勵函式, 啟用這個 Wx 值的時候, 問題就來了. 如果使用 像 tanh 的激勵函式, Wx 的啟用值就變成了 ~0.1 和 ~1, 接近於 1 的部已經處在了 激勵函式的飽和階段, 也就是如果 x 無論再怎麼擴大, tanh 激勵函式輸出值也還是接近1. 換句話說, 神經網路在初始階段已經不對那些比較大的 x 特徵範圍 敏感了. 這樣很糟糕, 想象我輕輕拍自己的感覺和重重打自己的感覺居然沒什麼差別, 這就證明我的感官系統失效了. 當然我們是可以用之前提到的對資料做 normalization 預處理, 使得輸入的 x 變化範圍不會太大, 讓輸入值經過激勵函式的敏感部分. 但剛剛這個不敏感問題不僅僅發生在神經網路的輸入層, 而且在隱藏層中也經常會發生.
Normalization的效果:
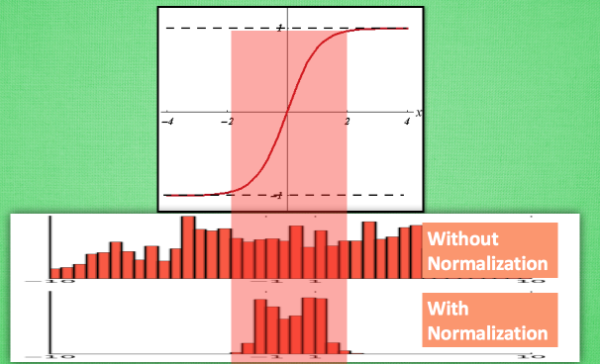
如上圖,當沒有進行normalizatin時,資料的分佈是任意的,那麼就會有大量的資料處在啟用函式的敏感區域外, 對這樣的資料分佈進行啟用後, 大部分的值都會變成1或-1,造成啟用後的資料分佈不均衡,而如果進行了Normallizatin, 那麼相對來說資料的分佈比較均衡,如下圖所示:
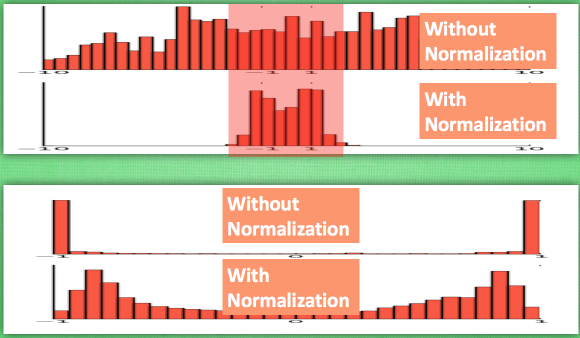
一句話總結就是: 通過Normalization讓資料的分佈始終處在啟用函式敏感的區域
BN的提出背景
https://zhuanlan.zhihu.com/p/34879333
Internal Covariate Shift
Covariate [kʌ’veərɪrt]
什麼是Internal Covariate Shift:
在深層網路訓練的過程中,由於網路中引數變化而引起內部結點資料分佈發生變化的這一過程被稱作Internal Covariate Shift。
帶來了什麼問題:
- 上層網路需要不停調整來適應輸入資料分佈的變化,導致網路學習速度的降低
- 網路的訓練過程容易陷入梯度飽和區,減緩網路收斂速度
如何減緩Internal Covariate Shift:
(1)白化(PCA白化和ZCA白化):
- 使得輸入特徵分佈具有相同的均值與方差
- 取出特徵之間的相關性
- 通過白化操作,我們可以減緩ICS的問題,進而固定了每一層網路輸入分佈,加速網路訓練過程的收斂
白化缺點:
- 白化過程計算成本太高,並且在每一輪訓練中的每一層我們都需要做如此高成本計算的白化操作;
- 白化過程由於改變了網路每一層的分佈,因而改變了網路層中本身資料的表達能力。底層網路學習到的引數資訊會被白化操作丟失掉。
於是就提出了BN
什麼是Batch Normalization
傳統的Normalization使用的均值和方差是整個訓練集的均值和方差, 並且只對輸入層的資料做歸一化, 而Batch Normalization按字面意思就是對每一批資料進行歸一化, 同時會對每一層輸入做歸一化, 所以, 首先要將傳統的標準化中的n改為m, m表示一個batch的大小,如下所示:
傳統的Normalization直接使用了減均值除方差的方式來進行標準化, 但是, 這樣一概而全的方法未必對所有資料來說就是最優的, 比如資料本身就不對稱, 或者啟用函式未必對方差為1的資料有最好的效果, 所以, BN的想法是在傳統標準化之後再加上一個線性變換,如下所示:
其中, 和 是兩個需要學習的引數, ** 可以看出, BN的本質就是利用引數優化來改變一下資料分佈的方差大小和均值的位置. **
BN的優點
(1)BN使得網路中每層輸入資料的分佈相對穩定,加速模型學習速度
(2)BN使得模型對初始化方法和網路中的引數不那麼敏感,簡化調參過程,使得網路學習更加穩定
(3)BN允許網路使用飽和性啟用函式(例如sigmoid,tanh等),緩解梯度消失問題
(4)BN具有一定的正則化效果
原因如下:
(1)BN使得網路中每層輸入資料的分佈相對穩定,加速模型學習速度
BN通過規範化與線性變換使得每一層網路的輸入資料的均值與方差都在一定範圍內,使得後一層網路不必不斷去適應底層網路中輸入的變化,從而實現了網路中層與層之間的解耦,更加有利於優化的過程,提高整個神經網路的學習速度。
(2)BN使得模型對初始化方法和網路中的引數不那麼敏感,簡化調參過程,使得網路學習更加穩定
在神經網路中,我們經常會謹慎地採用一些權重初始化方法(例如Xavier)或者合適的學習率來保證網路穩定訓練。當學習率設定太高時,會使得引數更新步伐過大,容易出現震盪和不收斂…
https://zhuanlan.zhihu.com/p/34879333
(3)BN允許網路使用飽和性啟用函式(例如sigmoid,tanh等),緩解梯度消失問題
在不使用BN層的時候,由於網路的深度與複雜性,很容易使得底層網路變化累積到上層網路中,導致模型的訓練很容易進入到啟用函式的梯度飽和區;通過normalize操作可以讓啟用函式的輸入資料落在梯度非飽和區,緩解梯度消失的問題;另外通過自適應學習 與 又讓資料保留更多的原始資訊。
(4)BN具有一定的正則化效果
在Batch Normalization中,由於我們使用mini-batch的均值與方差作為對整體訓練樣本均值與方差的估計,儘管每一個batch中的資料都是從總體樣本中抽樣得到,但不同mini-batch的均值與方差會有所不同,這就為網路的學習過程中增加了隨機噪音,與Dropout通過關閉神經元給網路訓練帶來噪音類似,在一定程度上對模型起到了正則化的效果。
另外,原作者也證明了網路加入BN後,可以丟棄Dropout,模型也同樣具有很好的泛化效果。
BN的具體實現及其反向傳播
https://www.jianshu.com/p/4270f5acc066
https://zhuanlan.zhihu.com/p/27938792
在Caffe2實現中, BN層需要和Scale層配合使用, 其中, BN專門用於做歸一化操作, 而後續的線性變換層, 會交給Scale層去做.
訓練階段:
在訓練時利用當前batch的mean和variance來進行BN處理, 同時使用滑動平均的方式不斷的更新global 的mean和variance, 並將其儲存起來.
測試階段:
在預測階段, 直接使用模型儲存好的均值和方差進行計算
使用BN時應注意的問題
- 訓練/測試階段的使用
在實際應用中, 均值和方差是通過滑動平均方法在訓練資料集上得到的, 如果換了其他的任務或資料集, 建議先finetune之後再使用BN層儲存的均值和方差. 同時, 注意訓練時的均值和方差是來自於當前batch的.
- 隱藏層中BN的資料大小
在卷積網路隱藏層中, BN的大小不單單是batch, 而是batch和特徵相應圖大小的乘積. 也就是說, 在隱藏層, 層的輸入是上一層的輸出, 也就是上一層的神經元個數, 而對於上一層來說, 如果輸出的特徵相應圖大小為
, 那麼上一層的神經元個數就應該是
, 其中,b是指batch的大小