
學習分散式不得不會的CAP理論
2018年07月16日 11:52:59 Hollis在CSDN 閱讀數:161更多
個人分類: 架構
2000年7月,加州大學伯克利分校的Eric Brewer教授在ACM PODC會議上提出CAP猜想。2年後,麻省理工學院的Seth Gilbert和Nancy Lynch從理論上證明了CAP。之後,CAP理論正式成為分散式計算領域的公認定理。
無論你是一個系統架構師,還是一個普通開發,當你開發或者設計一個分散式系統的時候,CAP理論是無論如何也繞不過去的。本文就來介紹一下到底什麼是CAP理論,如何證明CAP理論,以及CAP的權衡問題。
CAP理論概述
CAP理論:一個分散式系統最多隻能同時滿足一致性(Consistency)、可用性(Availability)和分割槽容錯性(Partition tolerance)這三項中的兩項。
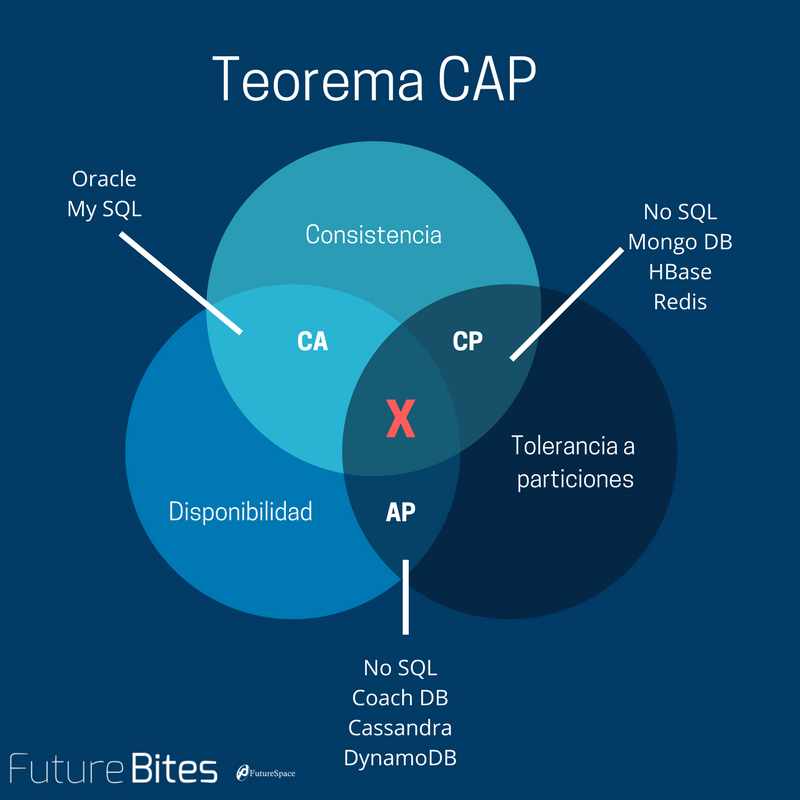
讀者需要注意的的是,CAP理論中的CA和資料庫事務中ACID的CA並完全是同一回事兒。兩者之中的A都是C都是一致性(Consistency)。CAP中的A指的是可用性(Availability),而ACID中的A指的是原子性(Atomicity),切勿混為一談。
CAP的定義
Consistency 一致性
一致性指“all nodes see the same data at the same time
對於一致性,可以分為從客戶端和服務端兩個不同的視角。從客戶端來看,一致性主要指的是多併發訪問時更新過的資料如何獲取的問題。從服務端來看,則是更新如何複製分佈到整個系統,以保證資料最終一致。
一致性是因為有併發讀寫才有的問題,因此在理解一致性的問題時,一定要注意結合考慮併發讀寫的場景。
從客戶端角度,多程序併發訪問時,更新過的資料在不同程序如何獲取的不同策略,決定了不同的一致性。
三種一致性策略
對於關係型資料庫,要求更新過的資料能被後續的訪問都能看到,這是強一致性。
如果能容忍後續的部分或者全部訪問不到,則是弱一致性。
如果經過一段時間後要求能訪問到更新後的資料,則是最終一致性。
CAP中說,不可能同時滿足的這個一致性指的是強一致性。
Availability 可用性
可用性指“Reads and writes always succeed”,即服務一直可用,而且是正常響應時間。
對於一個可用性的分散式系統,每一個非故障的節點必須對每一個請求作出響應。所以,一般我們在衡量一個系統的可用性的時候,都是通過停機時間來計算的。
| 可用性分類 | 可用水平(%) | 年可容忍停機時間 |
|---|---|---|
| 容錯可用性 | 99.9999 | <1 min |
| 極高可用性 | 99.999 | <5 min |
| 具有故障自動恢復能力的可用性 | 99.99 | <53 min |
| 高可用性 | 99.9 | <8.8h |
| 商品可用性 | 99 | <43.8 min |
通常我們描述一個系統的可用性時,我們說淘寶的系統可用性可以達到5個9,意思就是說他的可用水平是99.999%,即全年停機時間不超過 (1-0.99999)*365*24*60 = 5.256 min,這是一個極高的要求。
好的可用性主要是指系統能夠很好的為使用者服務,不出現使用者操作失敗或者訪問超時等使用者體驗不好的情況。一個分散式系統,上下游設計很多系統如負載均衡、WEB伺服器、應用程式碼、資料庫伺服器等,任何一個節點的不穩定都可以影響可用性。
Partition Tolerance分割槽容錯性
分割槽容錯性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分散式系統在遇到某節點或網路分割槽故障的時候,仍然能夠對外提供滿足一致性和可用性的服務。
分割槽容錯性和擴充套件性緊密相關。在分散式應用中,可能因為一些分散式的原因導致系統無法正常運轉。好的分割槽容錯性要求能夠使應用雖然是一個分散式系統,而看上去卻好像是在一個可以運轉正常的整體。比如現在的分散式系統中有某一個或者幾個機器宕掉了,其他剩下的機器還能夠正常運轉滿足系統需求,或者是機器之間有網路異常,將分散式系統分隔未獨立的幾個部分,各個部分還能維持分散式系統的運作,這樣就具有好的分割槽容錯性。
簡單點說,就是在網路中斷,訊息丟失的情況下,系統如果還能正常工作,就是有比較好的分割槽容錯性。
CAP的證明
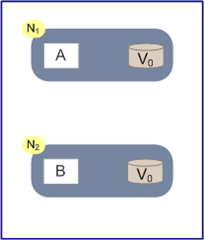
如上圖,是我們證明CAP的基本場景,網路中有兩個節點N1和N2,可以簡單的理解N1和N2分別是兩臺計算機,他們之間網路可以連通,N1中有一個應用程式A,和一個數據庫V,N2也有一個應用程式B2和一個數據庫V。現在,A和B是分散式系統的兩個部分,V是分散式系統的資料儲存的兩個子資料庫。
在滿足一致性的時候,N1和N2中的資料是一樣的,V0=V0。在滿足可用性的時候,使用者不管是請求N1或者N2,都會得到立即響應。在滿足分割槽容錯性的情況下,N1和N2有任何一方宕機,或者網路不通的時候,都不會影響N1和N2彼此之間的正常運作。
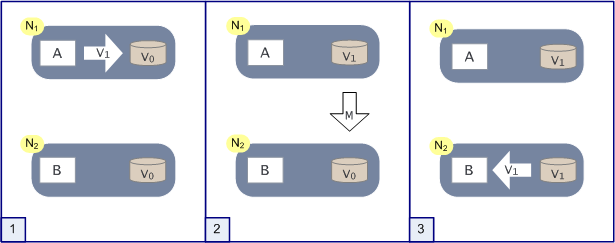
如上圖,是分散式系統正常運轉的流程,使用者向N1機器請求資料更新,程式A更新資料庫Vo為V1,分散式系統將資料進行同步操作M,將V1同步的N2中V0,使得N2中的資料V0也更新為V1,N2中的資料再響應N2的請求。
這裡,可以定義N1和N2的資料庫V之間的資料是否一樣為一致性;外部對N1和N2的請求響應為可用行;N1和N2之間的網路環境為分割槽容錯性。這是正常運作的場景,也是理想的場景,然而現實是殘酷的,當錯誤發生的時候,一致性和可用性還有分割槽容錯性,是否能同時滿足,還是說要進行取捨呢?
作為一個分散式系統,它和單機系統的最大區別,就在於網路,現在假設一種極端情況,N1和N2之間的網路斷開了,我們要支援這種網路異常,相當於要滿足分割槽容錯性,能不能同時滿足一致性和響應性呢?還是說要對他們進行取捨。
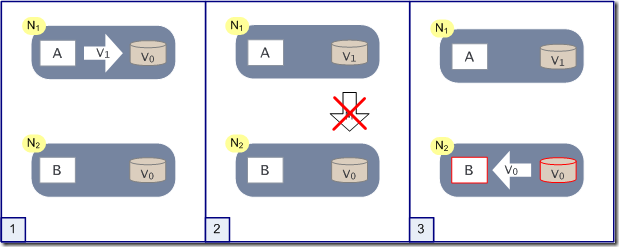
假設在N1和N2之間網路斷開的時候,有使用者向N1傳送資料更新請求,那N1中的資料V0將被更新為V1,由於網路是斷開的,所以分散式系統同步操作M,所以N2中的資料依舊是V0;這個時候,有使用者向N2傳送資料讀取請求,由於資料還沒有進行同步,應用程式沒辦法立即給使用者返回最新的資料V1,怎麼辦呢?
有二種選擇,第一,犧牲資料一致性,保證可用性。響應舊的資料V0給使用者;
第二,犧牲可用性,保證資料一致性。阻塞等待,直到網路連線恢復,資料更新操作M完成之後,再給使用者響應最新的資料V1。
這個過程,證明了要滿足分割槽容錯性的分散式系統,只能在一致性和可用性兩者中,選擇其中一個。
CAP權衡
通過CAP理論及前面的證明,我們知道無法同時滿足一致性、可用性和分割槽容錯性這三個特性,那要捨棄哪個呢?
我們分三種情況來闡述一下。
CA without P
這種情況在分散式系統中幾乎是不存在的。首先在分散式環境下,網路分割槽是一個自然的事實。因為分割槽是必然的,所以如果捨棄P,意味著要捨棄分散式系統。那也就沒有必要再討論CAP理論了。這也是為什麼在前面的CAP證明中,我們以系統滿足P為前提論述了無法同時滿足C和A。
比如我們熟知的關係型資料庫,如My Sql和Oracle就是保證了可用性和資料一致性,但是他並不是個分散式系統。一旦關係型資料庫要考慮主備同步、叢集部署等就必須要把P也考慮進來。
其實,在CAP理論中。C,A,P三者並不是平等的,CAP之父在《Spanner,真時,CAP理論》一文中寫到:
如果說Spanner真有什麼特別之處,那就是谷歌的廣域網。Google通過建立私有網路以及強大的網路工程能力來保證P,在多年運營改進的基礎上,在生產環境中可以最大程度的減少分割槽發生,從而實現高可用性。
從Google的經驗中可以得到的結論是,無法通過降低CA來提升P。要想提升系統的分割槽容錯性,需要通過提升基礎設施的穩定性來保障。
所以,對於一個分散式系統來說。P是一個基本要求,CAP三者中,只能在CA兩者之間做權衡,並且要想盡辦法提升P。
CP without A
如果一個分散式系統不要求強的可用性,即容許系統停機或者長時間無響應的話,就可以在CAP三者中保障CP而捨棄A。
一個保證了CP而一個捨棄了A的分散式系統,一旦發生網路故障或者訊息丟失等情況,就要犧牲使用者的體驗,等待所有資料全部一致了之後再讓使用者訪問系統。
設計成CP的系統其實也不少,其中最典型的就是很多分散式資料庫,他們都是設計成CP的。在發生極端情況時,優先保證資料的強一致性,代價就是捨棄系統的可用性。如Redis、HBase等,還有分散式系統中常用的Zookeeper也是在CAP三者之中選擇優先保證CP的。
無論是像Redis、HBase這種分散式儲存系統,還是像Zookeeper這種分散式協調元件。資料的一致性是他們最最基本的要求。一個連資料一致性都保證不了的分散式儲存要他有何用?
在我的Zookeeper介紹(二)——Zookeeper概述一文中其實介紹過zk關於CAP的思考,這裡再簡單回顧一下:
ZooKeeper是個CP(一致性+分割槽容錯性)的,即任何時刻對ZooKeeper的訪問請求能得到一致的資料結果,同時系統對網路分割具備容錯性。但是它不能保證每次服務請求的可用性,也就是在極端環境下,ZooKeeper可能會丟棄一些請求,消費者程式需要重新請求才能獲得結果。ZooKeeper是分散式協調服務,它的職責是保證資料在其管轄下的所有服務之間保持同步、一致。所以就不難理解為什麼ZooKeeper被設計成CP而不是AP特性的了。
AP wihtout C
要高可用並允許分割槽,則需放棄一致性。一旦網路問題發生,節點之間可能會失去聯絡。為了保證高可用,需要在使用者訪問時可以馬上得到返回,則每個節點只能用本地資料提供服務,而這樣會導致全域性資料的不一致性。
這種捨棄強一致性而保證系統的分割槽容錯性和可用性的場景和案例非常多。前面我們介紹可用性的時候說到過,很多系統在可用性方面會做很多事情來保證系統的全年可用性可以達到N個9,所以,對於很多業務系統來說,比如淘寶的購物,12306的買票。都是在可用性和一致性之間捨棄了一致性而選擇可用性。
你在12306買票的時候肯定遇到過這種場景,當你購買的時候提示你是有票的(但是可能實際已經沒票了),你也正常的去輸入驗證碼,下單了。但是過了一會系統提示你下單失敗,餘票不足。這其實就是先在可用性方面保證系統可以正常的服務,然後在資料的一致性方面做了些犧牲,會影響一些使用者體驗,但是也不至於造成使用者流程的嚴重阻塞。
但是,我們說很多網站犧牲了一致性,選擇了可用性,這其實也不準確的。就比如上面的買票的例子,其實捨棄的只是強一致性。退而求其次保證了最終一致性。也就是說,雖然下單的瞬間,關於車票的庫存可能存在資料不一致的情況,但是過了一段時間,還是要保證最終一致性的。
對於多數大型網際網路應用的場景,主機眾多、部署分散,而且現在的叢集規模越來越大,所以節點故障、網路故障是常態,而且要保證服務可用性達到N個9,即保證P和A,捨棄C(退而求其次保證最終一致性)。雖然某些地方會影響客戶體驗,但沒達到造成使用者流程的嚴重程度。
適合的才是最好的
上面介紹瞭如何CAP中權衡及取捨以及典型的案例。孰優孰略,沒有定論,只能根據場景定奪,適合的才是最好的。
對於涉及到錢財這樣不能有一絲讓步的場景,C必須保證。網路發生故障寧可停止服務,這是保證CA,捨棄P。比如前幾年支付寶光纜被挖斷的事件,在網路出現故障的時候,支付寶就在可用性和資料一致性之間選擇了資料一致性,使用者感受到的是支付寶系統長時間宕機,但是其實背後是無數的工程師在恢復資料,保證數資料的一致性。
對於其他場景,比較普遍的做法是選擇可用性和分割槽容錯性,捨棄強一致性,退而求其次使用最終一致性來保證資料的安全。這其實是分散式領域的另外一個理論——BASE理論。我們下一篇文章再來介紹。
總結
無論你是一個架構師,還是一個普通開發,在設計或開發分散式系統的時候,不可避免的要在CAP中做權衡。需要根據自己的系統的實際情況,選擇最適合自己的方案。