
Python爬蟲-速度(3)
Python爬蟲-速度(3)
文章目錄
018.11.11
前言
早之前是以為會一口氣把爬蟲這個系列了結的,但不知何故,居然沒做到——我肯定不會怪罪自己的拖延症呀!只是有開頭就得有結尾,畢竟我是那麼那麼注重儀式感的人。
再從GitHub把程式碼clone下來,發現不能用了。刨根問底,居然是學校就業網站改版,這倒令我驚奇。會是因為哪個老師或者學生確實無聊所以動了“美好校園”的念頭?緣由於我來說肯定是不得而知的。
重寫一份吧。結構上相比兩個月前的程式碼是有所優化的,但不至於天壤之別。相似處多,所以不再單獨對此次基礎程式碼進行說明。
此篇目的是:基於(2)的提速方法,改寫(1)爬蟲程式碼。當然了,因為網頁改版,接下來我會是基於新的程式碼來改寫。
那就開始啦。
普通爬蟲
此次程式碼對應目錄:NewSchoolJobsCrawl
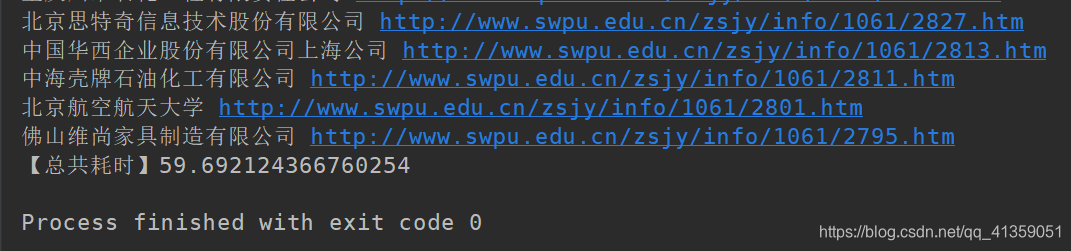
效果如下:
多次執行,整個程式跑完在60s左右。
多程序提速
在ProcessPoolExecutor助攻下,多程序爬蟲的實現真的會很簡單。我們只需要把瀏覽頁處理的邏輯提取出來(我把它放到了main()中),然後構建一個程序池去執行這部分的程式碼就好。這樣說會很抽象,將下面的程式碼與普通爬蟲的程式碼做對比,理解起來容易些。
def main(url):
html, __ = get_one_html(url)
if html:
for title, url in extract_title_url(html):
# 只保留公司名
companyName = re.split(r"(|\(|\s", title)[0]
mkdir(companyName)
# 詳情頁面,詳情頁連結
detailHtml, curUrl = get_one_html(join_url( 平均耗時:10s上下
多執行緒提速
同樣的,有了ThreadPoolExecutor後,多執行緒也變得簡單起來。除了類名,其他部分可以完全和多程序的程式碼一樣。
from concurrent.futures import ThreadPoolExecutor
...
if __name__ == "__main__":
...
with ThreadPoolExecutor() as pool:
pool.map(main, urls)
...
平均耗時:9s+
非同步協程提速
非同步協程的改動會大一些,這是因為requests模組不支援非同步操作。我們需要藉助aiohttp來封裝一個get請求方式的get()方法如下:
async def get(url, referer=None):
headers = HEADERS
if referer is not None:
r = {"Referer": str(referer)}
headers.update(r)
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as response:
text = await response.read()
url = response.url
assert response.status == 200
return text, url
通過這個方法,就可以實現非同步操作了。
其他地方也需要做相應的調整,比如async修飾的函式,呼叫時需要await關鍵字,但都是小問題。更多需要在意協程是如何使用的。
if __name__ == "__main__":
start = time.time()
init()
# fstring python3.7特性
suffix = (f"/{i}" for i in range(1, 23))
# 注意這一部分的改動
urls = [re.sub(r".htm", str(page)+".htm", MAIN_URL) for page in chain([""], suffix)]
tasks = [asyncio.ensure_future(main(url)) for url in urls]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
# --------注意線-------------
end = time.time()
takeTime = end - start
print(f"【總共耗時】{takeTime}")
平均耗時:9s+
最後
感覺這一次寫得很“潦草”,這是沒辦法的事兒。因為以上三個內容(多程序,多執行緒,協程)每一個都可以拿出來單獨寫好長一篇。可我這個系列是:爬蟲。為了不客奪主位,只好一切從簡。
但無論如何是有說到的爬蟲提速的,讓我的爬蟲系列有頭有尾——雖然虎頭蛇尾。
這次展示的三個提速程式碼,並非將速度達到極致,許多地方還可以優化,但我並不建議如此。因為出於興趣愛好的爬蟲,真的沒有必要分秒必爭,況且網站的運維人員也需要休息、娛樂,也需要陪陪家人。而不是一直待公司跟你玩兒“貓捉老鼠”吧!
完整程式碼已經上傳GitHub