
第18章 行為型模式—迭代器模式
1. 迭代器模式(Iterator Pattern)的定義
(1)定義:提供一種方法順序訪問一個聚合物件中的各個元素,而又不需要暴露該物件的內部表示。
①迭代器迭代的是具體的聚合物件(如陣列和連結串列等),它圍繞的是“訪問”做文章。
②可用不同的遍歷策略來遍歷聚合,比如是否需要過濾
③為不同聚合結構提供統一的迭代介面,也就是說通過一個迭代介面可以訪問不同的聚合結構,這叫做多型迭代。標準的迭代模式實現基本上都是支援多型迭代的。如用同一個迭代介面來實現對陣列和連結串列的遍歷。
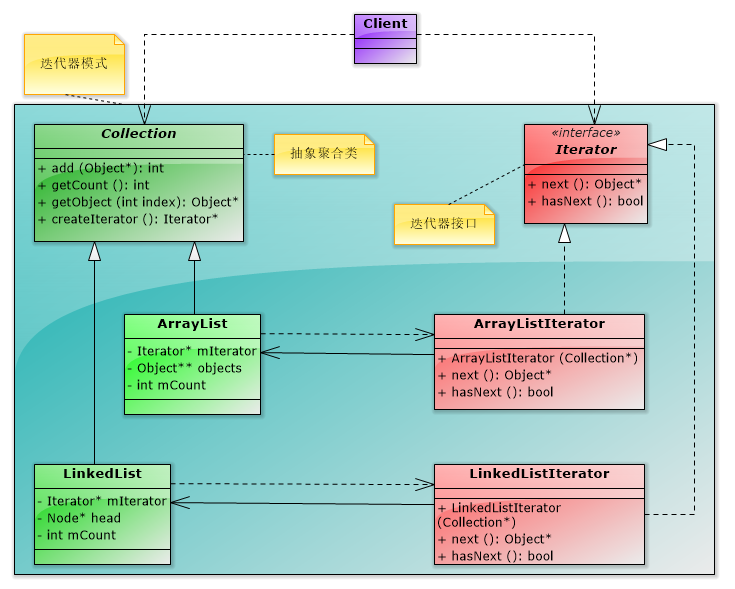
(2)迭代器模式的結構和說明

①Iterator:迭代器介面。定義訪問和遍歷元素的介面。
②ConcreteInterator:具體的迭代器實現物件,會持有被迭代的具體的聚合物件的引用,並對聚合物件的遍歷及跟蹤遍歷時的當前位置。
③Aggregate:聚合物件。提供建立相應迭代器物件的函式(如createIterator())。
④ConcreteAggregate:具體聚合物件。實現建立相應迭代器物件。
【程式設計實驗】以統一的方式對陣列和連結串列進行遍歷(多型迭代)
//行為模式——迭代器模式 //場景:統一陣列類和連結串列類的操作及遍歷方法 //說明:1、本例項沒有采用內部類來實現具體的迭代器,目的是 // 為了演示與課本相同的結構圖 // 2、呼叫next方法,除了可以獲得相應元素,而且遊標下移一個。 #include <iostream> #include <string> using namespace std; //前向宣告 class Iterator; //***************************輔助類*************************** //容器儲存的物件 class Object { private: int id; public: Object(int id = 0) { this->id = id; } void toString() { cout << "Object:" << id << endl; } }; //連結串列節點 struct Node { Node* next; Object* data; Node(Object* data, Node* next) { this->next = next; this->data = data; } }; //*******************************聚合類(Aggregate)介面************************ //抽象聚合類 class Collection { public: virtual int add(Object* o) = 0; virtual int getCount() = 0; virtual Iterator* createIterator() = 0; virtual Object* getObject(int index) = 0; }; //***********************************迭代器介面******************************* //抽象迭代器 class Iterator { public: virtual Object* next() = 0; virtual bool hasNext() = 0; virtual ~Iterator(){} }; //****************************************具體迭代器******************************* //陣列類的迭代器(因專為陣列提供迭代,可以直接嵌入陣列類作為其內部類使用, //但這裡為了與課本一致,先暫時分開) class ArrayListIterator : public Iterator { private: int currentIndex; Collection* clt; public: ArrayListIterator(Collection* clt) { this ->clt = clt; currentIndex = 0; } Object* next() { return clt->getObject(currentIndex++); } bool hasNext() { bool bRet = currentIndex < clt->getCount(); return (bRet); } }; //連結串列類迭代器 class LinkedListIterator : public Iterator { private: Collection* clt; int currentIndex; public: LinkedListIterator(Collection* clt) { this -> clt = clt; currentIndex = 0; } Object* next() { return clt->getObject(currentIndex++); } bool hasNext() { bool bRet = currentIndex < clt->getCount(); return (bRet); } }; //************************************具體聚合類**************************************** //陣列類 class ArrayList : public Collection { private: Object** objects; //物件陣列; int mCount; int mSize; Iterator* mIterator; public: ArrayList() { mSize = 10; mCount = 0; objects = new Object*[mSize]; mIterator = NULL; } int getCount() { return mCount; } int add(Object* o) { if(mCount == mSize) { //擴大陣列大小 mSize += 10; Object** newObjects = new Object*[mSize]; //複製 for(int i = 0; i < mSize; i++) { newObjects[i] = objects[i]; } //刪除原陣列,並更新objects指標 delete[] objects; objects = newObjects; } objects[mCount] = o; return mCount++; } Object* getObject(int index) { return objects[index]; } Iterator* createIterator() { if(mIterator == NULL) mIterator = new ArrayListIterator(this); return mIterator; } ~ArrayList() { delete[] objects; delete mIterator; } }; //連結串列類 class LinkedList : public Collection { private: Node* head; Node* tail; int mCount; Iterator* mIterator; public: LinkedList() { head = NULL; tail = NULL; mCount = 0; mIterator = NULL; } int add(Object* o) { int index = mCount; if(o != NULL) { Node* node = new Node(o, NULL); if(head == NULL) { head = node; tail = node; } tail->next = node; tail = node; ++mCount; } return index; } int getCount() { return mCount; } Iterator* createIterator() { if(mIterator == NULL) mIterator = new LinkedListIterator(this); return mIterator; } Object* getObject(int index) { int tmpIndex = 0; Object* ret = NULL; Node* node = head; while(node != NULL && tmpIndex <=index) { if(tmpIndex == index) { ret = node->data; break; } node = node->next; ++tmpIndex; } return ret; } ~LinkedList() { //清空連結串列 Node* node = head; Node* curr = NULL; while(node != NULL) { curr = node; delete node; node = curr->next; } delete mIterator; } }; int main() { //Collection* c = new ArrayList(); Collection* c = new LinkedList(); //面向介面程式設計,由於陣列類和連結串列類繼承自同一介面 //所以他們具有一的操作(如增加元素) for(int i = 0; i < 15; i++) { c->add(new Object(i)); } //由於Collection提供迭代器的介面, //所以可以該介面對Collection及子類物件進行遍歷 Iterator* iter = c->createIterator(); //面向介面程式設計, while(iter->hasNext()) { Object* obj = iter->next(); (*obj).toString(); delete obj; } return 0; }
2. 思考迭代器模式
(1)迭代器的本質:控制訪問聚合物件中的元素。迭代器能實現“無須暴露聚合物件的內部實現,就能夠訪問到聚合物件的各個元素的功能”,做到“透明”的訪問聚合物件中的元素。注意迭代器能夠即“透明”訪問,又可以“控制訪問”聚合物件,認識這點,對於識別和變形使用迭代器模式很有幫助。
(2)迭代器的關鍵思想:把對聚合物件的遍歷訪問從聚合物件中分離出來,放入單獨的迭代器中,這樣聚合物件會變得簡單,而且迭代器和聚合物件可以獨立地變化和發展,會大大加強系統的靈活性。
(3)迭代器的動機:
在軟體構建過程中,集合物件內部結構常常變化各異。但對於這些集合物件,我們希望在不暴露其內部結構的同時,可以讓外部客戶程式碼透明地訪問其中包含的元素;同時這種“透明遍歷”也為“同一種演算法在多種集合物件上進行操作”提供了可能。將遍歷機制抽象為“迭代器物件”為“應對變化中的集合物件”提供了一種優雅的方法
(4)內部迭代器與外部迭代器
①內部迭代器:指的是由迭代器自己來控制下一個元素的步驟,即當客戶端利用迭代器讀取當前元素後,迭代器的當前元素自動移到一下個元素,而客戶端無法干預。
②外部迭代器:則客戶端控制迭代下一個元素的步驟,即客戶端必須顯示的next來迭代下一個元素。從總體來說外部迭代器比內部迭代器要靈活一些。這也是常見的實現方式。
【程式設計實驗】簡單模仿STL庫容器類的遍歷方式(變式迭代器)
//行為模式——迭代器模式
//場景:簡單仿STL容器類的Iterator
//說明:該模式主要用於將列表的訪問和遍歷分離出來並放進一個迭代器中,
//本例是模仿STL庫的容量遍歷方式
#include <iostream>
#include <string>
using namespace std;
class ArrayList
{
private:
int cnt;
int arr[100];
public:
typedef int* Iterator; //內部類(型)
ArrayList(){cnt = 0;}
//這裡可以看出來Iterator宣告為一個Int*型別的指標
Iterator begin()
{
return &arr[0];
}
Iterator end()
{
return &arr[cnt];
}
void insert(int v)
{
if(cnt>=100)
{
cout << "列表容量己滿,不可再插入" << endl;
return;
}
arr[cnt++] = v;
}
};
int main()
{
ArrayList al;
for(int i = 0; i< 110; i++)
{
al.insert(i);
}
ArrayList::Iterator iter = al.begin();
while( iter != al.end())
{
cout << *iter << endl;
++iter;
}
return 0;
}3. 迭代器模式高階應用
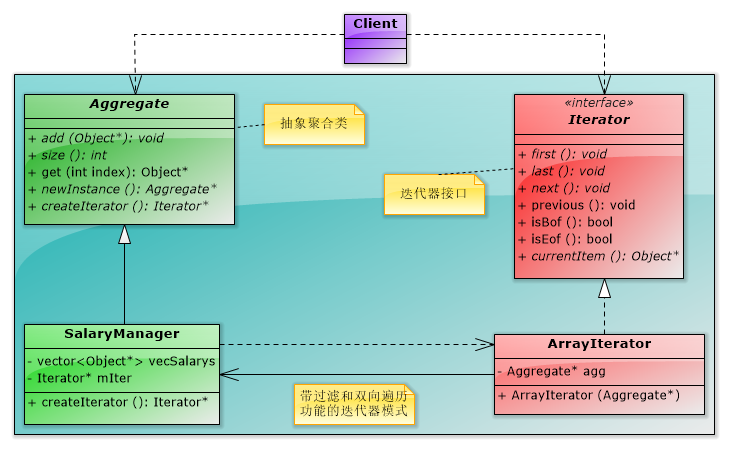
(1)帶迭代策略的迭代器
①由於迭代器模式把聚合物件和訪問聚合的機制實現了分離,因此可以在迭代器上實現不同的迭代策略,如實現過濾功能的迭代器
②在實現過濾功能的迭代器中,有兩種常見的過濾情況,一是對資料整條過濾,如只能檢視自己部門的資料;另一種情況是對資料進行部分過濾,如某些人不能檢視工資資料。
③帶迭代策略的迭代器實現的一個基本思路就是把聚合物件的聚合資料獲取到並存儲在迭代器中,這樣迭代器就可以按照不同的策略來迭代資料了。
(2)雙向迭代器:可以向前和向後遍歷資料的迭代器
【程式設計實驗】帶過濾和雙向遍歷功能的工資檢視系統
//行為模式——迭代器模式
//場景:工資表資料遍歷(帶過濾和雙向遍歷功能)
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//***************************輔助類*************************
//前向宣告
class Iterator;
class SalaryModel;
typedef SalaryModel Object;
//工資描述模型物件
class SalaryModel
{
private:
string userName; //職工姓名
double salary; //工資數額
public:
string& getUserName(){return userName;}
void setUserName(string name)
{
this->userName = name;
}
double getSalary(){return salary;}
void setSalary(double salary)
{
this->salary = salary;
}
void toString()
{
cout << "userName = " << userName
<<", Salary = " << salary << endl;
}
};
//**********************迭代器介面***************************
//迭代器介面,定義訪問和遍歷元素的操作(雙向遍歷)
class Iterator
{
public:
//移動到聚合物件的第一個位置
virtual void first() = 0;
//移動到最後一個位置
virtual void last() = 0;
//移動到聚合物件的下一個位置
virtual void next() = 0;
//移動到聚合物件的上一個位置
virtual void previous() = 0;
//判斷是否到了尾部位置
virtual bool isEof() = 0;
//判斷是否到了頭部位置
virtual bool isBof() = 0;
//獲取當前元素
virtual Object* currentItem() = 0;
virtual ~Iterator(){};
};
//************************************抽象聚合類**************************
//聚合物件的介面
class Aggregate
{
public:
//建立相應迭代器物件的介面
virtual Iterator* createIterator() = 0;
//獲取數量大小
virtual int size() = 0;
//獲取指定位置的元素
virtual Object* get(int index) = 0;
//加入元素
virtual void add(Object* o) = 0;
virtual Aggregate* newInstance() {return NULL;}
virtual ~Aggregate(){}
};
//***********************具體迭代器*****************************
//具體的迭代器物件
//用來實現訪問陣列的迭代介面,加入了迭代策略
//其主要思路就是在ArrayInterator中儲存一份過濾後的Aggregate聚合物件資料。
class ArrayIterator : public Iterator
{
private:
Aggregate* agg;
//記錄當前迭代到的位置索引
int index;
public:
ArrayIterator(Aggregate* agg)
{
index = 0;
//在這裡先對聚合物件的資料進行過濾,比如必須在3000以上
this ->agg = agg->newInstance();//原型模式,根據agg的實際型別建立物件
//下面用一般遍歷方法,而不agg的迭代器,否則那樣會造成死迴圈。
for(int i = 0;i < agg->size(); i++)
{
Object* obj = agg->get(i);
if (obj->getSalary()> 3000)
{
this->agg->add(obj);
}
}
}
void first()//移動到聚合物件的第1個位置
{
index = 0;
}
void last()//移動到聚合物件的最後一個位置
{
index = agg->size() -1;
}
//移動到聚合物件的下一個位置
void next()
{
if(index < agg->size())
++index;
}
//移動到前一個位置
void previous()
{
if(index>=0)
{
--index;
}
}
//判斷是否到了尾部位置
bool isEof()
{
return (index >= agg->size());
}
//判斷是否到了頭部位置
bool isBof()
{
return (index < 0);
}
//獲取當前元素
Object* currentItem()
{
//在這裡對返回的資料進行過濾,比如不讓檢視具體的工資資料
Object* obj = agg->get(index);
obj->setSalary(0);
return obj;
}
~ArrayIterator()
{
delete agg;
}
};
//用陣列模擬具體的聚合物件
class SalaryManager : public Aggregate
{
private:
//聚合物件
vector<Object*> vecSalarys; //陣列
//提供建立具體迭代器的介面
Iterator* mIter;
public:
SalaryManager()
{
mIter = NULL;
}
Iterator* createIterator()
{
if (mIter == NULL)
{
mIter = new ArrayIterator(this);
}
return mIter;
}
//獲取數量大小
int size()
{
return vecSalarys.size();
}
//獲取指定位置的元素
Object* get(int index)
{
return vecSalarys[index];
}
//加入元素
void add(Object* o)
{
vecSalarys.push_back(o);
}
Aggregate* newInstance()
{
Aggregate* ret = new SalaryManager();
return ret;
}
~SalaryManager()
{
delete mIter;
vecSalarys.clear();
}
};
int main()
{
Aggregate* agg = new SalaryManager();
//為了測試,輸入些資料進去
SalaryModel* sm = new SalaryModel();
sm->setSalary(3800);
sm->setUserName("張三");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(5800);
sm->setUserName("李四");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(2200);
sm->setUserName("王五");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(3500);
sm->setUserName("趙六");
agg->add(sm);
Iterator* it = agg->createIterator();
//正向遍歷
it->first();
while(!it->isEof())
{
it->currentItem()->toString();
it->next();
}
//返向遍歷、
it->last();
while(!it->isBof())
{
it->currentItem()->toString();
it->previous();
}
return 0;
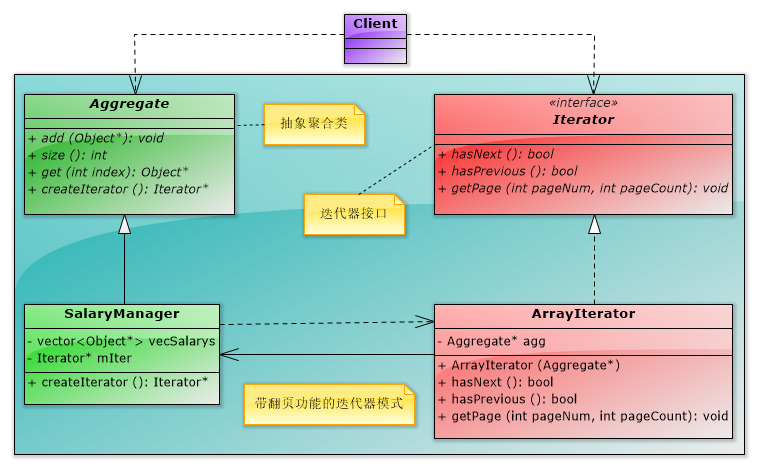
}(3)翻頁迭代器
①在資料庫訪問中,如果每頁顯示10條記錄,通常使用者很少翻到10頁以後,那麼在第一次訪問時,可以從從資料庫中獲取前10頁的資料,即100條記錄放在記憶體裡。
②當用戶在前10頁進行翻頁操作時,就可以不再訪問資料庫而是直接從記憶體中獲取資料,速度就快了。
③當想獲取第11頁的資料時,才會再次訪問資料庫。而翻頁迭代的意思是一次迭代要求取出一頁的資料,而不是一條資料。所以其實現主要把原來一次迭代一條資料的介面,都修改成一次迭代一頁的資料就可以了。
【程式設計實驗】帶隨機翻頁功能的工資檢視系統
//行為模式——迭代器模式
//場景:工資表資料遍歷(帶隨機翻頁功能)
//說明:翻頁即每頁讀取若干條記錄,
// 隨機指可以指定頁數和每頁的記錄數的訪問方式,
// 而不是按順序訪問頁面.
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//***************************輔助類*************************
//前向宣告
class Iterator;
class SalaryModel;
typedef SalaryModel Object;
//工資描述模型物件
class SalaryModel
{
private:
string userName; //職工姓名
double salary; //工資數額
public:
string& getUserName(){return userName;}
void setUserName(string name)
{
this->userName = name;
}
double getSalary(){return salary;}
void setSalary(double salary)
{
this->salary = salary;
}
void toString()
{
cout << "userName = " << userName
<<", Salary = " << salary << endl;
}
};
//**********************迭代器介面***************************
//迭代器介面,定義訪問和遍歷元素的操作(雙向遍歷)
class Iterator
{
public:
//判斷是否還有下一個元素,無所謂是否夠一頁資料
//因為最後哪怕只有一條資料,也是要算一頁。
virtual bool hasNext() = 0;
//判斷是否還有上一個元素,無所謂是否夠一頁資料
//因為最後哪怕只有一條資料,也是要算一頁。
virtual bool hasPrevious() = 0;
//獲取指定頁號和每頁顯示的數量
virtual void getPage(int pageNum, int pageCount) = 0;
virtual ~Iterator(){};
};
//************************************抽象聚合類**************************
//聚合物件的介面
class Aggregate
{
public:
//建立相應迭代器物件的介面
virtual Iterator* createIterator() = 0;
//獲取數量大小
virtual int size() = 0;
//獲取指定位置的元素
virtual Object* get(int index) = 0;
//加入元素
virtual void add(Object* o) = 0;
virtual Aggregate* newInstance() {return NULL;}
virtual ~Aggregate(){}
};
//***********************具體迭代器*****************************
//具體的迭代器物件
//用來實現訪問陣列的迭代介面,加入了迭代策略
//其主要思路就是在ArrayInterator中儲存一份過濾後的Aggregate聚合物件資料。
class ArrayIterator : public Iterator
{
private:
Aggregate* agg;
//記錄當前迭代到的位置索引
int index;
public:
ArrayIterator(Aggregate* agg)
{
index = 0;
this ->agg = agg;
}
//判斷是否還有下一個元素,無所謂是否夠一頁資料
//因為最後哪怕只有一條資料,也是要算一頁。
bool hasNext()
{
return (index <agg->size());
}
//判斷是否還有上一個元素,無所謂是否夠一頁資料
//因為最後哪怕只有一條資料,也是要算一頁。
bool hasPrevious()
{
return (index >0);
}
//獲取指定頁號和每頁顯示的數量
void getPage(int pageNum, int pageCount)
{
//這裡可讀取到的資料通過陣列或連結串列返回給客戶
//但為了簡便,我們在這裡
//計算需要獲取的資料的開始條數和結束條數
int start = (pageNum - 1)* pageCount;
int end = start + pageCount - 1;
//控制start的邊界,最小是0
if(start < 0)
start = 0;
//控制end的邊界
if(end > agg->size()-1)
end = agg->size() -1;
//每次取值都是從頭開始迴圈
index = 0;
while(hasNext() && index <= end)
{
if(index>=start)
{
agg->get(index)->toString();
}
index++;
}
}
};
//用陣列模擬具體的聚合物件
class SalaryManager : public Aggregate
{
private:
//聚合物件
vector<Object*> vecSalarys; //陣列
//提供建立具體迭代器的介面
Iterator* mIter;
public:
SalaryManager()
{
mIter = NULL;
}
Iterator* createIterator()
{
if (mIter == NULL)
{
mIter = new ArrayIterator(this);
}
return mIter;
}
//獲取數量大小
int size()
{
return vecSalarys.size();
}
//獲取指定位置的元素
Object* get(int index)
{
return vecSalarys[index];
}
//加入元素
void add(Object* o)
{
vecSalarys.push_back(o);
}
Aggregate* newInstance()
{
Aggregate* ret = new SalaryManager();
return ret;
}
~SalaryManager()
{
delete mIter;
vecSalarys.clear();
}
};
int main()
{
Aggregate* agg = new SalaryManager();
//為了測試,輸入些資料進去
SalaryModel* sm = new SalaryModel();
sm->setSalary(3800);
sm->setUserName("張三");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(5800);
sm->setUserName("李四");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(2200);
sm->setUserName("王五");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(3500);
sm->setUserName("趙六");
agg->add(sm);
sm = new SalaryModel();
sm->setSalary(2900);
sm->setUserName("錢七");
agg->add(sm);
//得到翻頁迭代器
Iterator* it = agg->createIterator();
//獲取第一頁,每頁顯示2條
cout <<"第1頁資料:" <<endl;
it->getPage(1, 2);
//獲取第2頁,每頁顯示2條
cout <<"第2頁資料:" <<endl;
it->getPage(2, 2);
//再獲取第1頁,每頁顯示2條
cout <<"第1頁資料:" <<endl;
it->getPage(1, 2);
//再獲取第3頁,每頁顯示2條
cout <<"第3頁資料:" <<endl;
it->getPage(3, 2);
return 0;
}4. 迭代器的優缺點
(1)優點
①更好的封裝性,可對一個聚合物件的訪問,而無須暴露聚合物件的內部實現。
②可以不同的遍歷方式來遍歷一個聚合物件(如正向和反向遍歷)
③將聚合物件的內容和具體的迭代演算法分離開,這樣就可以通過使用不同的迭代器例項、不同的遍歷方式來遍歷一個聚合物件。
④簡化客戶端呼叫:迭代器為遍歷不同的聚合物件提供了一個統一的介面,使用客戶端遍歷聚合物件的內容變得更加簡單。
⑤同一個聚合上可以有多個遍歷。每個迭代器保持它自己的遍歷狀態(如索引位置),因此可以對同一個聚合物件同時進行多個遍歷。只要為其設定設計不同的迭代器。
(2)缺點:
①由於迭代器模式將儲存資料和遍歷資料的職責分離,增加新的聚合類需要對應增加新的迭代器類,類的個數成對增加,這在一定程度上增加了系統的複雜性。對於比較簡單的遍歷(像陣列或者有序列表),使用迭代器方式遍歷較為繁瑣。
②迭代器模式在遍歷的同時更改迭代器所在的集合結構會導致出現異常。所以使用foreach語句只能在對集合進行遍歷,不能在遍歷的同時更改集合中的元素。
5. 應用場景
(1)如果希望提供訪問一個聚合物件的內容,但又不想暴露它的內部表示的時候可使用迭代器模式
(2)如果希望有多種遍歷方式可以訪問聚合物件。
(3)如果希望為遍歷不同的聚合物件提供一個統一的介面,可以使用迭代器模式(多型迭代)。
6. 相關模式
(1)迭代器模式和組合模式
組合模式是一種遞迴的物件結構,在列舉某個組合物件的子物件時,通常會使用迭代器模式。
(2)迭代器模式和工廠方法模式
在聚合物件建立迭代器的時候,通常會採用工廠方法模式來例項化相應的迭代器物件。