
[譯]Exactly once is NOT exactly the same
近日學習Pulsar文件時,注意到Pulsar提到其提供的是effectively-once語義,而不是其它流計算引擎announce的exactly-once語義,並引用了Exactly once is NOT exactly the same這篇文章加以註明。此處就將這篇觀點很有意思的文章嘗試翻譯如下:
Exactly once is NOT exactly the same
分散式事件流處理正逐漸成為大資料領域中一個熱門話題。著名的流處理引擎(Streaming Processing Engines, SPEs)包括Apache Storm、Apache Flink、Heron、Apache Kafka(Kafka Streams)以及Apache Spark(Spark Streaming)。流處理引擎中一個著名的且經常被廣泛討論的特徵是它們的處理語義,而“exactly-once”是其中最受歡迎的,同時也有很多引擎聲稱它們提供“exactly-once”處理語義。
然而,圍繞著“exactly-once”究竟是什麼、它牽扯到什麼以及當流處理引擎聲稱提供“exactly-once”語義時它究竟意味著什麼,仍然存在著很多誤解與歧義。而用來描述處理語義的“exactly-once”這一標籤同樣也是非常誤導人的。在這篇博文當中,我將會討論眾多受歡迎的引擎所提供的“exactly-once”語義間的不同之處,以及為什麼“exactly-once”更好的描述是“effective-once
背景
流處理(streaming process),有時也被稱為事件處理(event processing),可以被簡潔地描述為對於一個無限的資料或事件序列的連續處理。一個流,或事件,處理應用可以或多或少地由一個有向圖,通常是一個有向無環圖(DAG),來表達。在這樣一個圖中,每條邊表示一個數據或事件流,而每個頂點表示使用應用定義好的邏輯來處理來自相鄰邊的資料或事件的運算元。其中有兩種特殊的頂點,通常被稱作sources與sinks。Sources消費外部資料/事件並將其注入到應用當中,而sinks通常收集由應用產生的結果。圖1描述了一個流處理應用的例子。
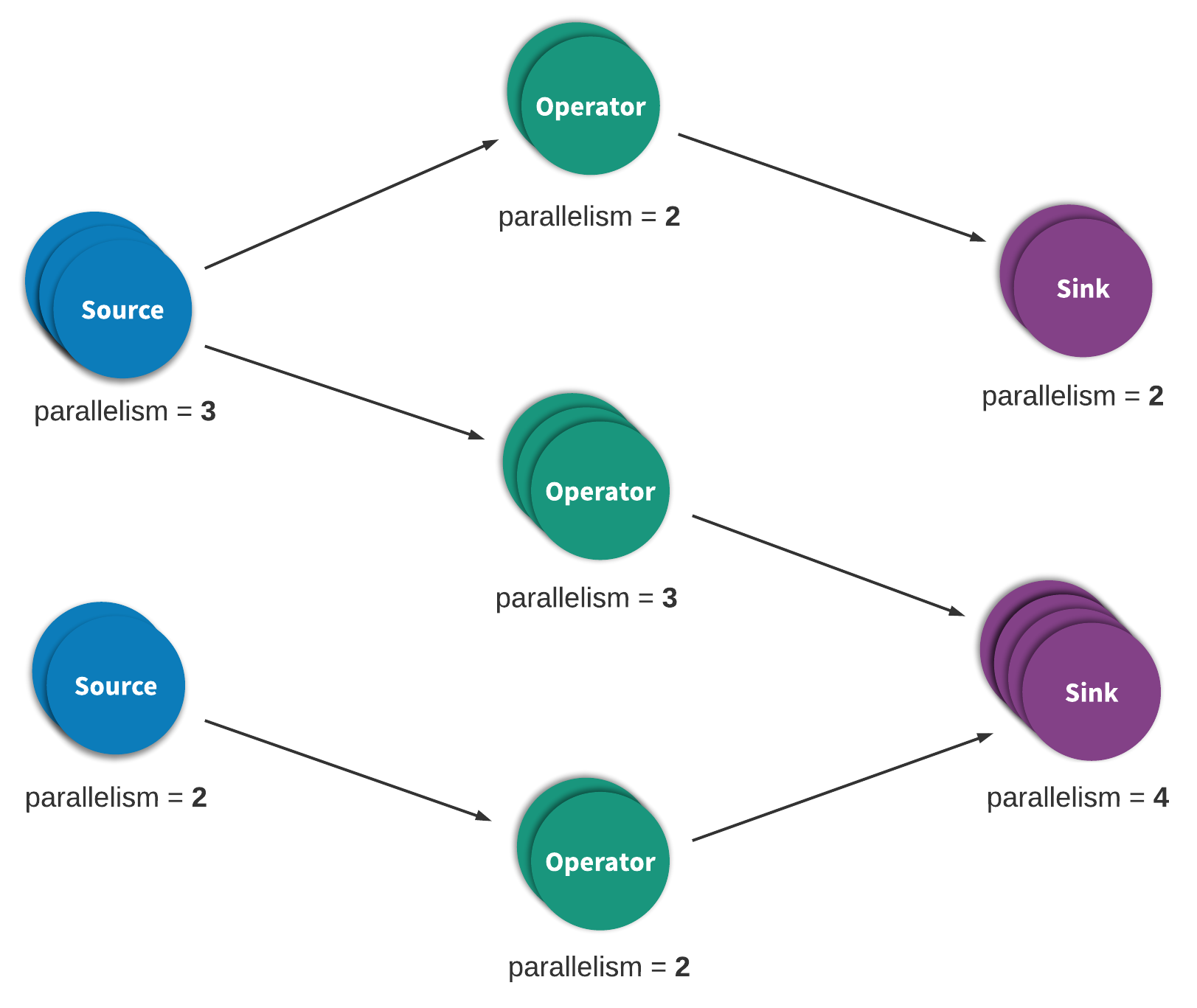
{kind=link}
一個執行流/事件處理應用的流處理引擎通常允許使用者制定一個可靠性模式或者處理語義,來標示引擎會為應用圖的實體之間的資料處理提供什麼樣的保證。由於你總是會遇到網路、機器這些會導致資料丟失的故障,因而這些保證是有意義的。有三種模型/標籤,at-most-once、at-least-once以及exactly-once,通常被用來描述流處理引擎應該為應用提供的資料處理語義。
接下來是對這些不同的處理語義的寬泛的定義:
At-most-once
這實質上是一個“盡力而為”(best effort)的方法。資料或者事件被保證只會被應用中的所有運算元最多處理一次。這就意味著對於流處理應用完全處理它之前丟失的資料,也不會有額外的重試或重傳嘗試。圖2展示了一個相關的例子:

{kind=link}
At-least-once
資料或事件被保證會被應用圖中的所有運算元都至少處理一次。這通常意味著當事件在被應用完全處理之前就丟失的話,其會被從source開始重放(replayed)或重傳(retransmitted)。由於事件會被重傳,那麼一個事件有時就會被處理超過一次,也就是所謂的at-least-once。圖3展示了一個at-least-once的例子。在這一示例中,第一個運算元第一次處理一個事件時失敗,之後在重試時成功,並在結果證明沒有必要的第二次重試時成功。
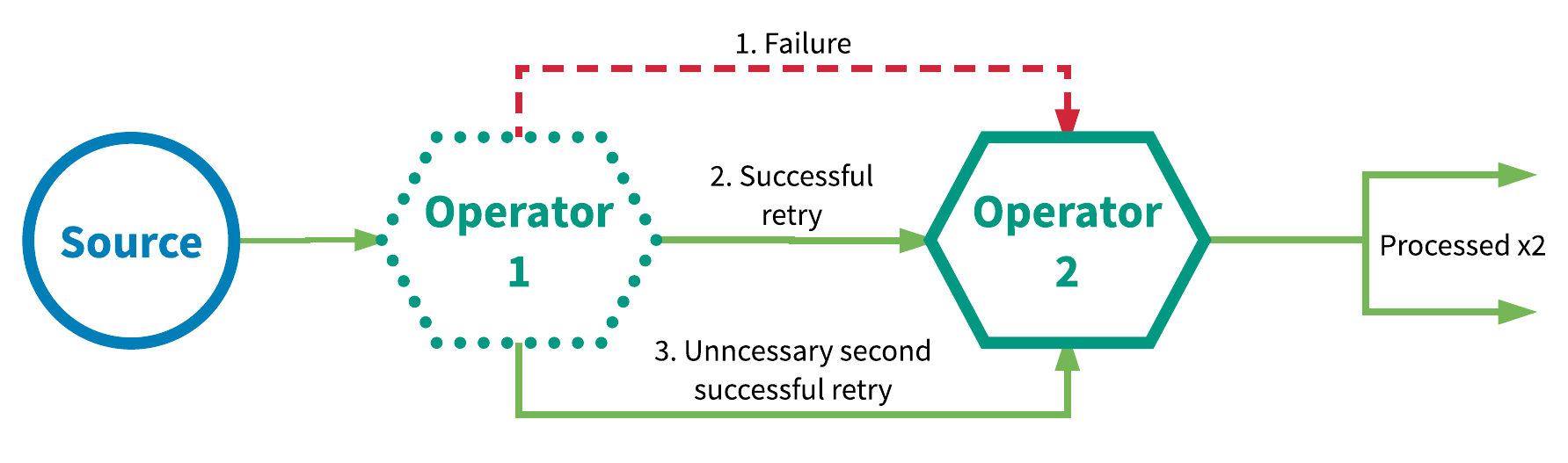
{kind=link}
Exactly-once
倘若發生各種故障,事件也會被確保只會被流應用中的所有運算元“恰好”處理一次。
拿來實現“exactly-once”的有兩種受歡迎的典型機制:
- 分散式快照/狀態檢查點(checkpointing)
- At-least-once的事件投遞加上訊息去重
用來實現“exactly-once”的分散式快照/狀態檢查點方法是受到了Chandy-Lamport分散式快照演算法1的啟發。在這種機制中,流處理應用中的每一個運算元的所有狀態都會週期性地checkpointed。倘若系統發生了故障,每一個運算元的所有狀態都會回滾到最近的全域性一致的檢查點處。在回滾過程中,所有的處理都會暫停。Sources也會根據最近的檢查點重置到正確到offset。整個流處理應用基本上倒回到最近的一致性狀態,處理也可以從這個狀態重新開始。圖4展示了這種機制的基本原理。
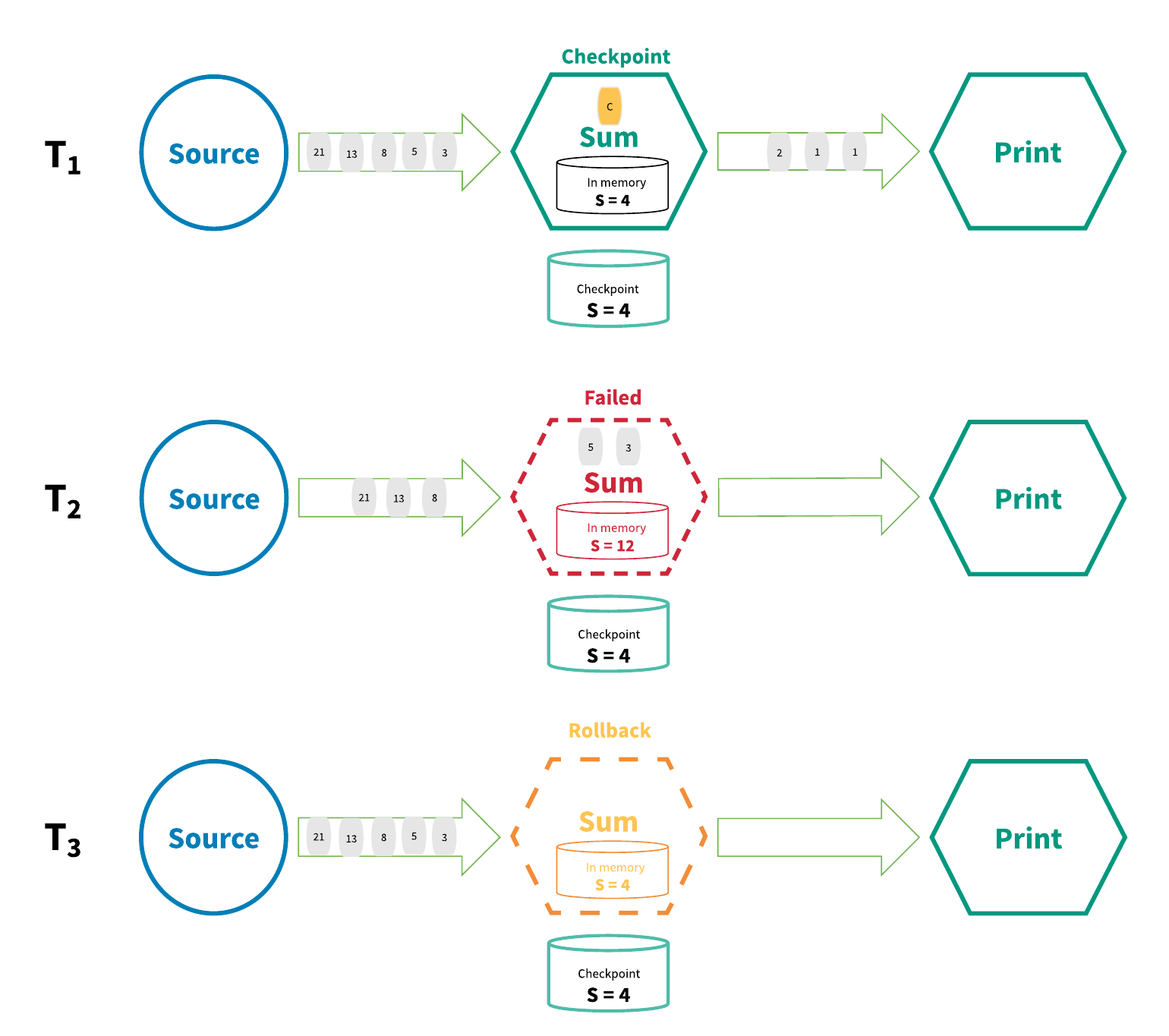
{kind=link}
在圖4中,流處理應用T1時在正常地工作,同時狀態也被checkpointed。T2時,運算元處理一個輸入資料時失敗了。此時,S = 4的狀態已經儲存到了持久化儲存當中,而S = 12的狀態仍然位於運算元的記憶體當中。為了解決這個不一致,T3時processing graph倒回到S = 4的狀態並“重放”流中的每一個狀態直到最新的狀態,並處理每一個數據。最終結果是雖然某些資料被處理了多次,但是無論執行了多少次回滾,結果狀態依然是相同的。
用來實現“exactly-once”的另一種方法是在每一個運算元的基礎上,將at-least-once的事件投遞與事件去重相結合。使用這種方法的引擎會重放失敗的事件以進一步嘗試進行處理,並在每一個運算元上,在事件進入到使用者定義的邏輯之前刪除重複的事件。這一機制需要為每一個運算元維護一份事務日誌(transaction log)來記錄哪些事件已經處理過了。使用類似這一機制的引擎有Google的MillWheel 2與 Apache Kafka Streams。圖5展示了這一機制的重點。
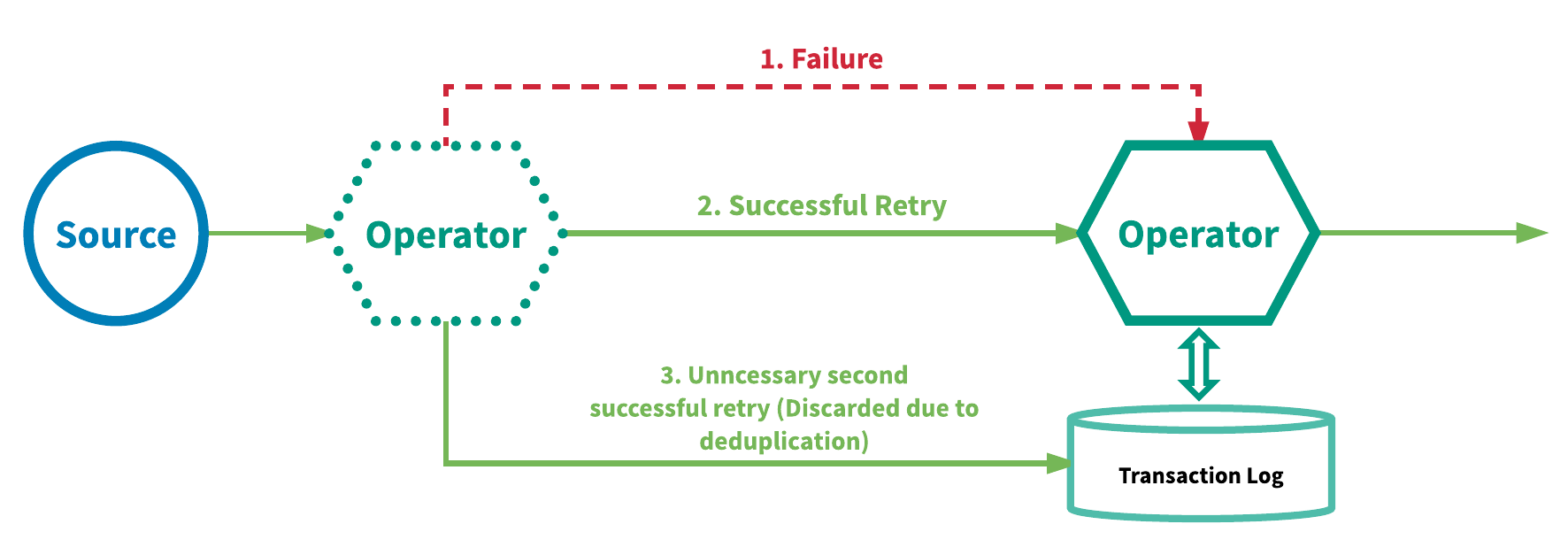
{kind=link}
exactly-once確實是exactly-once嗎?
現在,讓我們來重新審視“exactly-once”究竟為使用者做出了什麼樣的保證。“exactly-once”的標籤對於描述是什麼被執行了“exactly-once”是有誤導性的。
有些人認為“exactly-once”描述的是對於事件處理的保證,在這種保證下流中的每一個事件都只會被處理一次。而現實情況是,沒有一個流處理引擎可以保證“exactly-once”的處理。面對各式各樣的故障,確保每一個運算元上使用者定義的邏輯只對每個事件執行一次是不可能的,因為使用者程式碼的部分執行是一種永遠存在的可能性。
考慮這樣一種場景,你有一個執行map操作的流處理運算元,map操作會列印輸入事件的ID並不加任何改變的將事件返回。下列虛擬碼描述了這個運算元:
Map (Event event) {
Print "Event ID: " + event.getId()
Return event
}每一個事件都擁有一個GUID(Global Unique ID)。如果使用者邏輯的“exactly-once”執行可以被保證的話,那麼每一個事件ID都只會被列印一次。然而,這永遠是得不到保證的,因為故障會發生在使用者定義邏輯執行過程中的任何時間、任何地點。引擎無法靠它自己確定使用者定義的處理邏輯執行到了什麼地方。因此,任意的使用者定義邏輯無法被保證僅被執行一次。這同時也說明了外部的操作,諸如使用者定義的邏輯中實現的資料庫寫入,也無法被保證僅被執行一次。這些操作仍然需要通過冪等的方式來實現。
所以,當引擎聲稱“exactly-once”處理語義時它們究竟保證了什麼?如果使用者定義的邏輯無法確保僅執行一次,那麼什麼是什麼被執行了恰好一次?當引擎聲稱“exactly-once”處理語義時,它們實際上表達的是它們可以確保由引擎管理的對於狀態的更新只會被提交到後端的持久化儲存中一次(what they're actually saying is that they can guarantee that updates to state managed by the SPE are committed only once to a durable backend store)。
上述的所有機制都使用了一個持久化的後端儲存作為事實的來源,來儲存每一個運算元的狀態並自動的提交對於狀態的更新。對於機制1(分散式快照/狀態檢查點),它的後端儲存用來儲存全域性一致的狀態檢查點(每一個運算元的被檢查點記錄下的狀態)。對於機制2(at-least-once的事件投遞加上去重),持久化後端儲存儲存的是每一個運算元的狀態以及記錄了每一個運算元完整處理過的所有事件的事務日誌。
向作為事實來源的持久化後端提交狀態或應用更新可以被描述為只會發生恰好一次。然而,計算狀態的更新/改變,例如在事件上執行任意的使用者定義邏輯,在故障發生時是有可能執行多次的。換而言之,對於事件的處理可能會發生多次,但是那些處理的影響只會反映到持久化後端狀態儲存中一次。在Streamlio,我們已經決定effectively-once是對於這種語義的最好的描述。
分散式快照 vs at-least-once事件傳遞加上去重
從語義的角度,分散式快照與at-least-once事件傳遞加去重機制提供了相同的保證。然而由於兩種機制在實現上的差異,它們之間仍然存在著明顯的效能差異。
流處理引擎上的機制1(分散式快照/狀態檢查點)的效能開銷可以是最小的,因為引擎本質上只是通過流處理應用的所有運算元傳送一部分特殊事件與常規事件,而狀態檢查點可以在後臺非同步執行。然而,對於大型的流處理應用,故障會發生得更頻繁,導致引擎需要暫停應用並回滾所有運算元的狀態,而這反過來又會影響效能。流處理應用規模越大,發生故障的可能性越高、越頻繁,而反過來對於應用效能的影響也越明顯。然而,同樣的,這一機制是非常非入侵性的(non-intrusive),而且只需要最少的額外資源來執行。
機制2(at-least-once事件投遞加上去重)可能會需要更多的資源,尤其是儲存。在這一機制中,引擎需要記錄被一個運算元的每一個例項完整處理過的每一個元組,以便執行去重操作,同時也是為了每一個事件本身執行去重操作。這會導致大量的資料需要記錄,尤其是在流處理應用規模很大或者有多個應用執行的情況下。而與每一個運算元上的每一個事件相關的去重操作同樣存在著效能開銷。然而,在這一機制中,流處理應用的效能不太可能受到應用規模大小的影響。在機制1中,如果任一運算元上發生了任何故障,全域性的暫停以及狀態回滾都需要執行;而在機制2中,一次故障的影響則更為區域性化。當一個運算元上發生了故障,可能沒有被完全處理的事件僅會從上游資料來源開始重放/重傳。這一效能影響獨立於故障發生在應用的哪裡,同樣對這一應用中的其它運算元幾乎不會造成什麼效能上的影響。從效能角度來看,兩種機制的優勢和劣勢如下表所示:
分散式快照/狀態檢查點
| 優勢 | 劣勢 |
|---|---|
| 更少的效能與資源開銷 | 從故障中恢復時對於效能的影響更大 |
| nothing | 拓撲變大時對於效能有潛在影響 |
At-least-once投遞加上去重
| 優勢 | 劣勢 |
|---|---|
| 故障的效能影響是區域性性的 | 可能需要大量儲存與基礎設施來支援 |
| 故障的影響不會隨著拓撲規模的增長而變大 | 每一個運算元的每一個事件都存在效能開銷 |
雖然從理論的角度來看,兩種機制間存在著一些差異,但是它們都可以歸結為at-least-once的處理加上冪等。對於所有的機制,當故障發生時事件都會被重放/重傳(實現at-least-once),然後通過狀態回滾或者事件去重,當內部管理狀態更新時,運算元本質上會變為冪等。
總結
在這篇部落格中,我希望讓你相信“exactly-once”這一名詞是非常有誤導性的。提供“exactly-once”處理語義事實上意味著由流處理引擎管理的對於一個運算元狀態的獨立更新只會被反映一次。“Exactly-once”並不會保證對於事件的處理、尤其是任意使用者定義邏輯的執行,只會發生一次。在Streamlio,對於這種語義我們更喜歡effective once這一名詞,因為不一定保證處理只發生一次,但是對於引擎管理的狀態的影響只會反映一次。兩種受歡迎的機制,分散式快照與訊息去重,被用來實現exactly/effectively-once處理語義。兩種機制對於訊息處理與狀態更新提供了相同的語義保證,但是在效能上有所差異。這篇文章並不是要說服你一種優於另一種,因為每一種機制都有其自己的優勢與劣勢。
參考文獻
- Chandy, K. Mani and Leslie Lamport. Distributed snapshots: Determining global states of distributed systems. ACM Transactions on Computer Systems (TOCS) 3.1 (1985): 63-75.
- Akidau, Tyler, et al. MillWheel: Fault-tolerant stream processing at internet scale. Proceedings of the VLDB Endowment 6.11 (2013): 1033-1044.