
影象分割技術介紹
影象分割(image segmentation)技術是計算機視覺領域的個重要的研究方向,是影象語義理解的重要一環。影象分割是指將影象分成若干具有相似性質的區域的過程,從數學角度來看,影象分割是將影象劃分成互不相交的區域的過程。近些年來隨著深度學習技術的逐步深入,影象分割技術有了突飛猛進的發展,該技術相關的場景物體分割、人體前背景分割、人臉人體Parsing、三維重建等技術已經在無人駕駛、增強現實、安防監控等行業都得到廣泛的應用。

影象分割技術從演算法演進歷程上,大體可劃分為基於圖論的方法、基於畫素聚類的方法和基於深度語義的方法這三大類,在不同的時期湧現出了一批經典的分割演算法。
基於圖論的分割方法
此類方法基於圖論的方法利用圖論領域的理論和方法,將影象對映為帶權無向圖,把畫素視作節點,將影象分割問題看作是圖的頂點劃分問題,利用最小剪下準則得到影象的最佳分割。此類方法把影象分割問題與圖的最小割(MIN-CUT)[1]問題相關聯,通常做法是將待分割的影象對映為帶權無向圖G=(V,E),其中,V={ ,…,
}是頂點的集合,E為邊的集合。圖中每個節點N∈V對應於影象中的每個畫素,每條邊∈E連線著一對相鄰的畫素,邊的權值w(
),其中 (
)∈E,表示了相鄰畫素之間在灰度、顏色或紋理方面的非負相似度。而對影象的一個分割S就是對圖的一個剪下,被分割的每個區域C∈S對應著圖中的一個子圖。
分割的原則就是使劃分後的子圖在內部保持相似度最大,而子圖之間的相似度保持最小。我們以一個兩類的分割為例,把G = (V,E) 分成兩個子集A,B,另: ,CUT(A,B) =
, 其中
, 是權重(weight), 最小割就是讓上式的值最小的分割。

基於圖論的代表有NormalizedCut,GraphCut和GrabCut等方法
-
NormalizedCut[2]
想要理解Normalized Cut 需要先理解什麼是分割(CUT)與最小化分割(MIN-CUT),我們拿下圖做例子,我們把圖一看成一個整體G,現在需要把它分成兩個部分。顯然中間的紅色虛線切割的邊就是最小化分割。
最小化分割解決了把權重圖G分成兩部分的任務,但是問題來了,如下圖所示,想要的結果是中間實線表示的分割,但是最小化切割卻切掉了最邊緣的角。這中情況很容易理解,因為最小化切割就是讓CUT(A,B)的值最小的情況,而邊緣處CUT值確實是最小,因此我們輸最小化切割時會有偏差的(bias)。如何去除這種偏差就要引入Normalized Cut演算法了。

思路很簡單,將Cut normalize一下,除以表現頂點集大小的某種量度(如 vol A = 所有A中頂點集的度之和,含義是A中所有點到圖中所有點的權重的和), 也就是NormalizeCut(A, B) = Cut(A, B) / volA + Cut(A, B) / volB,通過公式可以很清晰的看到NormalizeCut在追求不同子集間點的權重最小值的同時也追求同一子集間點的權重和最大值。
-
GraphCut[3]
Graph Cuts圖是在普通圖的基礎上多了2個頂點,這2個頂點分別用符號”S”和”T”表示,稱為終端頂點。其它所有的頂點都必須和這2個頂點相連形成邊集合中的一部分,所以Graph Cuts中有兩種頂點,也有兩種邊,第一種普通頂點對應於影象中的每個畫素。每兩個鄰域頂點的連線就是一條邊。這種邊也叫n-links。除影象畫素外,還有另外兩個終端頂點,叫S源點和T匯點。每個普通頂點和這2個終端頂點之間都有連線,組成第二種邊,這種邊也叫t-links,如下圖所示。
Graph Cuts中的Cuts是指這樣一個邊的集合,這些邊集合包括了上面定義的2種邊,該集合中所有邊的斷開會導致殘留“S”和“T”圖的分開,所以就稱為“割”。如果一個割,它的邊的所有權值之和最小,那麼這個就稱為最小割,也就是圖割的結果。根據網路中最大流和最小割等價的原理,將影象的最優分割問題轉化為求解對應圖的最小割問題。由Boykov和Kolmogorov發明的max-flow/min-cut演算法[1,4]就可以用來獲得S-T圖的最小割,這個最小割把圖的頂點劃分為兩個不相交的子集S和T,其中s ∈S,t∈ T和S∪T=V 。這兩個子集就對應於影象的前景畫素集和背景畫素集,那就相當於完成了影象分割。
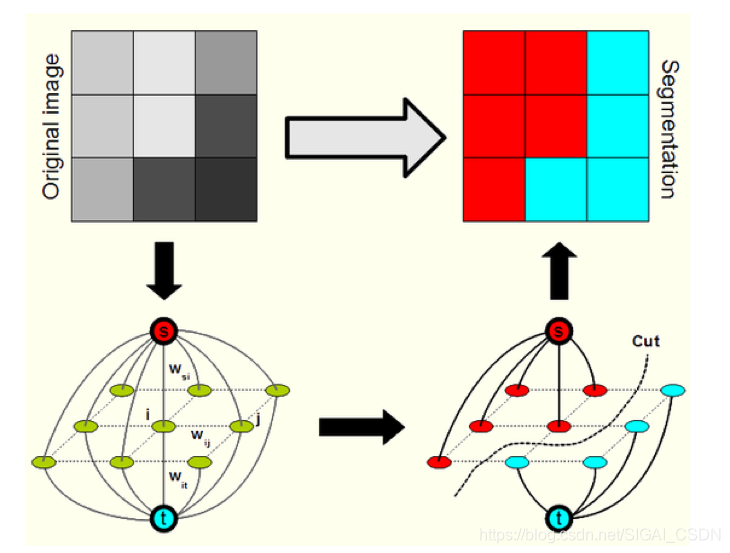
-
GrabCut[5]
Graph Cuts 演算法利用了影象的畫素灰度資訊和區域邊界資訊,代價函式構建在全域性最優的框架下,保證了分割效果。但Graph Cuts 是NP 難問題,且分割結果更傾向於具有相同的類內相似度。Rother 等人提出了基於迭代的圖割方法,稱為Grab Cut 演算法。該演算法使用高斯混合模型對目標和背景建模,利用了影象的RGB 色彩資訊和邊界資訊,通過少量的使用者互動操作得到非常好的分割效果。

基於聚類的分割方法
機器學習中的聚類方法也可以用於解決影象分割問題,其一般步驟是:
-
初始化一個粗糙的聚類
-
使用迭代的方式將顏色、亮度、紋理等特徵相似的畫素點聚類到同一超畫素,迭代直至收斂,從而得到最終的影象分割結果。

基於畫素聚類的代表方法有K-means(K均值),譜聚類,Meanshift和SLIC等。
-
K-means
K-means演算法是輸入聚類個數k,以及包含 n個資料物件的資料庫,輸出滿足方差最小標準k個聚類的一種演算法。K-means 演算法接受輸入量 k,然後將N個資料物件劃分為 k個聚類以便使得所獲得的聚類滿足:同一聚類中的物件相似度較高;而不同聚類中的物件相似度較小。
演算法過程如下: (1)從N個數據文件(樣本)隨機選取K個數據文件作為質心(聚類中心)。
本文在聚類中心初始化實現過程中採取在樣本空間範圍內隨機生成K個聚類中心。
(2)對每個資料文件測量其到每個質心的距離,並把它歸到最近的質心的類。
(3)重新計算已經得到的各個類的質心。
(4)迭代(2)~(3)步直至新的質心與原質心相等或小於指定閾值,演算法結束。
-
譜聚類
譜聚類(Spectral Clustering, SC)是一種基於圖論的聚類方法——將帶權無向圖劃分為兩個或兩個以上的最優子圖,使子圖內部儘量相似,而子圖間距離儘量距離較遠,以達到常見的聚類的目的。與 K-means 演算法相比不容易陷入區域性最優解,能夠對高維度、非常規分佈的資料進行聚類。與傳統的聚類演算法相比具有明顯的優勢,該演算法能在任意形狀的樣本空間上執行並且收斂於全域性最優,這個特點使得它對資料的適應性非常廣泛。為了進行聚類,需要利用高斯核計算任意兩點間的相似度以此構成相似度矩陣。
譜聚類方法缺點:
a)譜聚類對引數非常敏感;
b)時間複雜度和空間複雜度大。
對於 k-way 譜聚類演算法,一般分為以下步驟:
(1) 構建相似度矩陣 W;
(2) 根據相似度矩陣 W 構建拉普拉斯矩陣 L(不同的演算法有不同的 L 矩陣);
(3) 對 L 進行特徵分解,選取特徵向量組成特徵空間;
(4) 在特徵空間中利用 K 均值演算法,輸出聚類結果;
-
Meanshift[6]
Meanshift 演算法的原理是在d 維空間中,任選一點作為圓心,以h為半徑做圓.圓心和圓內的每個點都構成一個向量。將這些向量進行向量加法操作,得到的結果就是Meanshift 向量。繼續以Meanshift 向量的終點為圓心做圓,得到下一個Meanshift 向量.通過有限次迭代計算,Meanshift 演算法一定可以收斂到圖中概率密度最大的位置,即資料分佈的穩定點,稱為模點。利用Meanshift做影象分割,就是把具有相同模點的畫素聚類到同一區域的過程,其形式化定義為:

其中, 表示待聚類的樣本點,
代表點的當前位置,
代表點的下一個位置,h表示頻寬。Meanshift 演算法的穩定性、魯棒性較好,有著廣泛的應用。但是分割時所包含的語義資訊較少,分割效果不夠理想,無法有效地控制超畫素的數量,且執行速度較慢,不適用於實時處理任務。
-
SLIC[7]
SLIC(simple linear iterativeclustering),是Achanta 等人2010年提出的一種思想簡單、實現方便的演算法,將彩色影象轉化為CIELAB顏色空間和XY座標下的5維特徵向量,然後對5維特徵向量構造距離度量標準,對影象畫素進行區域性聚類的過程。SLIC演算法能生成緊湊、近似均勻的超畫素,在運算速度,物體輪廓保持、超畫素形狀方面具有較高的綜合評價,比較符合人們期望的分割效果。

SLIC 演算法的實質是將K-means 演算法用於超畫素聚類,眾所周知,K-means 演算法的時間複雜度為O(NKI),其中, N 是影象的畫素數,K 是聚類數, I 是迭代次數.
SLIC具體實現的步驟:
(1)將影象轉換為CIE Lab顏色空間
(2)初始化k個種子點(聚類中心),在影象上平均撒落k個點,k個點均勻的佔滿整幅影象。
(3)對種子點在內的n*n(一般為3*3)區域計算每個畫素點梯度值,選擇值最小(最平滑)的點作為新的種子點,這一步主要是為了防止種子點落在了輪廓邊界上。
(4)對種子點周圍 2S*2S的方形區域內的所有畫素點計算距離度量(計算方法在後文),對於K-means演算法是計算整張圖的所有畫素點,而SLIC得計算範圍是2S*2S,所以SLIC演算法收斂速度很快。其中S = sqrt(N/k),N是影象畫素個數。
(5)每個畫素點都可能被幾個種子點計算距離度量,選擇其中最小的距離度量對應的種子點作為其聚類中心。

基於語義的分割方法
聚類方法可以將影象分割成大小均勻、緊湊度合適的超畫素塊,為後續的處理任務提供基礎,但在實際場景的圖片中,一些物體的結構比較複雜,內部差異性較大,僅利用畫素點的顏色、亮度、紋理等較低層次的內容資訊不足以生成好的分割效果,容易產生錯誤的分割。因此需要更多地結合影象提供的中高層內容資訊輔助影象分割,稱為影象語義分割。
深度學習技術出現以後,在影象分類任務取得了很大的成功,尤其是其對高階語義資訊的model能力很大程度上解決了傳統影象分割方法中語義資訊缺失的問題。
2013年,LeCun的學生Farabet等人使用有監督的方法訓練了一個多尺度的深度卷積分類網路[9]。該網路以某個分類的畫素為中心進行多尺度取樣,將多尺度的區域性影象patch送到CNN分類器中逐一進行分類,最終得到每個畫素所屬的語義類別。在實際操作中,作者首先對圖片進行了超畫素聚類,進而對每個超畫素進行分類得到最後的分割結果,一定程度上提高了分割的速度。這種做法雖然取得了不錯的效果,但是由於逐畫素的進行視窗取樣得到的始終是區域性資訊,整體的語義還是不夠豐富,於是就有了後面一系列的改進方案,本文中選擇了幾種代表性的網路進行逐一分析。

-
FCN(Fully Convolutional Networks for Semantic Segmentation)[10]
Long 等人於2014 年提出了FCN方法,這是深度學習在影象分割領域的開山之作,作者針對影象分割問題設計了一種針對任意大小的輸入影象,訓練端到端的全卷積網路的框架,實現逐畫素分類,奠定了使用深度網路解決影象語義分割問題的基礎框架。為了克服卷積網路最後輸出層缺少空間位置資訊這一不足,通過雙線性插值上取樣和組合中間層輸出的特徵圖,將粗糙(coarse)分割結果轉換為密集(dense)分割結果。FCN由於採用的下采樣技術會丟失很多細節資訊,後續的一系列方法也都做了相應的改進策略。

-
DeepLab系列
DeepLab-v1 [11]在FCN 框架的末端增加可fully connected CRFs,使得分割更精確。DeepLab 模型,首先使用雙線性插值法對FCN的輸出結果上取樣得到粗糙分割結果,以該結果圖中每個畫素為一個節點構造CRF 模型 (DenseCRF)提高模型捕獲細節的能力。該系列的網路中採用了Dilated/Atrous Convolution的方式擴充套件感受野,獲取更多的上下文資訊,避免了DCNN中重複最大池化和下采樣帶來的解析度下降問題,解析度的下降會丟失細節。
DeepLab-v2 [12]提出了一個類似的結構,在給定的輸入上以不同取樣率的空洞卷積並行取樣,相當於以多個比例捕捉影象的上下文,稱為ASPP(atrous spatial pyramid pooling)模組,同時採用了深度殘差網路替換掉了VGG16增加了模型的擬合能力。DeepLab-v3 [13]重點探討了空洞卷積的使用,同時改進了ASPP模組,便於更好的捕捉多尺度上下文,在實際應用中獲得了非常好的效果。

使用不同取樣率的空洞卷積並行取樣
-
PSPNet(Pyramid Scene Parsing Network)[14]
作者提出的金字塔池化模組( pyramid pooling module)能夠聚合不同區域的上下文資訊,從而提高獲取全域性資訊的能力,通過金字塔結構將多尺度的資訊,將全域性特徵和區域性特徵嵌入基於FCN預測框架中,針對上下文複雜的場景和小目標的做了提升。為了提高收斂的速度,作者在主幹網路中增加了額外的監督損失函式。

-
U-Net [15]
U-Net由菲茲保大學的Olaf Ronneberger等人在2015年提出,相較於FCN多尺度資訊更加豐富,最初是用在醫療影象分割上。在生物影象分割中,最為突出了兩個挑戰是:可獲得的訓練資料很少;對於同一類的連線的目標分割。作者解決第一個問題的方法是通過資料擴大(data augmentation)。他們通過使用在粗糙的3*3點陣上的隨機取代向量來生成平緩的變形。解決第二個問題是通過使用加權損失(weighted loss),這是基於相鄰細胞的分界的背景標籤在損耗函式中有很高的權值。

編碼部分,每經過一個池化層就構造一個新的尺度,包括原圖尺度一共有5個尺度。解碼部分,每上取樣一次,就和特徵提取部分對應的通道數相同尺度融合。這樣就獲得了更豐富的上下文資訊,在Decode的過程中通過多尺度的融合豐富了細節資訊,提高分割的精度。
-
SegNet [16]
SegNet和FCN思路十分相似,只是Encoder中Pooling和Decoder的Upsampling使用的技術不一致。此外SegNet的編碼器部分使用的是VGG16的前13層卷積網路,每個編碼器層都對應一個解碼器層。

在SegNet中的pooling與FCN的Pooling相比多了一個記錄位置index的功能,也就是每次pooling,都會儲存通過max op選出的權值在filter中的相對位置,Unpooling就是Pooling的逆過程,Unpooling使得圖片變大2倍。max-pooling之後,每個filter會丟失的權重是無法復原的,但是在Unpooling層中可以得到在pooling中相對pooling filter的位置,所以Unpooling中先對輸入的特徵圖放大兩倍,然後把輸入特徵圖的資料根據pooling indices放入,總體計算效率也比FCN略高。

隨著深度學習在計算機視覺領域的巨大成功,以卷積神經網路為基礎的影象語義分割方法取得了突破性的進展,將影象分割帶到了一個新的高度。筆者認為如何繼續提高分割演算法的精度,以及降低分割演算法的複雜度是值得繼續研究的問題。
[1] Greig DM, Porteour BT, Seheult AH. Exact maximum a posteriori estimation for binary images. Journal of the Royal Statistical Society, 1989,51(2):271−279.
[2] J. Shi and J. Malik, Normalized Cuts and Image Segmentation, IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 22, no. 8, pp. 888-905, Aug. 2000.
[3] Y. B. Yuri, G. F. Lea, “Graph Cuts and Efficient N-D Image Segmentation,” International Journal of Computer Vision,vol.70,no.2,pp.109-131,2006.
[4] Y. Boykov and V. Kolmogorov. Computing geodesics and minimal surfaces via graph cuts. In International Conference on Computer Vision, volume I, pages 26–33, 2003.
[5] Rother C, Kolmogorov V, Blake A. GrabCut: Interactive foreground extraction using iterated graph cuts. ACM Trans. on Graphics, 2004,23(3):309−314. [doi:10.1145/1186562.1015720]
[6] Comaniciu D, Meer P. Mean Shift: A robust approach toward feature space analysis. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2002,24(5):603−619. [doi: 10.1109/34.1000236]
[7] Achanta R, Shaji A, Smith K, Lucchi A, Fua P, Susstrunk S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2012,34(11):2274−2282. [doi: 10.1109/tpami.2012.120]
[8] 姜楓,顧慶,郝慧珍,李娜,郭延文,陳道蓄.基於內容的影象分割方法綜述.軟體學報,2017,28(1):160−183. http://www.jos.org.cn/1000-9825/5136.htm
[9] Farabet, C., Couprie, C., Najman, L., and LeCun, Y. (2013). Learning hierarchical features for scene labeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1915–1929.
[10] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proc. of the 28th IEEE Conf. on CVPR. Washington: IEEE Computer Society, 2015. 1337−1342. [doi: 10.1109/cvpr.2015.7298965]
[11] Krähenbühl P, Koltun V. Efficient inference in fully connected CRFS with gaussian edge potentials. In: Proc. of the Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2012. 109−117. http://papers.nips.cc/paper/4296-efficientinference-in-fully-connected-crfs-with-gaussian-edge-potentials
[12] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv preprint arXiv:1606.00915, 2016.
[13] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017. 5, 8, 11
[14] Zhao, Hengshuang, Shi, Jianping, Qi, Xiaojuan, Wang, Xiaogang, and Jia, Jiaya. Pyramid scene parsing network. arXiv preprint arXiv:1612.01105, 2016.
[15] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in MICCAI, 2015.
[16] Kendall, Alex, Vijay Badrinarayanan, and Roberto Cipolla. "Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding." arXiv preprint arXiv:1511.02680 (2015).