
使用 libevent 和 libev 提高網路應用效能——I/O模型演進變化史
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
構建現代的伺服器應用程式需要以某種方法同時接收數百、數千甚至數萬個事件,無論它們是內部請求還是網路連線,都要有效地處理它們的操作。
有許多解決方案,但事件驅動也被廣泛應用到網路程式設計中。並大規模部署在高連線數高吞吐量的伺服器程式中,如 http 伺服器程式、ftp 伺服器程式等。相比於傳統的網路程式設計方式,事件驅動能夠極大的降低資源佔用,增大服務接待能力,並提高網路傳輸效率。
這些事件驅動模型中, libevent 庫和 libev庫能夠大大提高效能和事件處理能力。在本文中,我們要討論在 UNIX/Linux 應用程式中使用和部署這些解決方案所用的基本結構和方法。libev 和 libevent 都可以在高效能應用程式中使用。
在討論libev 和 libevent之前,我們看看I/O模型演進變化歷史
1、阻塞網路介面:處理單個客戶端
我們 第一次接觸到的網路程式設計一般都是從阻塞I/O模型圖:在呼叫recv()函式時,發生在核心中等待資料和複製資料的過程。
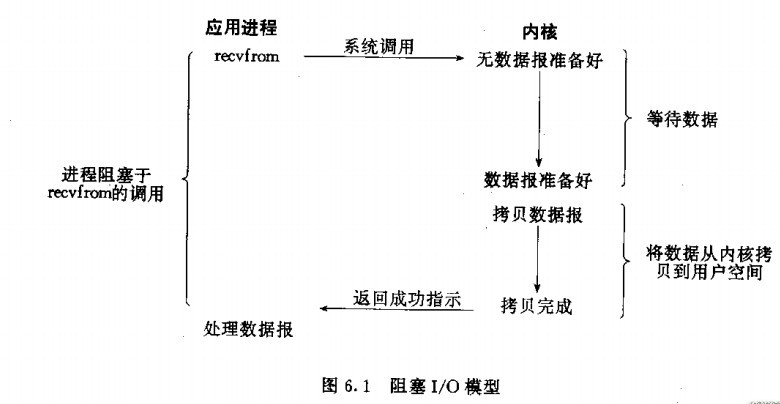
當呼叫recv()函式時,系統首先查是否有準備好的資料。如果資料沒有準備好,那麼系統就處於等待狀態。當資料準備好後,將資料從系統緩衝區複製到使用者空間,然後該函式返回。在套接應用程式中,當呼叫recv()函式時,未必使用者空間就已經存在資料,那麼此時recv()函式就會處於等待狀態。
我們注意到,大部分的 socket 介面都是阻塞型的。所謂阻塞型介面是指系統呼叫(一般是 IO 介面)不返回呼叫結果並讓當前執行緒一直阻塞,只有當該系統呼叫獲得結果或者超時出錯時才返回。
實際上,除非特別指定,幾乎所有的 IO 介面 ( 包括 socket 介面 ) 都是阻塞型的。這給網路程式設計帶來了一個很大的問題,如在呼叫 send() 的同時,執行緒將被阻塞,在此期間,執行緒將無法執行任何運算或響應任何的網路請求。這給多客戶機、多業務邏輯的網路程式設計帶來了挑戰。這時,很多程式設計師可能會選擇多執行緒的方式來解決這個問題。
使用阻塞模式的套接字,開發網路程式比較簡單,容易實現。當希望能夠立即傳送和接收資料,且處理的套接字數量比較少的情況下,即一個一個處理客戶端,伺服器沒什麼壓力,使用阻塞模式來開發網路程式比較合適。
阻塞模式給網路程式設計帶來了一個很大的問題,如在呼叫 send()的同時,執行緒將被阻塞,在此期間,執行緒將無法執行任何運算或響應任何的網路請求。如果很多客戶端同時訪問伺服器,伺服器就不能同時處理這些請求。這時,我們可能會選擇多執行緒的方式來解決這個問題。
2、多執行緒/程序處理多個客戶端
應對多客戶機的網路應用,最簡單的解決方式是在伺服器端使用多執行緒(或多程序)。多執行緒(或多程序)的目的是讓每個連線都擁有獨立的執行緒(或程序),這樣任何一個連線的阻塞都不會影響其他的連線。
具體使用多程序還是多執行緒,並沒有一個特定的模式。傳統意義上,程序的開銷要遠遠大於執行緒,所以,如果需要同時為較多的客戶機提供服務,則不推薦使用多程序;如果單個服務執行體需要消耗較多的 CPU 資源,譬如需要進行大規模或長時間的資料運算或檔案訪問,則程序較為安全。通常,使用 pthread_create () 建立新執行緒,fork() 建立新程序。即:
(1) a new Connection 進來,用 fork() 產生一個 Process 處理。
(2) a new Connection 進來,用 pthread_create() 產生一個 Thread 處理。
多執行緒/程序伺服器同時為多個客戶機提供應答服務。模型如下:
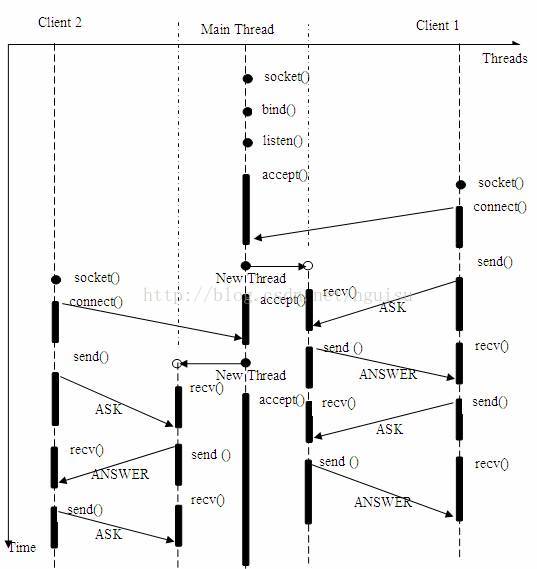
主執行緒持續等待客戶端的連線請求,如果有連線,則建立新執行緒,並在新執行緒中提供為前例同樣的問答服務。
#include <stdio.h>#include <stdlib.h>#include <string.h> #include <unistd.h>#include <sys/socket.h>#include <netinet/in.h>#include <arpa/inet.h> void do_service(int conn);void err_log(string err, int sockfd) { perror("binding"); close(sockfd); exit(-1);} int main(int argc, char *argv[]){ unsigned short port = 8000; int sockfd; sockfd = socket(AF_INET, SOCK_STREAM, 0);// 建立通訊端點:套接字 if(sockfd < 0) { perror("socket"); exit(-1); } struct sockaddr_in my_addr; bzero(&my_addr, sizeof(my_addr)); my_addr.sin_family = AF_INET; my_addr.sin_port = htons(port); my_addr.sin_addr.s_addr = htonl(INADDR_ANY); int err_log = bind(sockfd, (struct sockaddr*)&my_addr, sizeof(my_addr)); if( err_log != 0) err_log("binding"); err_log = listen(sockfd, 10); if(err_log != 0) err_log("listen"); struct sockaddr_in peeraddr; //傳出引數 socklen_t peerlen = sizeof(peeraddr); //傳入傳出引數,必須有初始值 int conn; // 已連線套接字(變為主動套接字,即可以主動connect) pid_t pid; while (1) { if ((conn = accept(sockfd, (struct sockaddr *)&peeraddr, &peerlen)) < 0) //3次握手完成的序列 err_log("accept error"); printf("recv connect ip=%s port=%d/n", inet_ntoa(peeraddr.sin_addr),ntohs(peeraddr.sin_port)); pid = fork(); if (pid == -1) err_log("fork error"); if (pid == 0) {// 子程序 close(listenfd); do_service(conn); exit(EXIT_SUCCESS); } else close(conn); //父程序 } return 0;} void do_service(int conn) { char recvbuf[1024]; while (1) { memset(recvbuf, 0, sizeof(recvbuf)); int ret = read(conn, recvbuf, sizeof(recvbuf)); if (ret == 0) { //客戶端關閉了 printf("client close/n"); break; } else if (ret == -1) ERR_EXIT("read error"); fputs(recvbuf, stdout); write(conn, recvbuf, ret); }}很多初學者可能不明白為何一個 socket 可以 accept 多次。實際上,socket 的設計者可能特意為多客戶機的情況留下了伏筆,讓 accept() 能夠返回一個新的 socket。下面是 accept 介面的原型:
int accept(int s, struct sockaddr *addr, socklen_t *addrlen);輸入引數 s 是從 socket(),bind() 和 listen() 中沿用下來的 socket 控制代碼值。執行完 bind() 和 listen() 後,作業系統已經開始在指定的埠處監聽所有的連線請求,如果有請求,則將該連線請求加入請求佇列。呼叫 accept() 介面正是從 socket s 的請求佇列抽取第一個連線資訊,建立一個與 s 同類的新的 socket 返回控制代碼。新的 socket 控制代碼即是後續 read() 和 recv() 的輸入引數。如果請求隊列當前沒有請求,則 accept() 將進入阻塞狀態直到有請求進入佇列。
上述多執行緒的伺服器模型似乎完美的解決了為多個客戶機提供問答服務的要求,但其實並不盡然。如果要同時響應成百上千路的連線請求,則無論多執行緒還是多程序都會嚴重佔據系統資源,降低系統對外界響應效率,而執行緒與程序本身也更容易進入假死狀態。
因此其缺點:
1)用 fork() 的問題在於每一個 Connection 進來時的成本太高,如果同時接入的併發連線數太多容易程序數量很多,程序之間的切換開銷會很大,同時對於老的核心(Linux)會產生雪崩效應。
2)用 Multi-thread 的問題在於 Thread-safe 與 Deadlock 問題難以解決,另外有 Memory-leak 的問題要處理,這個問題對於很多程式設計師來說無異於惡夢,尤其是對於連續伺服器的伺服器程式更是不可以接受。 如果才用 Event-based 的方式在於實做上不好寫,尤其是要注意到事件產生時必須 Nonblocking,於是會需要實做 Buffering 的問題,而 Multi-thread 所會遇到的 Memory-leak 問題在這邊會更嚴重。而在多 CPU 的系統上沒有辦法使用到所有的 CPU resource。
由此可能會考慮使用“執行緒池”或“連線池”。“執行緒池”旨在減少建立和銷燬執行緒的頻率,其維持一定合理數量的執行緒,並讓空閒的執行緒重新承擔新的執行任務。“連線池”維持連線的快取池,儘量重用已有的連線、減少建立和關閉連線的頻率。這兩種技術都可以很好的降低系統開銷,都被廣泛應用很多大型系統,如apache,mysql資料庫等。
但是,“執行緒池”和“連線池”技術也只是在一定程度上緩解了頻繁呼叫 IO 介面帶來的資源佔用。而且,所謂“池”始終有其上限,當請求大大超過上限時,“池”構成的系統對外界的響應並不比沒有池的時候效果好多少。所以使用“池”必須考慮其面臨的響應規模,並根據響應規模調整“池”的大小。
對應上例中的所面臨的可能同時出現的上千甚至上萬次的客戶端請求,“執行緒池”或“連線池”或許可以緩解部分壓力,但是不能解決所有問題。因為多執行緒/程序導致過多的佔用記憶體或 CPU等系統資源。
3、非阻塞的伺服器模型
以上面臨的很多問題,一定程度是 IO 介面的阻塞特性導致的。多執行緒是一個解決方案,還一個方案就是使用非阻塞的介面。
非阻塞的介面相比於阻塞型介面的顯著差異在於,在被呼叫之後立即返回。使用如下的函式可以將某控制代碼 fd 設為非阻塞狀態。
我們可以使用 fcntl(fd, F_SETFL, flag | O_NONBLOCK); 將套接字標誌變成非阻塞:
fcntl( fd, F_SETFL, O_NONBLOCK );下面將給出只用一個執行緒,但能夠同時從多個連線中檢測資料是否送達,並且接受資料。
使用非阻塞的接收資料模型:
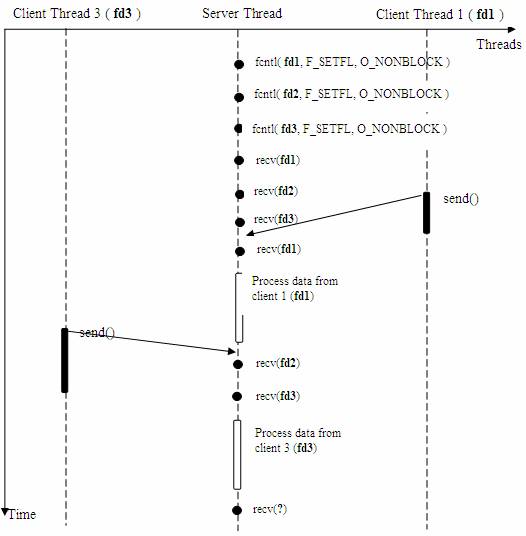
在非阻塞狀態下,recv() 介面在被呼叫後立即返回,返回值代表了不同的含義。
呼叫recv,如果裝置暫時沒有資料可讀就返回-1,同時置errno為EWOULDBLOCK(或者EAGAIN,這兩個巨集定義的值相同),表示本來應該阻塞在這裡(would block,虛擬語氣),事實上並沒有阻塞而是直接返回錯誤,呼叫者應該試著再讀一次(again)。這種行為方式稱為輪詢(Poll),呼叫者只是查詢一下,而不是阻塞在這裡死等
如在本例中,
- recv() 返回值大於 0,表示接受資料完畢,返回值即是接受到的位元組數;
- recv() 返回 0,表示連線已經正常斷開;
- recv() 返回 -1,且 errno 等於 EAGAIN,表示 recv 操作還沒執行完成;
- recv() 返回 -1,且 errno 不等於 EAGAIN,表示 recv 操作遇到系統錯誤 errno。
這樣可以同時監視多個裝置:
while(1){
非阻塞read(裝置1);
if(裝置1有資料到達)
處理資料;
非阻塞read(裝置2);
if(裝置2有資料到達)
處理資料;
..............................
}
如果read(裝置1)是阻塞的,那麼只要裝置1沒有資料到達就會一直阻塞在裝置1的read呼叫上,即使裝置2有資料到達也不能處理,使用非阻塞I/O就可以避免裝置2得不到及時處理。
類似一個快遞的例子:這裡使用忙輪詢的方法:每隔1微妙(while(1)幾乎不間斷)到A樓一層(核心緩衝區)去看快遞來了沒有。如果沒來,立即返回。而快遞來了,就放在A樓一層,等你去取。
非阻塞I/O有一個缺點,如果所有裝置都一直沒有資料到達,呼叫者需要反覆查詢做無用功,如果阻塞在那裡,作業系統可以排程別的程序執行,就不會做無用功了,在實際應用中非阻塞I/O模型比較少用。
可以看到伺服器執行緒可以通過迴圈呼叫 recv() 介面,可以在單個執行緒內實現對所有連線的資料接收工作。
但是上述模型絕不被推薦。因為,迴圈呼叫 recv() 將大幅度推高 CPU 佔用率;此外,在這個方案中,recv() 更多的是起到檢測“操作是否完成”的作用,實際作業系統提供了更為高效的檢測“操作是否完成“作用的介面,例如 select()。
4、IO複用事件驅動伺服器模型
簡介:主要是select和epoll;對一個IO埠,兩次呼叫,兩次返回,比阻塞IO並沒有什麼優越性;關鍵是能實現同時對多個IO埠進行監聽;
I/O複用模型會用到select、poll、epoll函式,這幾個函式也會使程序阻塞,但是和阻塞I/O所不同的的,這兩個函式可以同時阻塞多個I/O操作。而且可以同時對多個讀操作,多個寫操作的I/O函式進行檢測,直到有資料可讀或可寫時,才真正呼叫I/O操作函式。
我們先詳解select:
SELECT函式進行IO複用伺服器模型的原理是:當一個客戶端連線上伺服器時,伺服器就將其連線的fd加入fd_set集合,等到這個連線準備好讀或寫的時候,就通知程式進行IO操作,與客戶端進行資料通訊。
大部分 Unix/Linux 都支援 select 函式,該函式用於探測多個檔案控制代碼的狀態變化。
4.1 select 介面的原型:
FD_ZERO(int fd, fd_set* fds) FD_SET(int fd, fd_set* fds) FD_ISSET(int fd, fd_set* fds) FD_CLR(int fd, fd_set* fds) int select( int maxfdp, //Winsock中此引數無意義 fd_set* readfds, //進行可讀檢測的Socket fd_set* writefds, //進行可寫檢測的Socket fd_set* exceptfds, //進行異常檢測的Socket const struct timeval* timeout //非阻塞模式中設定最大等待時間)引數列表:
int maxfdp :是一個整數值,意思是“最大fd加1(max fd plus 1). 在三個描述符集(readfds, writefds, exceptfds)中找出最高描述符
編號值,然後加 1也可將maxfdp設定為 FD_SETSIZE,這是一個< sys/types.h >中的常數,它說明了最大的描述符數(經常是 256或1024) 。但是對大多數應用程式而言,此值太大了。確實,大多數應用程式只應用 3 ~ 1 0個描述符。如果將第三個參數設定為最高描述符編號值加 1,核心就只需在此範圍內尋找開啟的位,而不必在數百位的大範圍內搜尋。
fd_set *readfds: 是指向fd_set結構的指標,這個集合中應該包括檔案描述符,我們是要監視這些檔案描述符的讀變化的,即我們關
心是否可以從這些檔案中讀取資料了,如果這個集合中有一個檔案可讀,select就會返回一個大於0的值,表示有檔案可讀,如果沒有可讀的檔案,則根據timeout引數再判斷是否超時,若超出timeout的時間,select返回0,若發生錯誤返回負值。可以傳入NULL值,表示不關心任何檔案的讀變化。
fd_set *writefds: 是指向fd_set結構的指標,這個集合中應該包括檔案描述符,我們是要監視這些檔案描述符的寫變化的,即我們關
心是否可以向這些檔案中寫入資料了,如果這個集合中有一個檔案可寫,select就會返回一個大於0的值,表示有檔案可寫,如果沒有可寫的檔案,則根據timeout引數再判斷是否超時,若超出timeout的時間,select返回0,若發生錯誤返回負值。可以傳入NULL值,表示不關心任何檔案的寫變化。
fd_set *errorfds: 同上面兩個引數的意圖,用來監視檔案錯誤異常。
readfds , writefds,*errorfds每個描述符集存放在一個fd_set 資料型別中.如圖:
struct timeval* timeout :是select的超時時間,這個引數至關重要,它可以使select處於三種狀態:
第一,若將NULL以形參傳入,即不傳入時間結構,就是將select置於阻塞狀態,一定等到監視檔案描述符集合中某個檔案描述符發生變化為止;
第二,若將時間值設為0秒0毫秒,就變成一個純粹的非阻塞函式,不管檔案描述符是否有變化,都立刻返回繼續執行,檔案無變化返回0,有變化返回一個正值;
第三,timeout的值大於0,這就是等待的超時時間,即 select在timeout時間內阻塞,超時時間之內有事件到來就返回了,否則在超時後不管怎樣一定返回,返回值同上述。
4.2 使用select庫的步驟是
(1)建立所關注的事件的描述符集合(fd_set),對於一個描述符,可以關注其上面的讀(read)、寫(write)、異常(exception)事件,所以通常,要建立三個fd_set, 一個用來收集關注讀事件的描述符,一個用來收集關注寫事件的描述符,另外一個用來收集關注異常事件的描述符集合。 (2)呼叫select(),等待事件發生。這裡需要注意的一點是,select的阻塞與是否設定非阻塞I/O是沒有關係的。 (3)輪詢所有fd_set中的每一個fd ,檢查是否有相應的事件發生,如果有,就進行處理。/* 可讀、可寫、異常三種檔案描述符集的申明和初始化。*/ fd_set readfds, writefds, exceptionfds; FD_ZERO(&readfds); FD_ZERO(&writefds); FD_ZERO(&exceptionfds); int max_fd; /* socket配置和監聽。*/ sock = socket(...); bind(sock, ...); listen(sock, ...); /* 對socket描述符上發生關心的事件進行註冊。*/ FD_SET(&readfds, sock); max_fd = sock; while(1) { int i; fd_set r,w,e; /* 為了重複使用readfds 、writefds、exceptionfds,將它們拷貝到臨時變數內。*/ memcpy(&r, &readfds, sizeof(fd_set)); memcpy(&w, &writefds, sizeof(fd_set)); memcpy(&e, &exceptionfds, sizeof(fd_set)); /* 利用臨時變數呼叫select()阻塞等待,timeout=null表示等待時間為永遠等待直到發生事件。*/ select(max_fd + 1, &r, &w, &e, NULL); /* 測試是否有客戶端發起連線請求,如果有則接受並把新建的描述符加入監控。*/ if(FD_ISSET(&r, sock)){ new_sock = accept(sock, ...); FD_SET(&readfds, new_sock); FD_SET(&writefds, new_sock); max_fd = MAX(max_fd, new_sock); } /* 對其它描述符發生的事件進行適當處理。描述符依次遞增,最大值各系統有所不同(比如在作者系統上最大為1024), 在linux可以用命令ulimit -a檢視(用ulimit命令也對該值進行修改)。 在freebsd下,用sysctl -a | grep kern.maxfilesperproc來查詢和修改。*/ for(i= sock+1; i <max_fd+1; ++i) { if(FD_ISSET(&r, i)) doReadAction(i); if(FD_ISSET(&w, i)) doWriteAction(i); } }
4.3 和select模型緊密結合的四個巨集
FD_ZERO(int fd, fd_set* fds) //清除其所有位
FD_SET(int fd, fd_set* fds) //在某 fd_set 中標記一個fd的對應位為1
FD_ISSET(int fd, fd_set* fds) // 測試該集中的一個給定位是否仍舊設定
FD_CLR(int fd, fd_set* fds) //刪除對應位
這裡,fd_set 型別可以簡單的理解為按 bit 位標記控制代碼的佇列,例如要在某 fd_set 中標記一個值為 16 的控制代碼,則該 fd_set 的第 16 個 bit 位被標記為 1。具體的置位、驗證可使用 FD_SET、FD_ISSET 等巨集實現。

例如,編寫下列程式碼:
fd_setreadset,writeset;FD_ZERO(&readset);FD_ZERO(&writeset);FD_SET(0,&readset);FD_SET(3,&readset);FD_SET(1,&writeset);FD_SET(2,&writeset);select(4,&readset,&writeset,NULL,NULL);
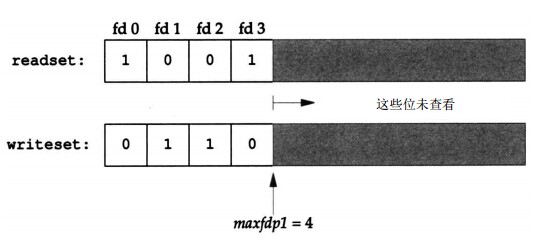
因為描述符編號從0開始,所以要在最大描述符編號值上加1。第一個引數實際上是要檢查的描述符數(從描述符0開始)。
4.4 select有三個可能的返回值
(1)返回值-1表示出錯。這是可能發生的,例如在所指定的描述符都沒有準備好時捕捉到一個訊號。(2)返回值0表示沒有描述符準備好。若指定的描述符都沒有準備好,而且指定的時間已經超過,則發生這種情況。
(3)返回一個正值說明了已經準備好的描述符數,在這種情況下,三個描述符集中仍舊開啟的位是對應於已準備好的描述符位。
4.5 使用select()的接收資料模型圖:
下面將重新模擬上例中從多個客戶端接收資料的模型。
使用select()的接收資料模型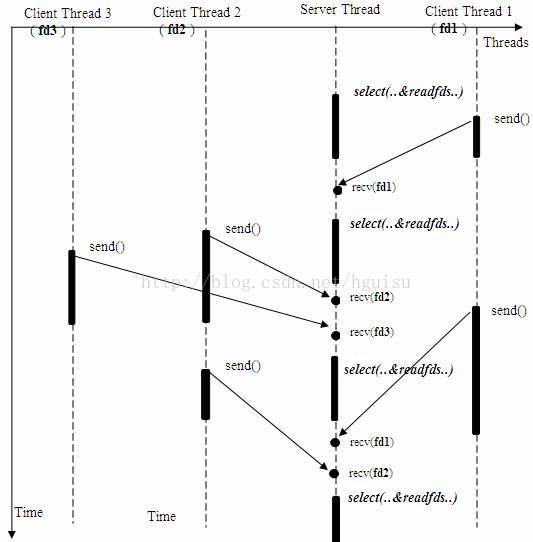
上述模型只是描述了使用 select() 介面同時從多個客戶端接收資料的過程;由於 select() 介面可以同時對多個控制代碼進行讀狀態、寫狀態和錯誤狀態的探測,所以可以很容易構建為多個客戶端提供獨立問答服務的伺服器系統。
使用select()介面的基於事件驅動的伺服器模型
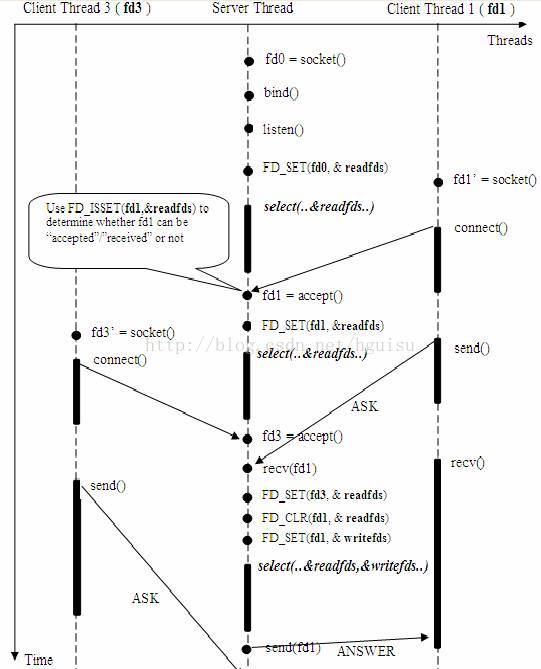
這裡需要指出的是,客戶端的一個 connect() 操作,將在伺服器端激發一個“可讀事件”,所以 select() 也能探測來自客戶端的 connect() 行為。
上述模型中,最關鍵的地方是如何動態維護 select() 的三個引數 readfds、writefds 和 exceptfds。作為輸入引數,readfds 應該標記所有的需要探測的“可讀事件”的控制代碼,其中永遠包括那個探測 connect() 的那個“母”控制代碼;同時,writefds 和 exceptfds 應該標記所有需要探測的“可寫事件”和“錯誤事件”的控制代碼 ( 使用 FD_SET() 標記 )。
作為輸出引數,readfds、writefds 和 exceptfds 中的儲存了 select() 捕捉到的所有事件的控制代碼值。程式設計師需要檢查的所有的標記位 ( 使用 FD_ISSET() 檢查 ),以確定到底哪些控制代碼發生了事件。
上述模型主要模擬的是“一問一答”的服務流程,所以,如果 select() 發現某控制代碼捕捉到了“可讀事件”,伺服器程式應及時做 recv() 操作,並根據接收到的資料準備好待發送資料,並將對應的控制代碼值加入 writefds,準備下一次的“可寫事件”的 select() 探測。同樣,如果 select() 發現某控制代碼捕捉到“可寫事件”,則程式應及時做 send() 操作,並準備好下一次的“可讀事件”探測準備。下圖描述的是上述模型中的一個執行週期。
一個執行週期
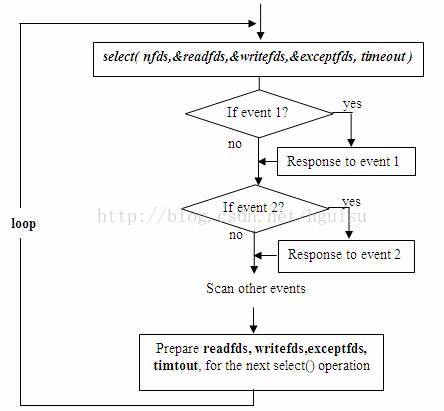
這種模型的特徵在於每一個執行週期都會探測一次或一組事件,一個特定的事件會觸發某個特定的響應。我們可以將這種模型歸類為“事件驅動模型”。
4.6 select的優缺點
相比其他模型,使用 select() 的事件驅動模型只用單執行緒(程序)執行,佔用資源少,不消耗太多 CPU,同時能夠為多客戶端提供服務。如果試圖建立一個簡單的事件驅動的伺服器程式,這個模型有一定的參考價值。但這個模型依舊有著很多問題。
select的缺點:
(1)單個程序能夠監視的檔案描述符的數量存在最大限制
(2)select需要複製大量的控制代碼資料結構,產生巨大的開銷
(3)select返回的是含有整個控制代碼的列表,應用程式需要消耗大量時間去輪詢各個控制代碼才能發現哪些控制代碼發生了事件
(4)select的觸發方式是水平觸發,應用程式如果沒有完成對一個已經就緒的檔案描述符進行IO操作,那麼之後每次select呼叫還是會將這些檔案描述符通知程序。相對應方式的是邊緣觸發。
(6) 該模型將事件探測和事件響應夾雜在一起,一旦事件響應的執行體龐大,則對整個模型是災難性的。如下例,龐大的執行體 1 的將直接導致響應事件 2 的執行體遲遲得不到執行,並在很大程度上降低了事件探測的及時性。
龐大的執行體對使用select()的事件驅動模型的影響
很多作業系統提供了更為高效的介面,如 linux 提供了 epoll,BSD 提供了 kqueue,Solaris 提供了 /dev/poll …。如果需要實現更高效的伺服器程式,類似 epoll 這樣的介面更被推薦。
4.7 poll事件模型
poll庫是在linux2.1.23中引入的,windows平臺不支援poll. poll與select的基本方式相同,都是先建立一個關注事件的描述符的集合,然後再去等待這些事件發生,然後再輪詢描述符集合,檢查有沒有事件發生,如果有,就進行處理。因此,poll有著與select相似的處理流程: (1)建立描述符集合,設定關注的事件 (2)呼叫poll(),等待事件發生。下面是poll的原型: int poll(struct pollfd * fds, nfds_t nfds, int timeout); 類似select,poll也可以設定等待時間,效果與select一樣。 (3)輪詢描述符集合,檢查事件,處理事件。 在這裡要說明的是,poll與select的主要區別在與,select需要為讀、寫、異常事件分別建立一個描述符集合,最後 輪詢的時候,需要分別輪詢這三個集合。而poll只需要一個集合,在每個描述符對應的結構上分別設定讀、寫、異常事件,最後 輪詢的時候,可以同時檢查三種事件。4.7 epoll事件模型
epoll是和上面的poll和select不同的一個事件驅動庫,它是在linux 2.5.44中引入的,它屬於poll的一個變種。 poll和select庫,它們的最大的問題就在於效率。它們的處理方式都是建立一個事件列表,然後把這個列表發給 核心,返回的時候,再去 輪詢檢查這個列表,這樣在描述符比較多的應用中,效率就顯得比較低下了。 epoll是一種比較好的做法,它把描述符列表交給 核心,一旦有事件發生,核心把發生事件的描述符列表通知給程序,這樣就避免了 輪詢整個描述符列表。下面對epoll的使用進行說明: (1).建立一個epoll描述符,呼叫epoll_create()來完成,epoll_create()有一個整型的引數size,用來告訴 核心,要建立一個有size個描述符的事件列表(集合) int epoll_create(int size) (2).給描述符設定所關注的事件,並把它新增到核心的事件列表中去,這裡需要呼叫epoll_ctl()來完成。 int epoll_ctl(int epfd, int op, int fd, struct epoll_event * event) 這裡op引數有三種,分別代表三種操作: a. EPOLL_CTL_ADD, 把要關注的描述符和對其關注的事件的結構,新增到核心的事件列表中去 b. EPOLL_CTL_DEL,把先前新增的描述符和對其關注的事件的結構,從 核心的事件列表中去除 c. EPOLL_CTL_MOD,修改先前新增到 核心的事件列表中的描述符的關注的事件 (3). 等待 核心通知事件發生,得到發生事件的描述符的結構列表,該過程由epoll_wait()完成。得到事件列表後,就可以進行事件處理了。 int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout) 在使用epoll的時候,有一個需要特別注意的地方,那就是epoll觸發事件的檔案有兩種方式: (1)Edge Triggered(ET),在這種情況下,事件是由資料到達邊界觸發的。所以要在處理讀、寫的時候,要不斷的呼叫read/write,直到它們返回EAGAIN,然後再去epoll_wait(),等待下次事件的發生。這種方式適用要遵從下面的原則: a. 使用非阻塞的I/O;b.直到read/write返回EAGAIN時,才去等待下一次事件的發生。 (2)Level Triggered(LT), 在這種情況下,epoll和poll類似,但處理速度上可能比poll快。在這種情況下,只要有資料沒有讀、寫完,呼叫epoll_wait()的時候,就會有事件被觸發。/* 新建並初始化檔案描述符集。*/ struct epoll_event ev; struct epoll_event events[MAX_EVENTS]; /* 建立epoll控制代碼。*/ int epfd = epoll_create(MAX_EVENTS); /* socket配置和監聽。*/ sock = socket(...); bind(sock, ...); listen(sock, ...); /* 對socket描述符上發生關心的事件進行註冊。*/ ev.events = EPOLLIN; ev.data.fd = sock; epoll_ctl(epfd, EPOLL_CTL_ADD, sock, &ev); while(1) { int i; /*呼叫epoll_wait()阻塞等待,等待時間為永遠等待直到發生事件。*/ int n = epoll_wait(epfd, events, MAX_EVENTS, -1); for(i=0; i <n; ++i) { /* 測試是否有客戶端發起連線請求,如果有則接受並把新建的描述符加入監控。*/ if(events.data.fd == sock) { if(events.events & POLLIN){ new_sock = accept(sock, ...); ev.events = EPOLLIN | POLLOUT; ev.data.fd = new_sock; epoll_ctl(epfd, EPOLL_CTL_ADD, new_sock, &ev); } }else{ /* 對其它描述符發生的事件進行適當處理。*/ if(events.events & POLLIN) doReadAction(i); if(events.events & POLLOUT) doWriteAction(i); } } } epoll支援水平觸發和邊緣觸發,理論上來說邊緣觸發效能更高,但是使用更加複雜,因為任何意外的丟失事件都會造成請求處理錯誤。Nginx就使用了epoll的邊緣觸發模型。
這裡提一下水平觸發和邊緣觸發就緒通知的區別:
這兩個詞來源於計算機硬體設計。它們的區別是隻要控制代碼滿足某種狀態,水平觸發就會發出通知;而只有當控制代碼狀態改變時,邊緣觸發才會發出通知。例如一個socket經過長時間等待後接收到一段100k的資料,兩種觸發方式都會向程式發出就緒通知。假設程式從這個socket中讀取了50k資料,並再次呼叫監聽函式,水平觸發依然會發出就緒通知,而邊緣觸發會因為socket“有資料可讀”這個狀態沒有發生變化而不發出通知且陷入長時間的等待。
因此在使用邊緣觸發的 api 時,要注意每次都要讀到 socket返回 EWOULDBLOCK為止
遺憾的是不同的作業系統特供的 epoll 介面有很大差異,所以使用類似於 epoll 的介面實現具有較好跨平臺能力的伺服器會比較困難。
幸運的是,有很多高效的事件驅動庫可以遮蔽上述的困難,常見的事件驅動庫有 libevent 庫,還有作為 libevent 替代者的 libev 庫。這些庫會根據作業系統的特點選擇最合適的事件探測介面,並且加入了訊號 (signal) 等技術以支援非同步響應,這使得這些庫成為構建事件驅動模型的不二選擇。下章將介紹如何使用 libev 庫替換 select 或 epoll 介面,實現高效穩定的伺服器模型。
5、libevent方法
libevent是一個事件觸發的網路庫,適用於windows、linux、bsd等多種平臺,內部使用select、epoll、kqueue等系統呼叫管理事件機制。著名分散式快取軟體memcached也是libevent based,而且libevent在使用上可以做到跨平臺,而且根據libevent官方網站上公佈的資料統計,似乎也有著非凡的效能。
libevent 庫實際上沒有更換 select()、poll() 或其他機制的基礎。而是使用對於每個平臺最高效的高效能解決方案在實現外加上一個包裝器。
為了實際處理每個請求,libevent 庫提供一種事件機制,它作為底層網路後端的包裝器。事件系統讓為連線新增處理函式變得非常簡便,同時降低了底層 I/O 複雜性。這是 libevent 系統的核心。
libevent 庫的其他元件提供其他功能,包括緩衝的事件系統(用於緩衝傳送到客戶端/從客戶端接收的資料)以及 HTTP、DNS 和 RPC 系統的核心實現。
1、libevent有下面一些特點和優勢:
1)事件驅動,高效能;
2)輕量級,專注於網路;
3) 跨平臺,支援 Windows、Linux、Mac Os等;
4) 支援多種 I/O多路複用技術, epoll、poll、dev/poll、select 和kqueue 等;
5) 支援 I/O,定時器和訊號等事件
2、libevent部分組成:
1)event 及 event_base事件管理包括各種IO(socket)、定時器、訊號等事件,也是libevent應用最廣的模組;
2 ) evbuffer event 及 event_base 快取管理是指evbuffer功能;提供了高效的讀寫方法
3) evdns DNS是libevent提供的一個非同步DNS查詢功能;
4) evhttp HTTP是libevent的一個輕量級http實現,包括伺服器和客戶端
libevent也支援ssl,這對於有安全需求的網路程式非常的重要,但是其支援不是很完善,比如http server的實現就不支援ssl。
3、事件處理框架
libevent是事件驅動的庫,所謂事件驅動,簡單地說就是你點什麼按鈕(即產生什麼事件),電腦執行什麼操作(即呼叫什麼函式)。
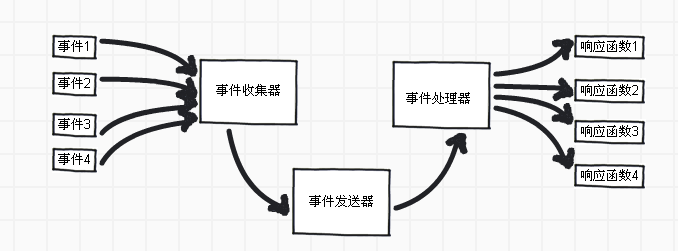
Libevent框架本質上是一個典型的Reactor模式,所以只需要弄懂Reactor模型,libevent就八九不離十了。
Reactor模式,是一種事件驅動機制。應用程式需要提供相應的介面並註冊到Reactor上,如果相應的事件發生,Reactor將主動呼叫應用程式註冊的介面,這些介面又稱為“回撥函式”。
在Libevent中也是一樣,向Libevent框架註冊相應的事件和回撥函式;當這些事件發生時,Libevent會呼叫這些回撥函式處理相應的事件(I/O讀寫、定時和訊號)。
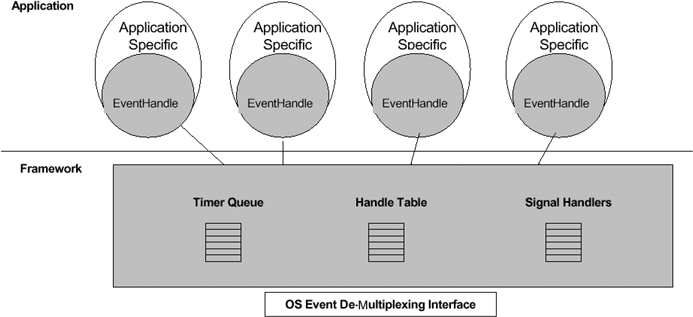
使用Reactor模型,必備的幾個元件:事件源、Reactor框架、多路複用機制和事件處理程式,先來看看Reactor模型的整體框架,接下來再對每個元件做逐一說明。
1) 事件源Linux 上是檔案描述符, Windows 上就是 Socket 或者 Handle 了,這裡統一稱為 “ 控制代碼集 ” ;程式在指定的控制代碼上註冊關心的事件,比如 I/O 事件。
1) 2) event demultiplexer——事件多路分發機制
由作業系統提供的I/O多路複用機制,比如select和epoll。程式首先將其關心的控制代碼(事件源)及其事件註冊到event demultiplexer上;當有事件到達時,event demultiplexer會發出通知“在已經註冊的控制代碼集中,一個或多個控制代碼的事件已經就緒”;程式收到通知後,就可以在非阻塞的情況下對事件進行處理了。
對應到libevent中,依然是select、poll、epoll等,但是libevent使用結構體eventop進行了封裝,以統一的介面來支援這些I/O多路複用機制,達到了對外隱藏底層系統機制的目的。
3) Reactor——反應器
Reactor,是事件管理的介面,內部使用event demultiplexer註冊、登出事件;並執行事件迴圈,當有事件進入“就緒”狀態時,呼叫註冊事件的回撥函式處理事件。
對應到libevent中,就是event_base結構體。
4) Event Handler——事件處理程式
事件處理程式提供了一組介面,每個介面對應了一種型別的事件,供Reactor在相應的事件發生時呼叫,執行相應的事件處理。通常它會繫結一個有效的控制代碼。
對應到libevent中,就是event結構體。
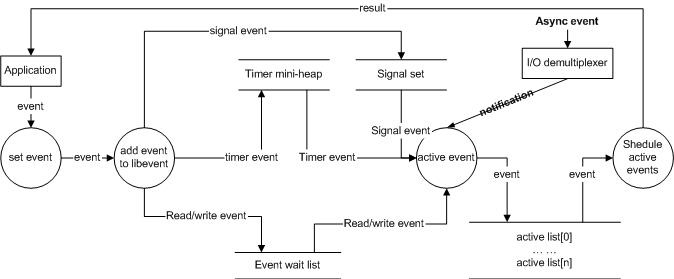
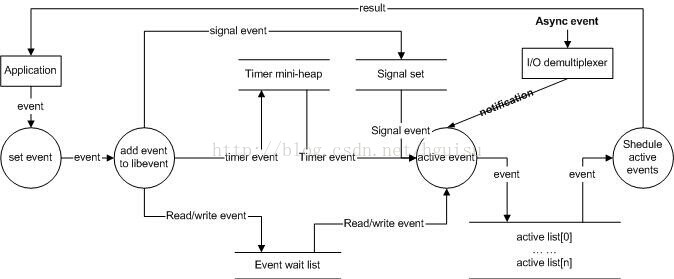
結合Reactor框架,我們來理一下libevent的事件處理流程,請看下圖:
event_init() 初始化:
首先要隆重介紹event_base物件:
struct event_base { const struct eventop *evsel; void *evbase; int event_count; /* counts number of total events */ int event_count_active; /* counts number of active events */ int event_gotterm; /* Set to terminate loop */ /* active event management */ struct event_list **activequeues; int nactivequeues; struct event_list eventqueue; struct timeval event_tv; RB_HEAD(event_tree, event) timetree;};event_base物件整合了事件處理的一些全域性變數, 角色是event物件的"總管家", 他包括了:
事件引擎函式物件(evsel, evbase),
當前入列事件列表(event_count, event_count_active, eventqueue),
全域性終止訊號(event_gotterm),
活躍事件列表(avtivequeues),
事件佇列樹(timetree)...
初始化時建立event_base物件, 選擇 當前OS支援的事件引擎(epoll, poll, select...)並初始化, 建立全域性訊號佇列(signalqueue), 活躍佇列的記憶體分配( 根據設定的priority個數,預設為1).
event_setevent_set來設定event物件,包括所有者event_base物件, fd, 事件(EV_READ| EV_WRITE|EV_PERSIST), 回掉函式和引數,事件優先順序是當前event_base的中間級別(current_base->nactivequeues/2)
設定監視事件後,事件處理函式可以只被呼叫一次或總被呼叫。
只調用一次:事件處理函式被呼叫後,即從事件佇列中刪除,需要在事件處理函式中再次加入事件,才能在下次事件發生時被呼叫;
總被呼叫:設定為EV_PERSIST,只加入一次,處理函式總被呼叫,除非採用event_remove顯式地刪除。
event_add() 事件新增:
int event_add(struct event *ev, struct timeval *tv)
這個介面有兩個引數, 第一個是要新增的事件, 第二個引數作為事件的超時值(timer). 如果該值非NULL, 在新增本事件的同時新增超時事件(EV_TIMEOUT)到時間佇列樹(timetree), 根據事件型別處理如下:
EV_READ => EVLIST_INSERTED => eventqueue
EV_WRITE => EVLIST_INSERTED => eventqueue
EV_TIMEOUT => EVLIST_TIMEOUT => timetree
EV_SIGNAL => EVLIST_SIGNAL => signalqueue
event_base_loop() 事件處理主迴圈
這裡是事件的主迴圈,只要flags不是設定為EVLOOP_NONBLOCK, 該函式就會一直迴圈監聽事件/處理事件.
每次迴圈過程中, 都會處理當前觸發(活躍)事件:
(a). 檢測當前是否有訊號處理(gotterm, gotsig), 這些都是全域性引數,不適合多執行緒
(b). 時間更新,找到離當前最近的時間事件, 得到相對超時事件tv
(c). 呼叫事件引擎的dispatch wait事件觸發, 超時值為tv, 觸發事件新增到activequeues
(d). 處理活躍事件, 呼叫caller的callbacks (event_process_acitve)
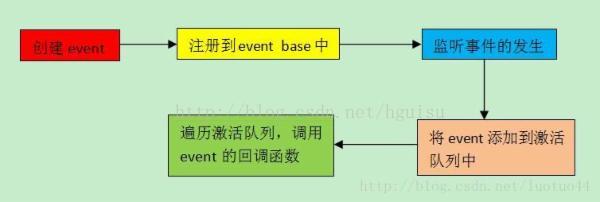
典型的libevent的應用大致整體流程:
建立 libevent 伺服器的基本方法是, 註冊當發生某一操作(比如接受來自客戶端的連線)時應該執行的函式,然後呼叫主事件迴圈event_dispatch()。執行過程的控制現在由 libevent 系統處理。註冊事件和將呼叫的函式之後,事件系統開始自治;在應用程式執行時,可以在事件佇列中新增(註冊)或刪除(取消註冊)事件。事件註冊非常方便,可以通過它新增新事件以處理新開啟的連線,從而構建靈活的網路處理系統
(環境設定)-> (建立event_base) -> (註冊event,將此event加入到event_base中) -> (設定event各種屬性,事件等) ->(將event加入事件列表 addevent) ->(開始事件監視迴圈、分發dispatch)。
例子:
例如,可以開啟一個監聽套接字,然後註冊一個回撥函式,每當需要呼叫 accept() 函式以開啟新連線時呼叫這個回撥函式,這樣就建立了一個網路伺服器。例1如下所示的程式碼片段說明基本過程:
例1:開啟監聽套接字,註冊一個回撥函式(每當需要呼叫 accept() 函式以開啟新連線時呼叫它),由此建立網路伺服器:
#
相關推薦
使用 libevent 和 libev 提高網路應用效能——I/O模型演進變化史
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
ibevent 和 libev 提高網路應用效能【轉】
轉自:https://www.cnblogs.com/kunhu/p/3632285.html
構建現代的伺服器應用程式需要以某種方法同時接收數百、數千甚至數萬個事件,無論它們是內部請求還是網路連線,都要有效地處理它們的操作。有許多解決方 案,但是 libevent 庫和 libev 庫能夠大大提高效能和事
使用Cache-Control和gzip提升tomcat應用效能(整理)
這個其實應該是常識,只不過以前做的J2EE應用大部分是內網裡跑的東西,所以效能上沒什麼問題。這次APIS由於有在外面用的可能,加上使用了一些比較大的javascript框架(Ext),所以效能問題瞬間竄了上來。以前做的J2EE應用沒有使用上達500K的框架,最多就是
技術進階:通過來JavaScript 效能調優提高 Web 應用效能
前言
現在的網際網路應用中,在Web 開發中經常會遇到效能的問題,尤其是針對當今的 Web2.0 +應用。JavaScript 是當今使用最為廣泛的 Web 開發語言,Web 應用的效能問題很大一部分都是由程式設計師寫的 JavaScript 指令碼效能不佳所造成的,裡面包括了 Java
幾種設計良好結構以提高.NET應用效能的方法
寫在前面
設計良好的系統,除了架構層面的優良設計外,剩下的大部分就在於如何設計良好的程式碼,.NET提供了很多的型別,這些型別非常靈活,也非常好用,比如List,Dictionary、HashSet、StringBuilder、string等等。在大多數情況下,大家都是看著業務需要直接去用,似乎並沒有什麼問
一種提高單片機i/o口驅動能力的方法
water clas aik eas 發現 strong img white .net
一、簡述問題
當你用單片驅動發光二極管的時,你還感覺不到P0、P1口的差別。(10-20mA之間,當中P0驅動能力最強,但對於驅動直流電機依舊非常弱。其結果就是電機不轉)。那麽
NIO網路程式設計 I/O 模型
前言
前面的文章講解了I/O 模型、緩衝區(Buffer)、通道(Channel)、選擇器(Selector),這些都是關於NIO的特點,偏於理論一些,這篇文章LZ將通過利用這些知識點來實現NIO的伺服器和客戶端,當然了,只是一個簡單的demo,但是對於NIO的學習來說,足夠了,麻雀雖小但五臟俱全。話不
嵌入式Linux網路程式設計,I/O多路複用,epoll()示例,epoll()客戶端,epoll()伺服器,單鏈表
文章目錄
1,I/O多路複用 epoll()示例
1.1,epoll()---net.h
1.2,epoll()---client.c
1.3,epoll()---sever.c
1.4,epoll()---linklist.h
嵌入式Linux網路程式設計,I/O多路複用,poll()示例,poll()客戶端,poll()伺服器,單鏈表
文章目錄
1,IO複用poll()示例
1.1,poll()---net.h
1.2,poll()---client.c
1.3,poll()---sever.c
1.4,poll()---linklist.h
1.5,p
嵌入式Linux網路程式設計,I/O多路複用,select()示例,select()客戶端,select()伺服器,單鏈表
文章目錄
1,IO複用select()示例
1.1 select()---net.h
1.2 select()---client.c
1.3 select()---sever.c
1.4 select()---linklist.h
嵌入式Linux網路程式設計,I/O多路複用,阻塞I/O模式,非阻塞I/O模式fcntl()/ioctl(),多路複用I/O select()/pselect()/poll(),訊號驅動I/O
文章目錄
1,I/O模型
2,阻塞I/O 模式
2.1,讀阻塞(以read函式為例)
2.2,寫阻塞
3,非阻塞模式I/O
3.1,非阻塞模式的實現(fcntl()函式、ioctl() 函式)
Java進階(五)Java I/O模型從BIO到NIO和Reactor模式
本文介紹了Java中的四種I/O模型,同步阻塞,同步非阻塞,多路複用,非同步阻塞。同時將NIO和BIO進行了對比,並詳細分析了基於NIO的Reactor模式,包括經典單執行緒模型以及多執行緒模式和多Reactor模式。
原創文章,轉載請務必將下面這段話置於文章開頭處(保留超連結)。 本文
Linux----網路程式設計(I/O複用之select系統呼叫)
io_select_ser.c
1. #include <string.h>
2. #include <assert.h>
3. #include <unistd.h>
4. #include <stdio.h>
5. #in
網路I/O模型--5種常見的網路I/O模型
阻塞與非阻塞
阻塞就是卡在那兒什麼也不做,雙方之間也沒有資訊溝通。
非阻塞就是即使對方不能馬上完成請求,雙方之間也有資訊的溝通。
同步與非同步
同步就是一件事件只由一個過程處理完成,不論阻塞與非阻塞,最後完成這個事情的都是同一個過程
非同步就是一件事由兩個過程完成,前
網路程式設計中I/O複用select的用法
網路程式設計select的用法
select使用流程圖
在網路程式設計中需要新增的程式碼行以及意義
例程
參考文獻及部落格
注:本文對select函式、相關引數及結構體不做解釋
select使用流程
IO的埠對映和記憶體對映 (Port mapped I/O 和 Memory mapped I/O說明)
IO埠和IO記憶體的區別及分別使用的函式介面
每個外設都是通過讀寫其暫存器來控制的。外設暫存器也稱為I/O埠,通常包括:控制暫存器、狀態暫存器和資料暫存器三大類。根據訪問外設暫存器的不同方式,可以把CPU分成兩大類。一類CPU(如M68K,Power
網路程式設計中阻塞與非阻塞、同步與非同步、I/O模型的理解
1. 概念理解
在進行網路程式設計時,我們常常見到同步(Sync)/非同步(Async),阻塞(Block)/非阻塞(Unblock)四種呼叫方式:同步:所謂同步,就是在發出一個功能呼叫時,在沒有得到結果之前,該呼叫就不返回。也就是必須一件一件事做,等前一件做完了才能做下一件事。
例如
Linux網路程式設計學習筆記(7)---5種I/O模型及select輪詢
本文主要介紹5種I/O模型,select函式以及利用select實現C/S模型。
1、5種I/O模型
(1)阻塞I/O:
一直等到資料到來,才會將資料從核心中拷貝到使用者空間中。
(2)非阻塞I/O:
每過一段時
I/O模型:同步I/O和非同步I/O,阻塞I/O和非阻塞I/O
同步(synchronous) IO和非同步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分別是什麼,到底有什麼區別?
這個問題其實不同的人給出的答案都可能不同,在大部分的博文中(包括WIKI在內),我們很可能
五種I/O模型和Java NIO原始碼分析
最近在學習Java網路程式設計和Netty相關的知識,瞭解到Netty是NIO模式的網路框架,但是提供了不同的Channel來支援不同模式的網路通訊處理,包括同步、非同步、阻塞和非阻塞。學習要從基礎開始,所以我們就要先了解一下相關的基礎概念和Java原生的NIO。這裡,就將最近我學習的知識總結一下,以供大