
開源|2017 CVPR(Oral Paper) 多目標實時體態估測 專案開源
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
本目錄下的程式碼贏得了2016年MSCOCO關鍵點挑戰賽以及2016年ECCV最佳演示獎,並發表在2017年CVPR的口頭論文(Oral Paper)中。
演示視訊:
在論文中,我們提出了一種自下而上的方法進行多人姿態估計,這種方法不需要任何行人檢測的演算法。
論文地址:https://arxiv.org/abs/1611.08050
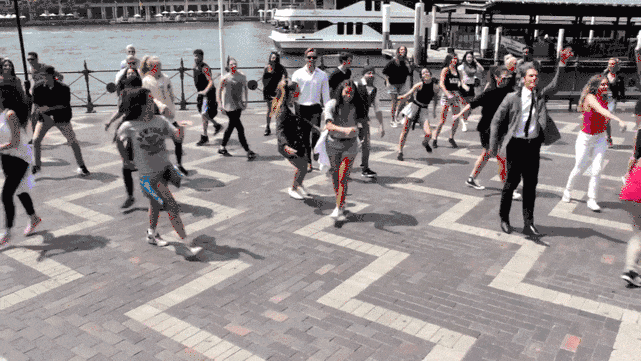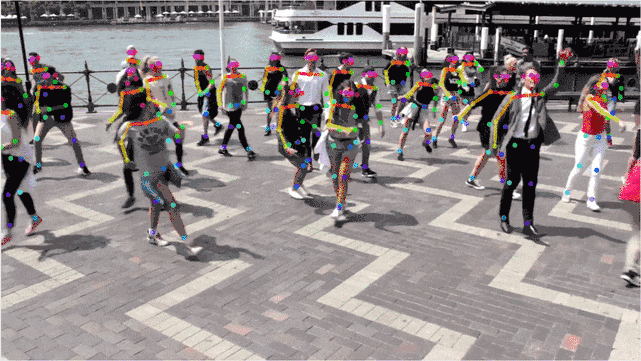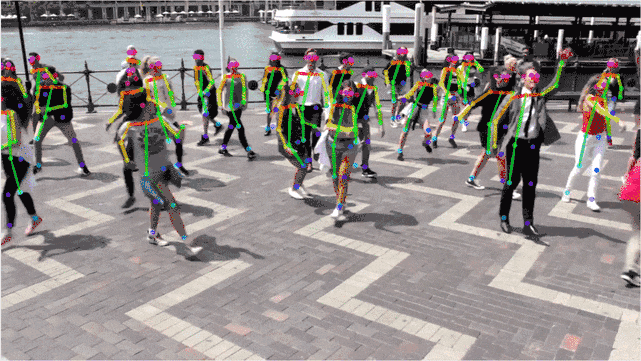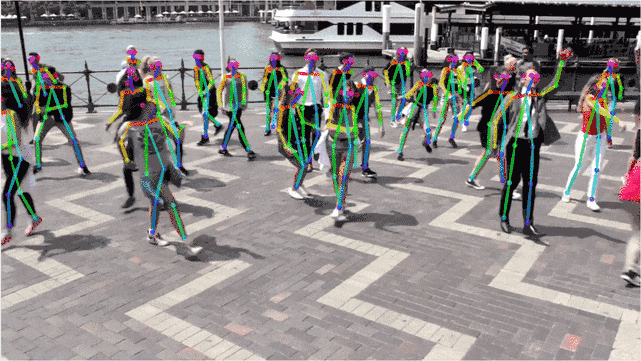
實驗結果
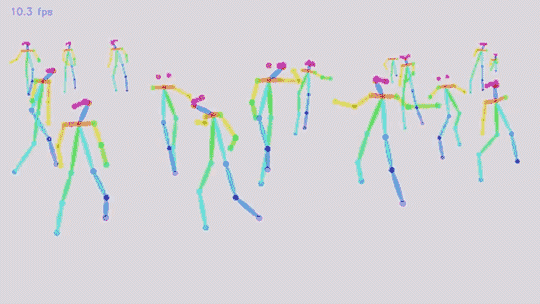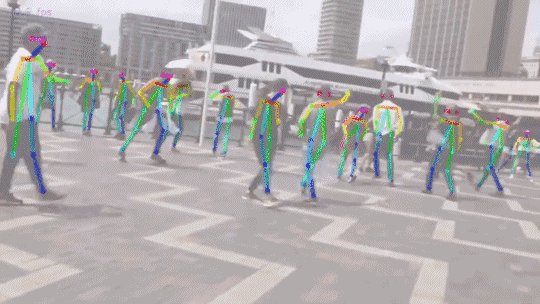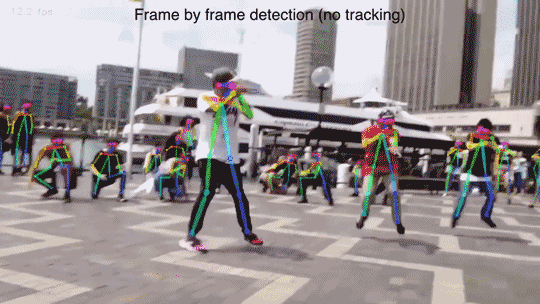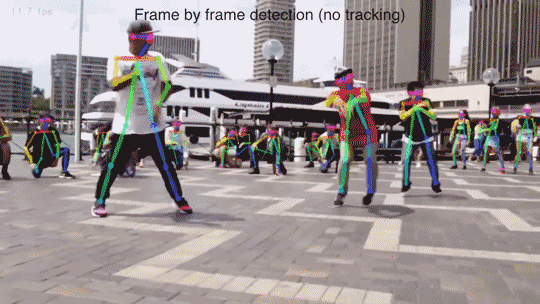

測試C ++(實時版本,用於演示)
按照說明,使用我們改動後的Caffe。
改動後caffe地址:https://github.com/CMU-Perceptual-Computing-Lab/caffe_rtpose
三種輸入選項:影象,視訊,網路攝像機
Matlab(較慢,用於COCO評估)
·相容一般的Caffe,但需要編譯matcaffe。
·執行
cd testing
get_model.sh
從我們的Web伺服器檢索最新的MSCOCO模型。
更改config.m中的caffe 地址並執行demo.m例程。
Pythoncd testing / python
ipython notebook
開啟demo.ipynb 並執行程式碼
訓練網路結構
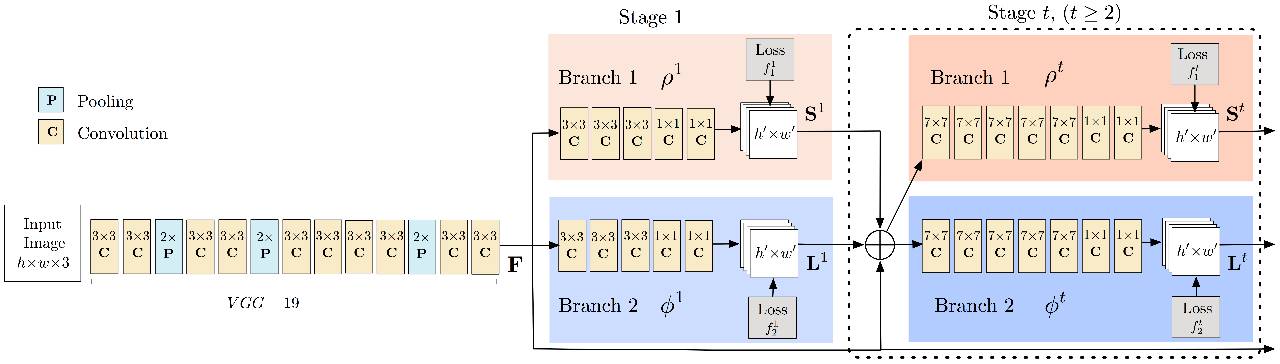
訓練步驟
執行
cd training
bash getData.sh
得到 dataset/COCO/images/ 資料夾下的資料集COCO,關鍵點資訊在 dataset/COCO / annotations / 資料夾中,COCO官方工具箱在資料夾 dataset/ COCO / coco / 下。
·在 matlab 中執行 getANNO.m,在dataset/COCO/mat/將標註格式從 json 轉換為 mat。
·在 matlab 中執行 genCOCOMask.m,得到無標籤人的掩碼影象。並且,在 matlab 中可以使用'parfor'(平行計算)來加速程式碼。
·執行genJSON('COCO'),在 dataset/COCO/json/中生成一個 json 檔案。 json 檔案包含訓練所需的原始資訊。
·執行python genLMDB.py 生成 COCO 資料庫的 LMDB 檔案,也可以執行如下程式碼:
bashget_lmdb.sh
得到已經生成好的LMDB檔案
·下載改動後的caffe,編譯 pycaffe。他將與 caffe_rtpose(用於測試)合併。
·執行
pythonsetLayers.py —exp 1
生成用於訓練的prototxt和指令碼檔案。
下載VGG-19模型。利用此模型初始化前10層網路引數。
模型地址: https://gist.github.com/ksimonyan/3785162f95cd2d5fee77
執行
bash train_pose.sh 0,1
由setLayers.py生成,開始使用兩個GPU進行訓練。
相關論文:https://github.com/shihenw/convolutional-pose-machines-release
點選閱讀原文跳轉Github資源
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
