
基於spark做一個歌手推薦系統
最近工作在做一個推薦系統,之前也有用TensorFlow寫過一個,後來學習了spark,覺得用spark來做這個推薦系統應該會更簡單一些,在這裡,我們一起來學習一下用pandas和spark做推薦系統。我們的資料來源是後臺收集的使用者聽了哪些歌手的歌曲,我們資料的同學將清洗好的歌手資料給到我之後,是這個樣子的:
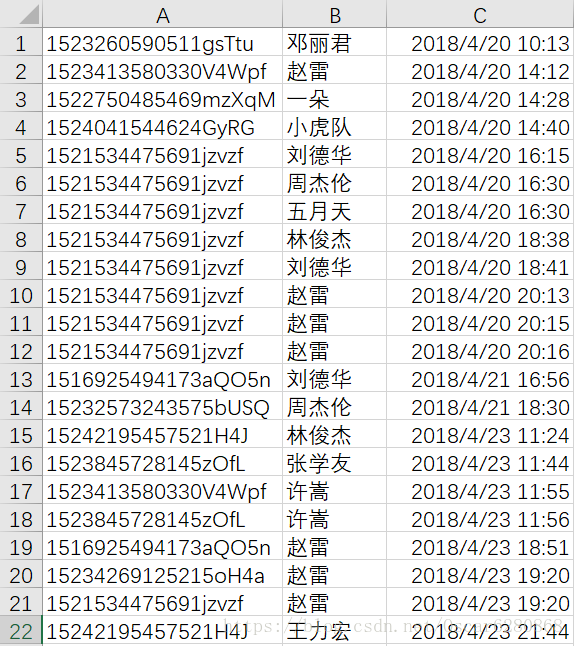
這是部分使用者聽過的歌手資料,基本也都是一些測試的資料,A列表示我們使用者的後臺ID,B列表示使用者所聽的歌手,C列表示使用者聽歌的時間。拿到這些資料,首先就要思考一下如何來使用這些資料,我的認為是使用者聽某個歌手的頻次越高,就代表這個使用者越喜歡這個歌手,暫且就把聽某個歌手的頻次作為這個使用者對這個歌手的評分。首先,我們要對這個原始的資料進行預處理,這裡我們運用的是pandas。首先我們運用pandas讀取我們的.csv資料並且給與每一列命名:
singer_recom = pd.read_csv("dataset/singer.csv", header = None, encoding = 'gbk', names = ['UserTitle', 'SingerTitle', 'Date'])然後我們可以看看這個列表:
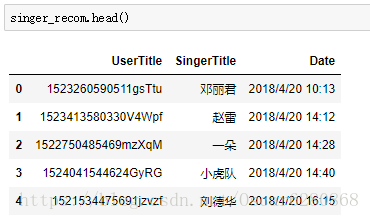
讀取了這些資料之後,我們可以去掉重複的資料:
singer3 = singer_recom.drop_duplicates(subset = 'UserTitle', keep = 'first')去掉重複資料之後,我們給每一個使用者ID分配一個int型的ID,並建立一個使用者和歌手的列表,方便後續的計算:
singer3['UserID'] = range(0, singer3.shape[0])
columns = ["UserTitle", "UserID"]
singer_user = singer3[columns]我們來看看分配了資料之後的使用者ID:
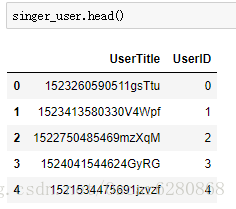
可以看到我們給每一個使用者的UserTitle都分配了一個UserID,接著我們將user_id轉化成一維陣列,索引物件是我們的user,在這裡我們用的是pandas 的Series:
user = singer_user['UserTitle'].values
user_id = singer_user['UserID' 然後我們再將UserID新增在原有的列表中的最後一列:
trans_id = []
for i in singer_recom["UserTitle"]:
trans_id.append(series_custom[i])
singer_recom["UserID"] = trans_id我們可以得到新的列表,這個列表中心添加了一列UserID:
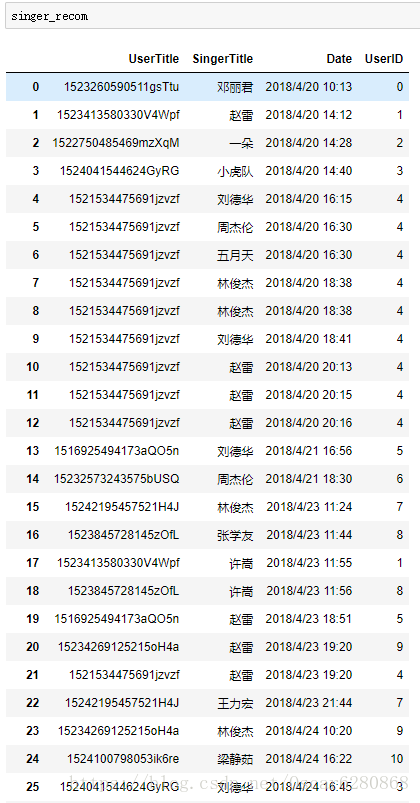
這個列表中,最後一列表示UserTitle對映的UserID,然後我們再次將這份資料去掉重複的部分,前面我們對使用者的ID進行了對映,同樣因為歌手名也是字串型別的,為了方便處理,我們同樣要像上述那樣來對歌手名分配相應的ID,程式碼如下:
singer4 = singer_recom.drop_duplicates(subset='SingerTitle', keep = 'first')
singer4['SingerID'] = range(0, singer4.shape[0])
columns = ["SingerTitle", "SingerID"]
singer_singer = singer4[columns]處理之後,我們可以得到對映ID之後的歌手ID:
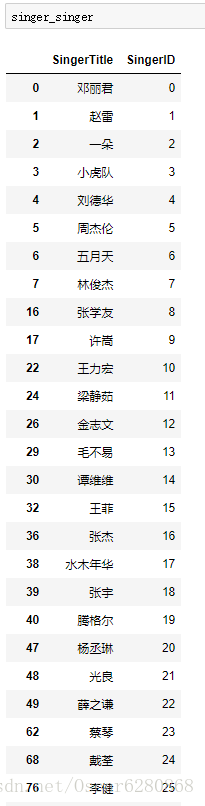
當然了,這張圖只是部分歌手的ID對映,同樣的道理,我們要講歌手ID這一列加入到原來的資料列表中,於是我們可以進行如下的操作:
singer = singer_singer['SingerTitle'].values
singer_id = singer_singer['SingerID'].values
series_custom = Series(singer_id,index=singer)
trans_singer = []
for i in singer_recom["SingerTitle"]:
trans_singer.append(series_custom[i])
singer_recom["SingerID"] = trans_singer操作完成之後我們添加了”SingerID”這一列的資料,如下圖所示:
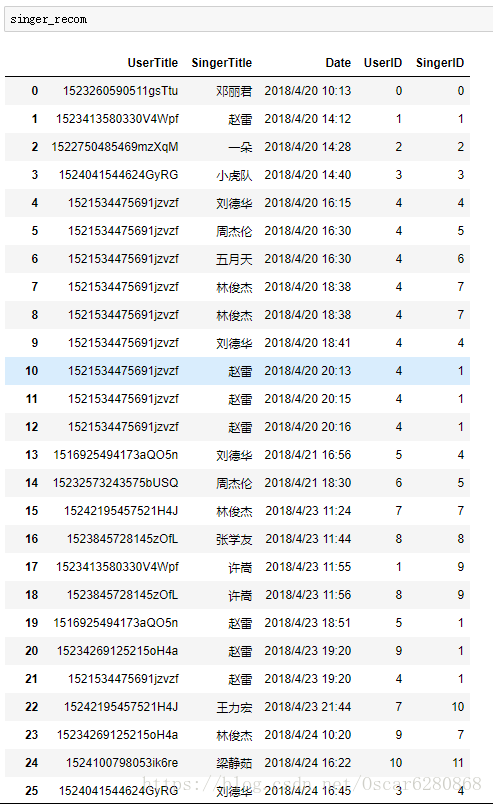
當然這只是一部分的資料,我們可以看到最後一列添加了歌手的ID值,接下來我們根據使用者和歌手的ID對這些資料進行排序:
singer_recom = singer_recom.sort_values(["UserID", "SingerID"], inplace = False)在排序之後,我們可以得到一個完整的歌手和使用者的資料列表:
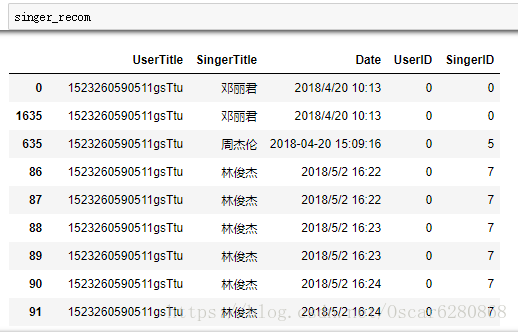
在得到這個完整的資料列表之後,我們並不是所有的資料都需要的,所以接下來我們保留有用的特徵資料,將UserID和SingerID進行聚合操作,這裡用到的是聚合函式pandas中的groupby:
target = singer_recom.groupby(['UserID', 'SingerID']).size().reset_index()在聚合了UserID和SingerID之後,我們可以用reset_index()函式將groupby之後的資料使用size()方法統計使用評率之後,轉換成DataFrame物件,處理之後我們可以得到如下結果:
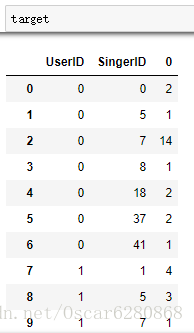
然後我們可以將每個歌手的頻次標註出來,然後聽的歌手的頻次就是我們對這個歌手的打分,打分系統是一個複雜的系統,我們暫且很簡單地認為使用者聽哪個歌手的歌多,就對這個歌手的評分就高:
target.columns = ['UserID', 'SingerID', 'Rating']最後我們可以得到含有打分項的列表:
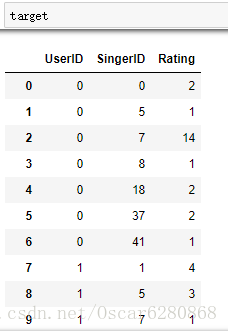
為了方便我們對照歌手名,我們將歌手名和使用者名稱merge到這張表中來:
df_user = pd.merge(target, singer_singer, on = 'SingerID', how = 'left', suffixes = ('_', ''))
df_user = pd.merge(df_user, singer_user, on = 'UserID', how = 'left', suffixes = ('_', ''))在merge完成之後,我們的資料預處理就完成了,就可以得到我們需要的資料格式了,然後我們把預處理完成之後的.csv資料儲存起來:
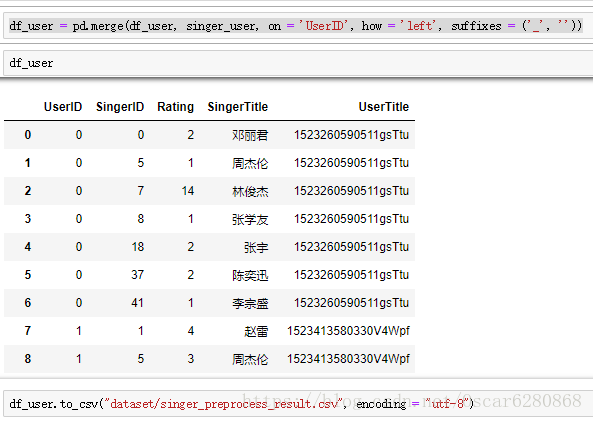
上面就是我們拿到資料之後到預處理完成之後的過程,接下來我們就是進行推薦演算法的實現,這裡我們用到的是pyspark,首先我們匯入pyspark庫,然後讀取我們已經經過預處理之後的資料:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("singer_recommendation").master("local").getOrCreate()
df = spark.read.format('com.databricks.spark.csv').options(header = 'true', inferschema = 'true').load("dataset/singer_preprocess_result.csv")在匯入了資料之後,我們再來進行特徵的提取,在spark中直接可以使用select()方法:
df_singer_recommend = df.select("UserID", "SingerID", "Rating")在進行完特徵提取之後,我們這裡就要用到spark的rdd了,什麼是RDD?RDD(Resilient Distributed Dataset)叫做彈性分散式資料集,是Spark中最基本的資料抽象,它代表一個不可變、可分割槽、裡面的元素可平行計算的集合。RDD具有資料流模型的特點:自動容錯、位置感知性排程和可伸縮性。RDD允許使用者在執行多個查詢時顯式地將工作集快取在記憶體中,後續的查詢能夠重用工作集,這極大地提升了查詢速度,建立rdd的程式碼如下:
singer_rdd = df_singer_recommend.rdd
trainingRDD = singer_rdd.cache()這裡運用到了rdd的快取cache方法,這樣可以將rdd快取到磁碟或者記憶體中,以便於後續的複用。準備好了這些之後,我們就可以開始訓練模型了,首先我們要匯入spark的庫:
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating這裡用到的是pyspark庫中的ALS演算法,關於ALS演算法,我稍後會再發布一篇博文再細說這個推薦演算法,這裡我們就暫且理解這是一個推薦系統的演算法,然後我們就可以去訓練一個推薦系統的模型:
rank = 10
numIterations = 10
model = ALS.train(trainingRDD, rank, numIterations)這裡我們來看看ALS中的train方法,這裡的rank表示隱藏因子的個數,numIterations表示迭代的次數,然後trainingRDD表示我們訓練的資料來源,這是我們pyspark中的API,很方便使用的,然後訓練完了之後我們就可以得到我們的模型model,這裡我們再來簡單地看看ALS演算法是怎麼一回事,ALS演算法其實是交替最小二乘法,比如使用者聽歌,如果每個歌手都是一個維度,但是使用者只會去聽部分自己喜歡的歌手的歌,所以在這整個矩陣中,只會有很小的一部分會有值,大部分的地方都是沒有值的,我們就認為這個矩陣就是一個稀疏矩陣,然後我們要想辦法將這個矩陣的資料填滿,讓她形成一個稠密的矩陣,操作起來就是說通過降維的方法來補全矩陣,對矩陣沒有出現的值進行估值,場用的方法就是SVD(奇異值分解),這個方法在矩陣分解之前需要先把評分矩陣R缺失值補全,補全之後稀疏矩陣R矩陣表示成稠密矩陣R’,然後我們可以將R’矩陣進行分解成:
在這個公式中,假如R’是一個m x n的矩陣,那麼可以分解成,U矩陣的轉秩m x k,S矩陣k x s,和V矩陣s x n矩陣相乘,這個公式中,選取U中的K列和V中的s行作為隱特徵數,從而達到降維的目的。ALS推薦演算法大概的思想就是這個樣子,我後續會寫一篇關於ALS的演算法的詳細介紹,大家一起學習,這裡就點到為止。接下來我們定義一個方法來返回top5的商品ID:
def top5_productID(userID):
recommendedResult = model.recommendProducts(userID, 5)
product_id_list = []
for i in range(5):
product_id_list.append(recommendedResult[i].product)
return product_id_list這裡就是利用spark的API中的recommendProducts方法來返回排名最高的5個商品ID。有了這個list,我們再來構建一個dataframe:
def construct_dataframeData(userList):
data = []
for user in userList:
res = top5_productID(user)
res.insert(0, user)
data.append(res)
return data通過這個方法,我們就可以將每一個使用者推薦的5個商品,也就是將每一個使用者所推薦的5個歌手插入到dataframe中:
data = construct_dataframeData(unique_userid_list)接著我們可以得到一個結構體dataframe:

這個就是我們推薦結果矩陣中的一部分結果,第一個數字表示使用者的UserID,後面的5個數字表示推薦給使用者的SingerID,其實這個矩陣就相當於是我們的推薦結果,我們接下來需要做的就是將這個矩陣解析成我們可以看得懂的文字矩陣輸出。所以我們再寫一個方法,將我們數字的矩陣對映成文字的矩陣結果輸出:
def parse_data(dataList):
res = []
for item in dataList:
res_item = []
UserTitle = df.filter(df['UserID'] == item[0]).select("UserTitle").collect()[0].UserTitle
res_item.append(UserTitle)
for i in range(1, 6):
SingerTitle = df.filter(df['SingerID'] == item[i]).select("SingerTitle").collect()[0].SingerTitle
res_item.append(SingerTitle)
res.append(res_item)
return res通過這個方法,我們將數字矩陣可以轉化成文字矩陣,我們來看看最終推薦的部分結果吧:

這樣就可以看到每一個使用者所對用的最喜歡的5個歌手,所以我們就得到了推薦最終的結果,我們可以將這些結果匯出成.csv:
df_res = pd.DataFrame(parseData, columns = ['UserTitle', 'SingerName1', 'SingerName2', 'SingerName3', 'SingerName4', 'SingerName5'])
df_res.to_csv("singer_recommend_result.csv", index=False, encoding="utf-8")有了這個推薦列表,我們可以將這個列表上線到我們的後臺服務中去。到這裡我們就可以說利用spark完成了一個完整的歌手推薦系統,希望這篇精心的博文能夠對大家的資料預處理以及推薦系統的設計實現,有了一個新的認識,新的啟發,對大家的推薦系統理解有所幫助。本人能力有限,如在博文內容中有所紕漏,還望大家不吝指教,如果有轉載,也請標明博文出處,蟹蟹。