
理解Java字串常量池與intern()方法
閱讀目錄
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8;
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
剛開始看字串的時候,經常會看到類似的題,難免會有些不解,檢視答案總會提到字串常量池、執行常量池等概念,很容易讓人搞混。
下面就來說說Java中的字串到底是怎樣建立的。
Java記憶體區域
String有兩種賦值方式,第一種是通過“字面量”賦值。
String str = "Hello";
第二種是通過new關鍵字建立新物件。
String str = new String("Hello");
要弄清楚這兩種方式的區別,首先要知道他們在記憶體中的儲存位置。

圖片來源:http://286.iteye.com/blog/1928180
我們平時所說的記憶體就是圖中的執行時資料區(Runtime Data Area),其中與字串的建立有關的是方法區(Method Area)、堆區(Heap Area)和棧區(Stack Area)。
- 方法區:儲存類資訊、常量、靜態變數。全域性共享。
- 堆區:存放物件和陣列。全域性共享。
- 棧區:基本資料型別、物件的引用都存放在這。執行緒私有。
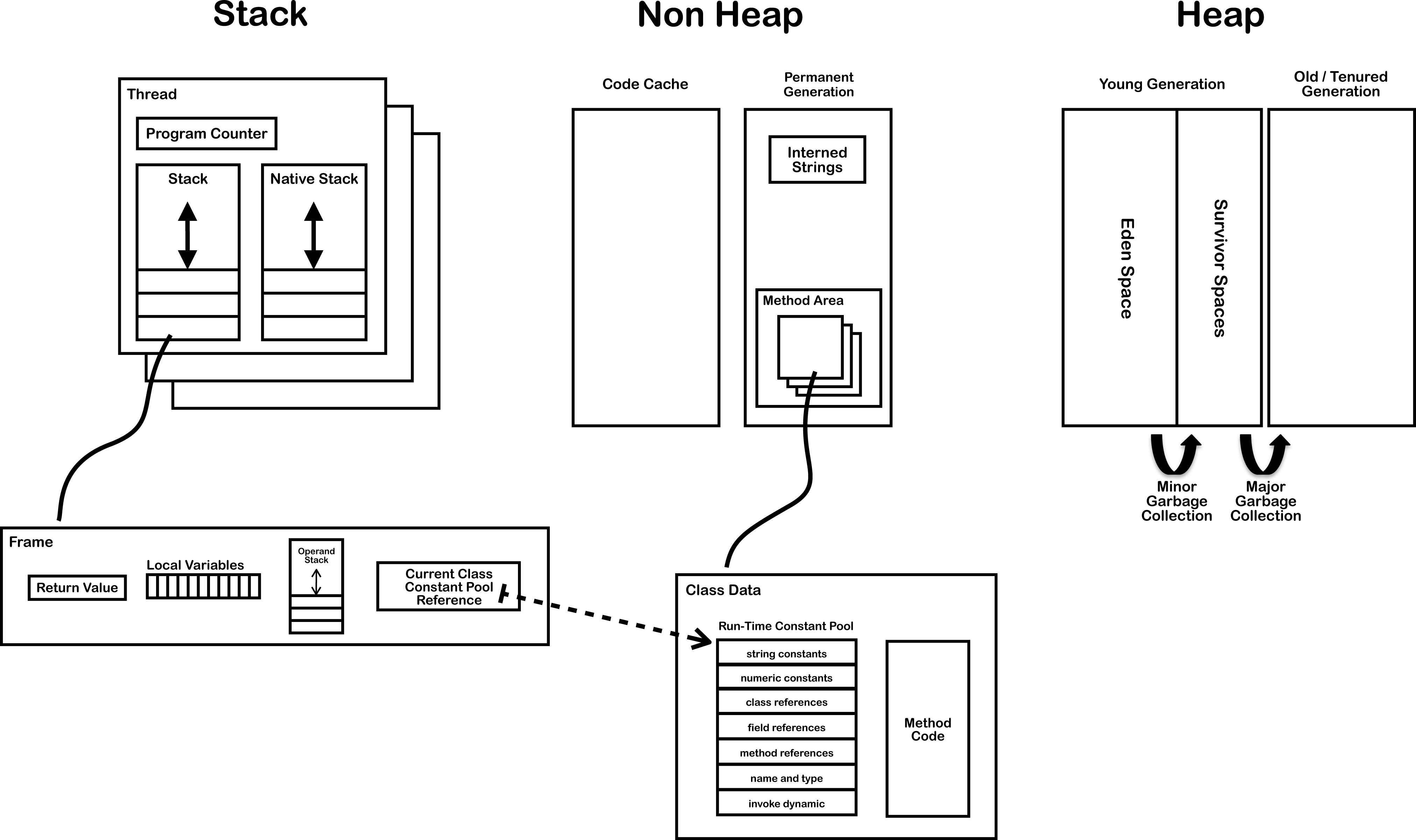
每當一個方法被執行時就會在棧區中建立一個棧幀(Stack Frame),基本資料型別和物件引用就存在棧幀中區域性變量表(Local Variables)。
當一個類被載入之後,類資訊就儲存在非堆的方法區中。在方法區中,有一塊叫做執行時常量池(Runtime Constant Pool)
和String最相關的是字串池(String Pool),其位置在方法區上面的駐留字串(Interned Strings)的位置,之前一直把它和執行時常量池搞混,其實是兩個完全不同的儲存區域,字串常量池是全域性共享的。字串呼叫String.intern()方法後,其引用就存放在String Pool中。
兩種建立方式在記憶體中的區別
瞭解了這些概念,下面來說說究竟兩種字串建立方式有何區別。
下面的Test類,在main方法裡以“字面量”賦值的方式給字串str賦值為“Hello”。
public class Test {
public static void main(String[] args) {
String str = "Hello";
}
}
Test.java檔案編譯後得到.class檔案,裡面包含了類的資訊,其中有一塊叫做常量池(Constant Pool)的區域,.class常量池和記憶體中的常量池並不是一個東西。
.class檔案常量池主要儲存的就包括字面量,字面量包括類中定義的常量,由於String是不可變的(String為什麼是不可變的?),所以字串“Hello”就存放在這。
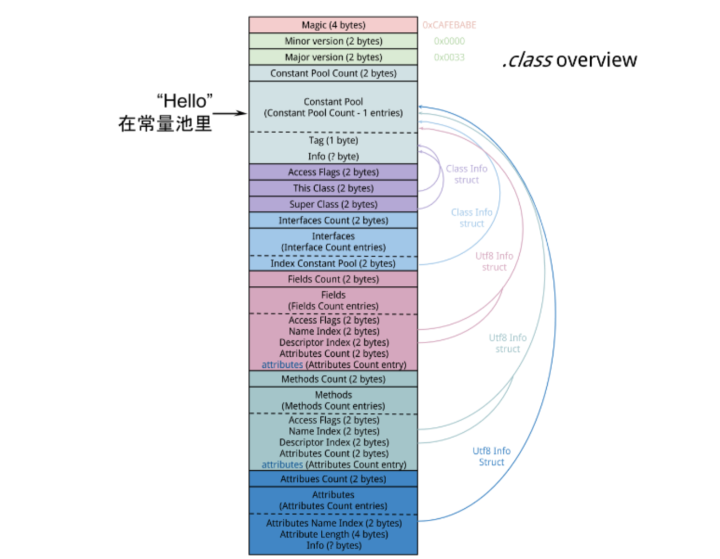
當程式用到Test類時,Test.class被解析到記憶體中的方法區。.class檔案中的常量池資訊會被載入到執行時常量池,但String不是。
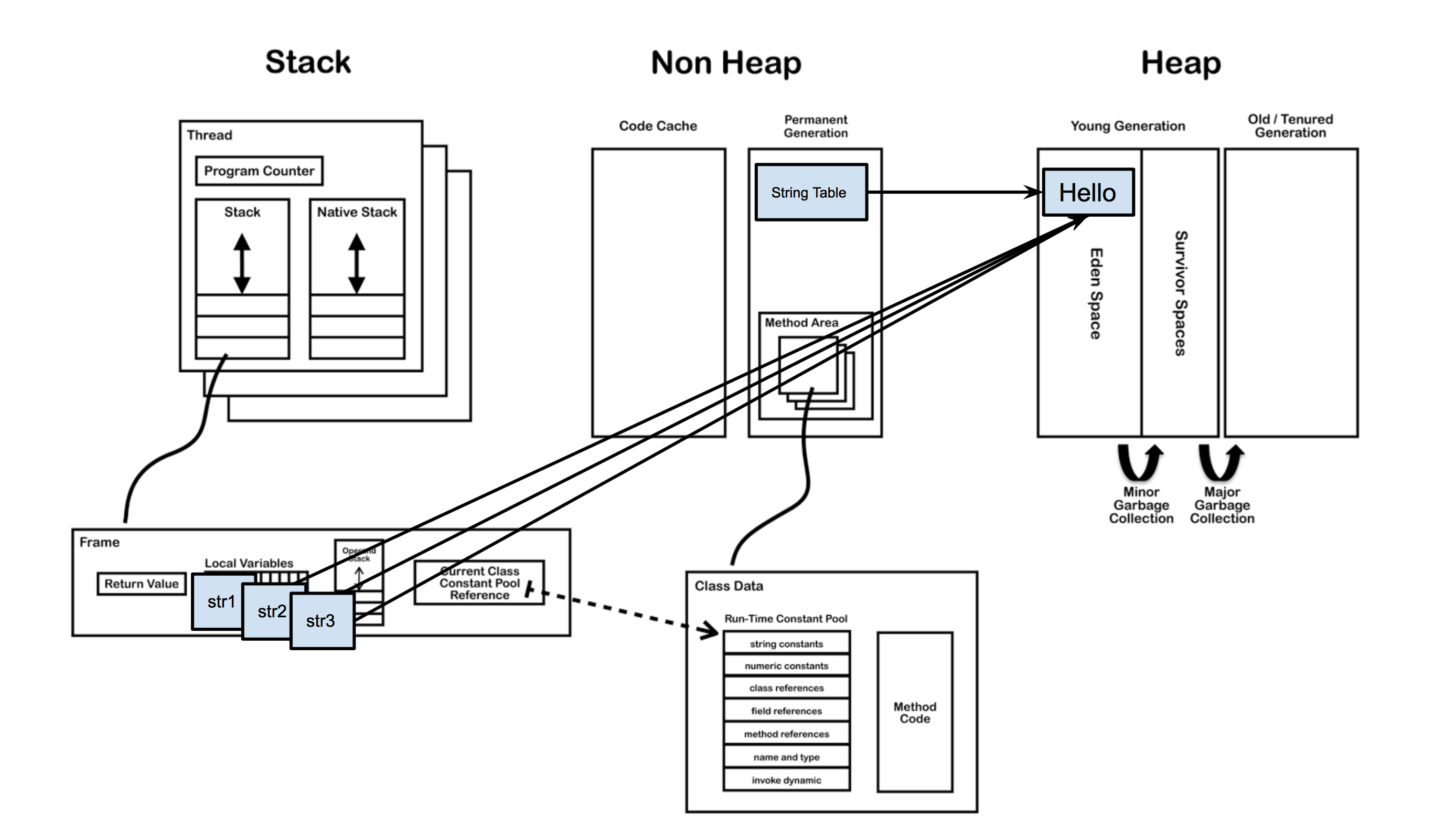
例子中“Hello”會在堆區中建立一個物件,同時會在字串池(String Pool)存放一個它的引用,如下圖所示。
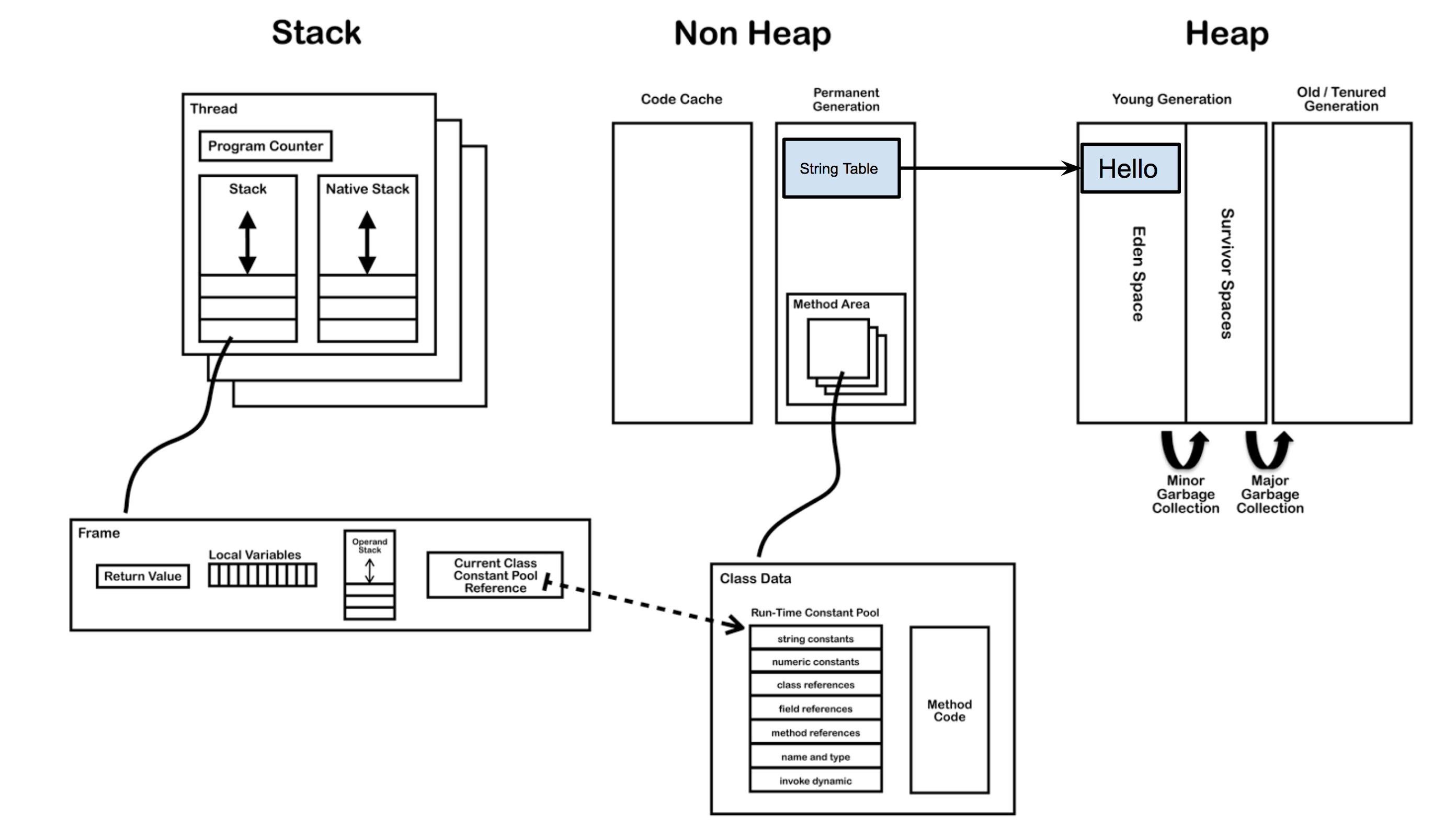
此時只是Test類剛剛被載入,主函式中的str並沒有被建立,而“Hello”物件已經建立在於堆中。
當主執行緒開始建立str變數的,虛擬機器會去字串池中找是否有equals(“Hello”)的String,如果相等就把在字串池中“Hello”的引用複製給str。如果找不到相等的字串,就會在堆中新建一個物件,同時把引用駐留在字串池,再把引用賦給str。
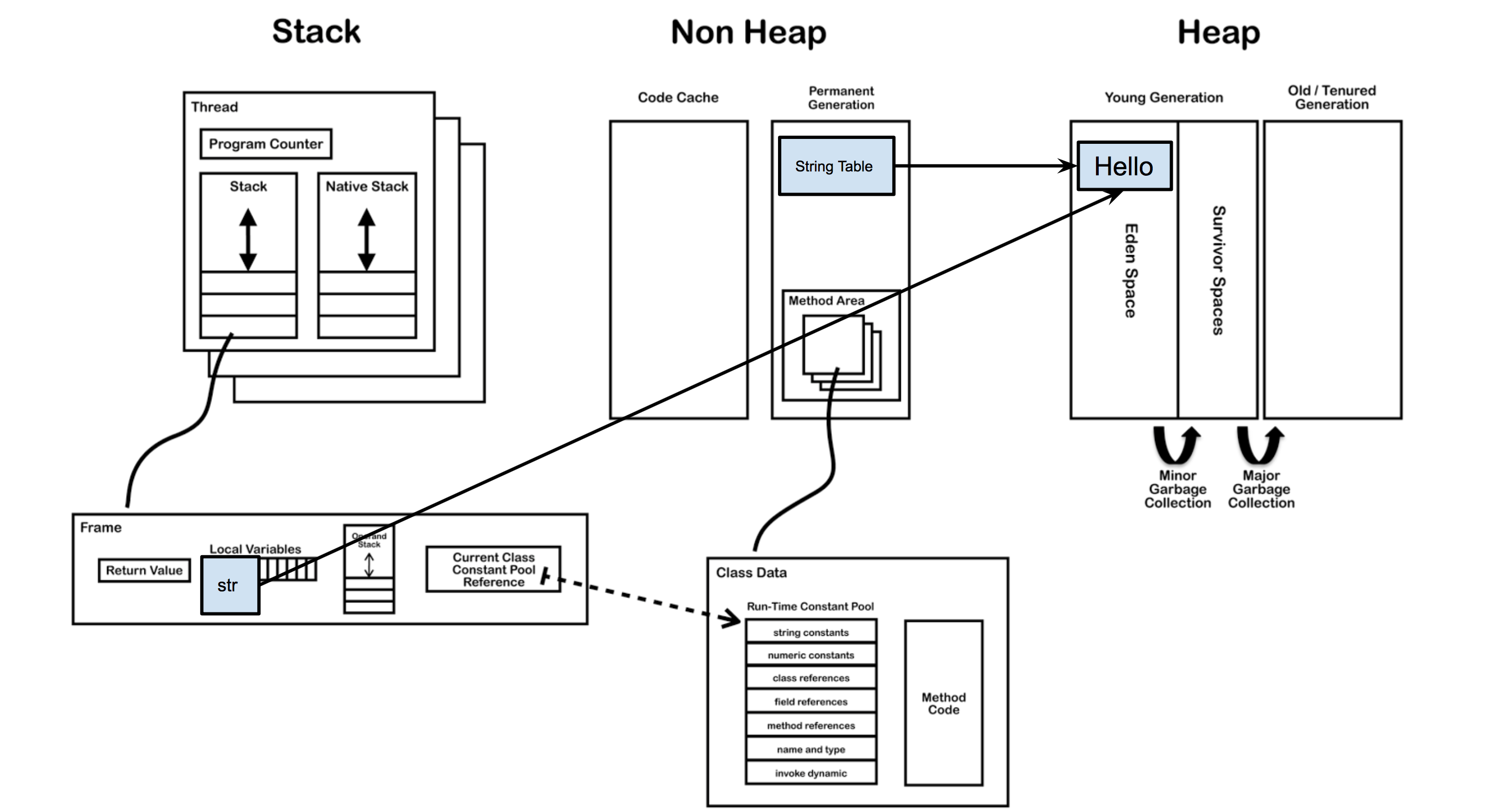
當用字面量賦值的方法建立字串時,無論建立多少次,只要字串的值相同,它們所指向的都是堆中的同一個物件。
public class Test {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = “Hello”;
String str3 = “Hello”;
}
}
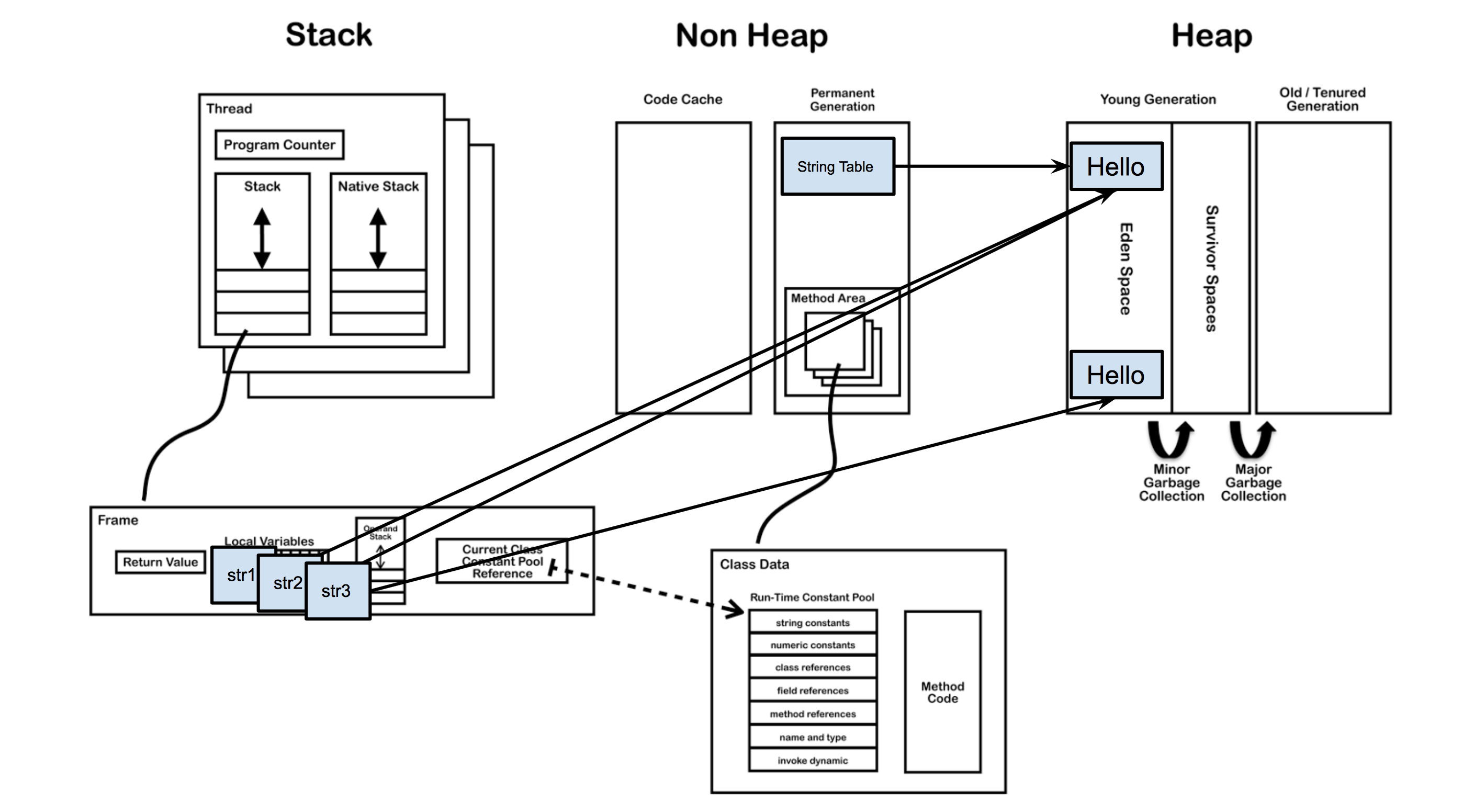
當利用new關鍵字去建立字串時,前面載入的過程是一樣的,只是在執行時無論字串池中有沒有與當前值相等的物件引用,都會在堆中新開闢一塊記憶體,建立一個物件。
public class Test {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = “Hello”;
String str3 = new String("Hello");
}
}
解釋開頭的例子
現在我們來回頭看之前的例子。
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8;
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
有了上面的基礎,之前的問題就迎刃而解了。
s1在建立物件的同時,在字串池中也建立了其物件的引用。
由於s2也是利用字面量建立,所以會先去字串池中尋找是否有相等的字串,顯然s1已經幫他建立好了,它可以直接使用其引用。那麼s1和s2所指向的都是同一個地址,所以s1==s2。
s3是一個字串拼接操作,參與拼接的部分都是字面量,編譯器會進行優化,在編譯時s3就變成“Hello”了,所以s1==s3。
s4雖然也是拼接,但“lo”是通過new關鍵字建立的,在編譯期無法知道它的地址,所以不能像s3一樣優化。所以必須要等到執行時才能確定,必然新物件的地址和前面的不同。
同理,s9由兩個變數拼接,編譯期也不知道他們的具體位置,不會做出優化。
s5是new出來的,在堆中的地址肯定和s4不同。
s6利用intern()方法得到了s5在字串池的引用,並不是s5本身的地址。由於它們在字串池的引用都指向同一個“Hello”物件,自然s1==s6。
總結一下:
- 字面量建立字串會先在字串池中找,看是否有相等的物件,沒有的話就在堆中建立,把地址駐留在字串池;有的話則直接用池中的引用,避免重複建立物件。
- new關鍵字建立時,前面的操作和字面量建立一樣,只不過最後在執行時會建立一個新物件,變數所引用的都是這個新物件的地址。
由於不同版本的JDK記憶體會有些變化,JDK1.6字串常量池在永久代,1.7移到了堆中,1.8用元空間代替了永久代。但是基本對上面的結論沒有影響,思想是一樣的。
intern()方法
下面來說說跟字元常量池有關的intern()方法。
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
這個方法是一個本地方法,註釋中描述得很清楚:“如果常量池中存在當前字串,就會直接返回當前字串;如果常量池中沒有此字串,會將此字串放入常量池中後,再返回”。
由於上面提到JDK1.6之後,字串常量池在記憶體中的位置發生了變化,所以intern()方法在不同版本的JDK中也有所差別。
來看下面的程式碼:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
在JDK1.6中的執行結果是false false,而在1.7中結果是false true。
將intern()語句下移一行。
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
在JDK1.6中的執行結果是false false,在1.7中結果也是false false。
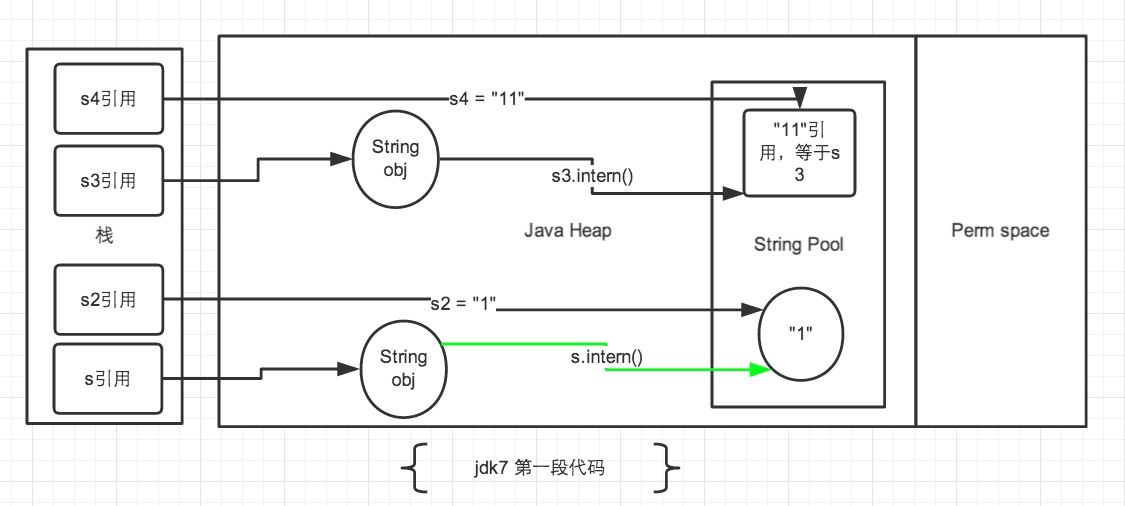
下面來解釋一下JDK1.6環境下的結果:

圖中綠色線條代表string物件的內容指向,黑色線條代表地址指向。
JDK1.6中的intern()方法只是返回常量池中的引用,上面說過,常量池中的引用所指向的物件和new出來的物件並不是一個,所以他們的地址自然不相同。
接著來說一下JDK1.7:
再貼一下程式碼
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
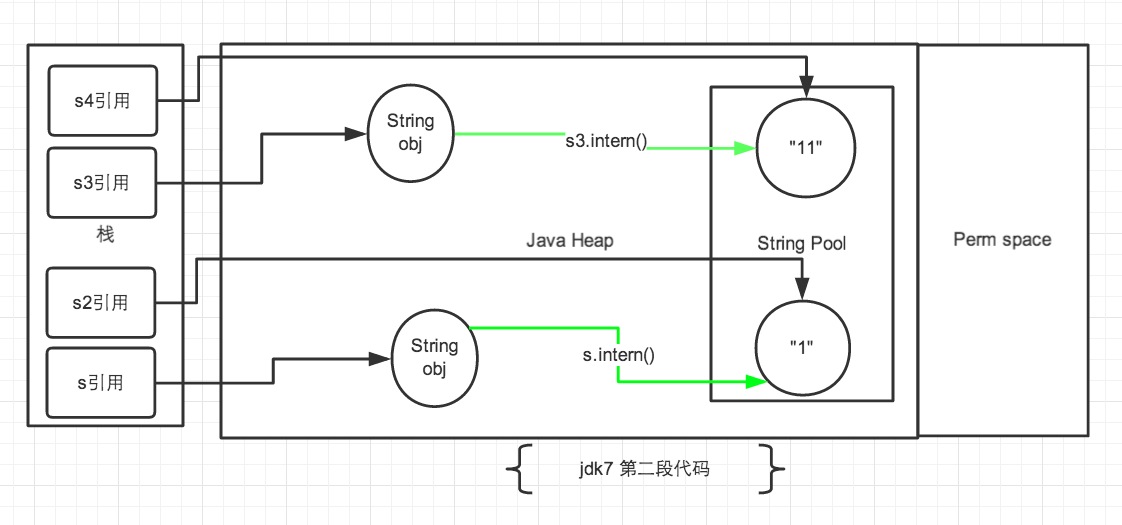
建立s3生成了兩個最終物件(不考慮兩個new String("1"),常量池中也沒有“11”),一個是s3,另一個是池中的“1”。如果在1.6中,s3呼叫intern()方法,則先在常量池中尋找是否有等於“11”的物件,本例中自然是沒有,然後會在堆中建立一個“11”的物件,並在常量池中儲存它的引用並返回。然而在1.7中呼叫intern(),如果這個字串在常量池中是第一次出現,則不會重新建立物件,直接返回它在堆中的引用。在本例中,s4和s3指向的都是在堆中的那個物件,所以s3和s4的地址相等。
由於s是new出來的,所以會在常量池和堆中建立兩個不同的物件,s.intern()後,發現“1”並不是第一次出現在常量池了,所以接下來就和之前沒有區別了。
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
將intern()語句下移一行後,執行順序發生改變,執行到intern()時,字串常量池已經存在“1”和“11”了,並不是第一次出現,字面量物件依然指向的是常量池,所以字面量建立的物件和new的物件地址一定是不同的。
轉載請註明原文連結:http://www.cnblogs.com/justcooooode/p/7603381.html
參考資料
https://www.zhihu.com/question/29884421/answer/113785601
http://www.cnblogs.com/iyangyuan/p/4631696.html
https://tech.meituan.com/in_depth_understanding_string_intern.html
https://javaranch.com/journal/200409/ScjpTipLine-StringsLiterally.html ——【譯】Java中的字串字面量