
雲平臺例項操作神器Terraform
Terraform功能簡介
Terraform是IT 基礎架構自動化編排工具,它的口號是 "Write,Plan, and create Infrastructure as Code", 基礎架構即程式碼。
怎麼理解這句話,我們先假設在沒有Terraform的年代我們是怎麼操作雲服務。
方式一:直接登入到雲平臺的管控頁面,人工點選按鈕、鍵盤敲入輸入引數的方式來操作,這種方式對於單個或幾個雲伺服器還可以維護的過來,但是當雲服務規模達到幾十幾百甚至上千以後,明顯這種方式對於人力來說變得不再現實,而且容易誤操作。
方式二:雲平臺提供了各種SDK,將對雲服務的操作拆解成一個個的API供使用廠商通過程式碼來呼叫。這種方式明顯好於方式一,使大批量操作變得可能,而且程式碼測試通過後可以避免人為誤操作。但是隨之帶來的問題是廠商們需要專業的開發人員(Java
方式三:雲平臺提供了命令列操作雲服務的工具,例如AWS CLI,這樣租戶廠商不再需要軟體開發人員就可以實現對平臺的命令操作。命令就像Sql一樣,使用增刪改查等操作元素來管理雲。
方式四:Terraform主角登場,如果說方式三中CLI是命令式操作,需要明確的告知雲服務本次操作是查詢、新增、修改、還是刪除,那麼Terraform就是目的式操作,在本地維護了一份雲服務狀態的模板,模板編排成什麼樣子的,雲服務就是什麼樣子的。對比方式三的優勢是我們只需要專注於編排結果即可,不需要關心用什麼命令去操作。
Terraform的意義在於,通過同一套規則和命令來操作不同的雲平臺(包括私有云)。
Terraform知識準備:
核心檔案有2個,一個是編排檔案,一個是狀態檔案
main.tf檔案:是業務編排的主檔案,定製了一系列的編排規則,後面會有詳細介紹。
terraform.tfstate:本地狀態檔案,相當於本地的雲服務狀態的備份,會影響terraform的執行計劃。
如果本地狀態與雲服務狀態不一樣時會怎樣?
這個大家不需要擔心,前面介紹過Terraform是目的式的編排,會按照預設結果完成編排並最終同步更新本地檔案。
Provider:Terraform定製的一套介面,跟OpenStack
Terraform安裝:
官方安裝指南:https://www.terraform.io/intro/getting-started/install.html
本質是下載二進位制的檔案安裝到linux中,然後通過terraform命令來操作。
安裝後需要在path中配置terraform:
export PATH=$PATH:/path/to/dir
export PATH=$PATH:/home/terraform
source ~/.bashrc
source只是讓配置立刻生效,如果要永久生效需要直接修改檔案
方案1:在/etc/profile檔案中新增變數【對所有使用者生效(永久的)】
# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
方案2:在使用者目錄下的.bash_profile檔案中增加變數【對單一使用者生效(永久的)】
Terraform的基本命令:
1,mkdir一個乾淨的工作目錄,為後續操作做準備,該目錄就像git的倉庫,或者像軟體開發中的workspace。
2,需要建立一個.tf檔案,指定provider等資訊,工作目錄下需要有至少一個tf檔案,否則後續命令無法進行。
3,執行terraform init命令,就像git init一樣,對當前目錄做初始化,下載tf中的provider,並喂後續的操作準備必要的環境條件。
4,terraform plan,預覽執行計劃,不是必須的,但是強烈建議,好明白這次要把雲服務弄成什麼樣子。Ps:該命令在後期版本與apply合併成一個,所以請根據自己的版本來使用plan命令。
5,terraform apply,真正執行編排計劃
6,terraform show,展示現在狀態。
6,terraform destroy,銷燬雲服務,將tf中的雲服務清理乾淨
Terraform的編排:
先看個簡單的官網的例子:
provider "aws" {
access_key = "ACCESS_KEY_HERE"
secret_key = "SECRET_KEY_HERE"
region = "us-east-1"
}
resource "aws_instance" "example" {
ami = "ami-2757f631"
instance_type = "t2.micro"
}
Provider說明是個AWS的provider,剩下的鑑權和區域比較好理解;請注意provider的名字必須嚴格按照terraform的規則,不是你隨便亂填的。例如阿里雲對應的provider名稱是“alicloud”,你如果寫個“aliyun”是會出錯的。
Resource是在定義資源,第一個屬性aws_instance說明是個aws的例項,通過命名規則中的字首來指明provider;第二個屬性example是本resource的name;ami指明用哪個映象來啟動例項;instance_type指定的是例項的“規格”,在雲服務裡定義了不同的型別來代表著伺服器不同的配置(CPU、記憶體、磁碟等硬體資源)。
Terrafomr執行時的output如下圖:
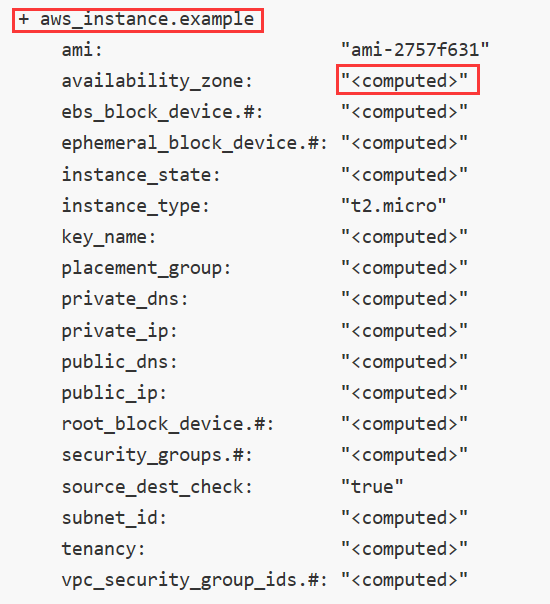
號代表的是新增操作,與使用git一樣,同理如果看到-號那就是要在雲上做刪除操作,修改操作+-會同時出現,本質上在雲上會先刪除再新增。向ami、instance_type我們顯示給定的,或者說本地倉庫檔案已知的屬性,會直接在右邊顯示出來;其他未知的顯示的是computed,代表的是要在雲上操作結束後才能知道。
Terrafrom的執行計劃:
有過Spark基礎的開發人員都知道一個概念DAG(有向無環圖),是為了最大程度地並行同時也要保證各任務間的依賴性。Terraform也是個並行執行的框架,而任務間的依賴性是通過顯示依賴和隱式依賴來實現的。
如基於上面的tf基礎上又配置了一個資源:
resource "aws_eip" "ip" {
instance = "${aws_instance.example.id}"
}
那麼在建立aws_eip.id這個資源時由於裡面的instance需要指定aws_instance.example的id,而aws_instance.example的id只有例項建立後才能獲得,所以這就形成了一個隱式的依賴,執行計劃就要先執行aws_instance.example這個resource再執行aws_eip.ip這個resource。
再看下面這個例子:
resource "aws_instance" "example" {
ami = "ami-2757f631"
instance_type = "t2.micro"
depends_on = ["aws_s3_bucket.example"]
}
resource "aws_s3_bucket" "example" {
bucket = "terraform-getting-started-guide"
acl = "private"
}
在aws_instance.example這個resource建立時通過depends_on屬性顯示的指定了依賴,所以先執行aws_s3_bucket.example這個執行計劃再回頭來建立這個例項。
如果resource間沒有依賴,terraform會並行的傳送任務到雲端完成任務。
如果你想在resource成功建立後執行某些操作,就需要用到Provisioner配置,示例:
resource "aws_instance" "example" {
ami = "ami-b374d5a5"
instance_type = "t2.micro"
provisioner "local-exec" {
command = "echo ${aws_instance.example.public_ip} > ip_address.txt"
}
}
當resource建立完畢後可以在ip_address.txt檔案中看到該aws的ip地址。
Provisioner的使用會帶來一個問題,如果例項建立成功但是provisioner失敗會如何?Terraform並不具有關係型資料庫那樣的事務,一定要保證一起成功或失敗,如果發生這種情況,resource的例項會被成功建立但是狀態會被置為“tainted”汙染的,是為了告知雲使用者該服務並不是安全的。當再次執行resouce計劃時Terraform並不會在原來基礎上retry失敗的provisioner,而是整個resource剷掉重新執行一邊編排。
Terraform的出入參變數:
有些引數我們不想通過硬編碼的方式寫入到tf中,我們就會採用變數方式來搞定這種場景。
一般我們會把所有的變數都單獨拿到一個tf檔案裡去宣告,例如variables.tf,雖然不是必須要命名成variables.tf,但是我們約定俗成這麼做。
Variables.tf內容如下:
variable "access_key" {}
variable "secret_key" {}
variable "region" {
default = "us-east-1"
}
很好理解,region我們給了預設值。
在其他tf中引用方式如下:
provider "aws" {
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}
也很理解,那麼剩下的問題是如何在使用時設定這些變數?
方式一:命令引數設定
$ terraform apply -var 'access_key=foo' -var 'secret_key=bar'方式二:預設引數檔案
Terraform預設會載入terraform.tfvars or *.auto.tfvars的檔案為初始化引數的檔案,檔案內容是鍵值對的方式:
access_key = "foo"
secret_key = "bar"
方式三:命令制定引數檔案
如果不按照方式二的命名規則,而是自己自定義檔名,可以採用方式一和方式二結合的方式指定引數檔案:
$ terraform apply -var-file="secret.tfvars" -var-file="production.tfvars"方式四:操作使用者的環境變數中去獲取
Terraform會環境變數path中找TF_VAR_開頭的變數並把後面的內容對映成自己的變數引數,本方法不推薦。
方式五:什麼都不預配置,執行Terraform時遇到沒有賦值的變數會在控制檯給出提示讓操作員直接輸入。該方式不推薦,但是當輸入密碼等場景時從安全形度來說可以考慮使用。
除開String型別變數,Terraform還支援List和Map型別:
List的定義:
variable "cidrs" { type = "list" }
List的賦值:
cidrs = [ "10.0.0.0/16", "10.1.0.0/16" ]
Map的定義和賦值:
variable "amis" {
type = "map"
default = {
"us-east-1" = "ami-b374d5a5"
"us-west-2" = "ami-4b32be2b"
}
}
對Map的使用時會呼叫Terraform的內部函式:
resource "aws_instance" "example" {
ami = "${lookup(var.amis, var.region)}"
instance_type = "t2.micro"
}
Lookup就是從amis這個map變數中根據region這個變數去get。
學完Terraform的入參,Terraform的出參就變得很簡單了。
把一次編排看成Oracle的一個儲存過程,Terraform的出參就像是存過的產出,開發人員可以在編排時定義output出參來指定自己關心的內容,該內容會在任務執行的日誌中高亮顯示,而且在任務執行完畢後我們可以通過terrafomr output var_name的方式檢視引數結果。
出參宣告:
output "ip" {
value = "${aws_eip.ip.public_ip}"
}
生產級應用我們往往將Terraform的state檔案維護在雲端或遠端伺服器,這樣既可以保證高可用性,也可以方便多名編排人員共同維護。
需要新增以下配置:
terraform {
backend "consul" {
address = "demo.consul.io"
path = "getting-started-RANDOMSTRING"
lock = false
}
}
這樣在執行terraform init時就會在本地和remote端各維護一份狀態檔案。
Terraform在Iaas基礎維護方面的側重點,只是對雲平臺例項級別的管理,如果要對例項內部進行更復雜的編排需要配合ansible元件。