
排程器&負載均衡排程演算法整理
阿新 • • 發佈:2018-11-14
一、Linux 排程器
Linux中程序排程器已經經過很多次改進了,目前核心排程器是在CFS(Completely Fair Scheduler),從2.6.23開始被作為預設排程器。用作者Ingo Molnar的話講,CFS在真實的硬體上模擬了完全理想的多工處理器。也就是說CFS試圖模擬CPU。理想、精確的多工CPU是一個可以同時並行執行多個程序的硬體CPU,給每個程序分配等量的處理器功率(並非時間)。如果只有一個程序執行,那麼它將獲得100%的處理器功率,兩個程序就是50%,依次平均分配。這樣就可以實現所有程序公平執行。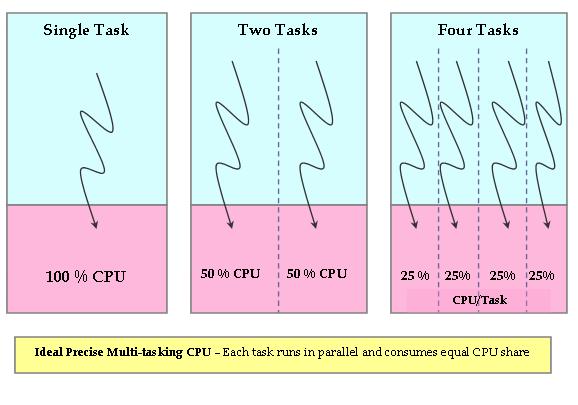
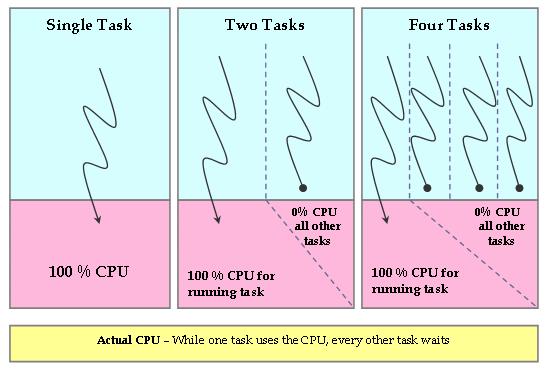 CFS排程器就是為了減少系統中的這種不公平,CFS跟蹤記錄CPU的公平分配份額,用來分配給系統中的每個程序。因此CFS在一小部分CPU時鐘速度下執行一個公平時鐘。公平時鐘增加速度通過用實際時鐘時間除以等待程序個數計算。結果就是分配給每個程序的CPU時間。
程序等待CPU的時候,排程器會跟蹤記錄它將會使用理想的處理器時間。這個等待時間用每個程序等待執行時間來表示,可以用來對程序進行排序,決定其在被搶佔之前可以被分配的CPU時間。等待時間最長的程序會被首先選擇排程到CPU上執行,當這個程序執行時,它的等待時間會相應減少,其他程序等待時間自然就會增加了。這樣馬上就會有另外一個等待時間最長的程序出現,當前執行的程序就會被搶佔。基於這一原理,CFS排程器試圖公平對待所有程序並使每個程序等待時間為0,這樣每個程序就可以擁有等量的CPU資源,達到完全公平的一種理想狀態。
CFS排程器就是為了減少系統中的這種不公平,CFS跟蹤記錄CPU的公平分配份額,用來分配給系統中的每個程序。因此CFS在一小部分CPU時鐘速度下執行一個公平時鐘。公平時鐘增加速度通過用實際時鐘時間除以等待程序個數計算。結果就是分配給每個程序的CPU時間。
程序等待CPU的時候,排程器會跟蹤記錄它將會使用理想的處理器時間。這個等待時間用每個程序等待執行時間來表示,可以用來對程序進行排序,決定其在被搶佔之前可以被分配的CPU時間。等待時間最長的程序會被首先選擇排程到CPU上執行,當這個程序執行時,它的等待時間會相應減少,其他程序等待時間自然就會增加了。這樣馬上就會有另外一個等待時間最長的程序出現,當前執行的程序就會被搶佔。基於這一原理,CFS排程器試圖公平對待所有程序並使每個程序等待時間為0,這樣每個程序就可以擁有等量的CPU資源,達到完全公平的一種理想狀態。
二、Hadoop排程器
FIFO 排程器
整合在 JobTracker 中的原有排程演算法被稱為 FIFO。在 FIFO 排程中,JobTracker 從工作佇列中拉取作業,最老的作業最先。這種排程方法不會考慮作業的優先順序或大小,但很容易實現,而且效率很高。在FIFO 排程器中,小任務會被大任務阻塞。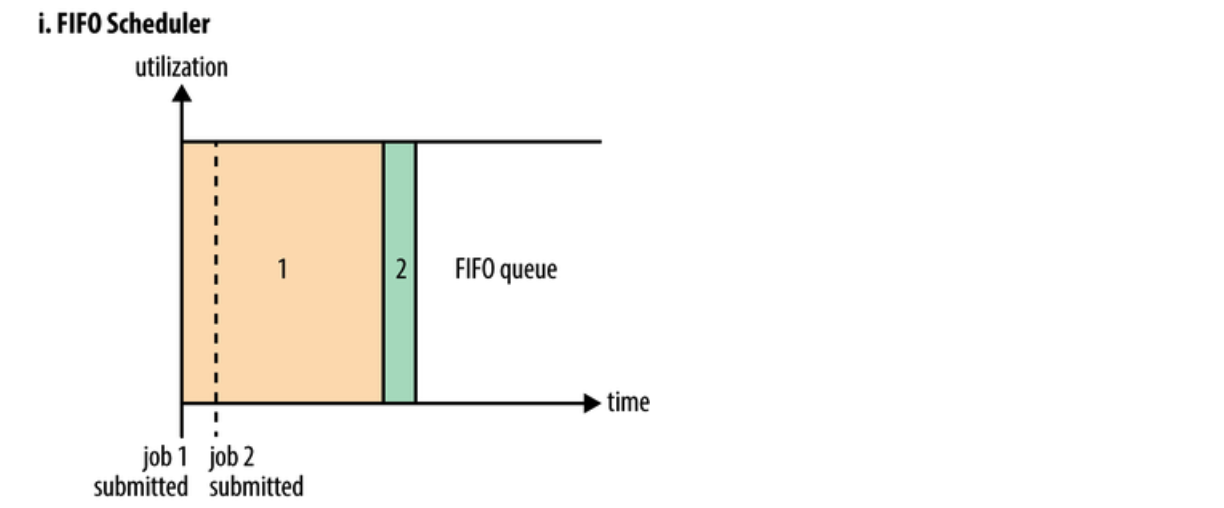
Fair Scheduler(公平排程器)
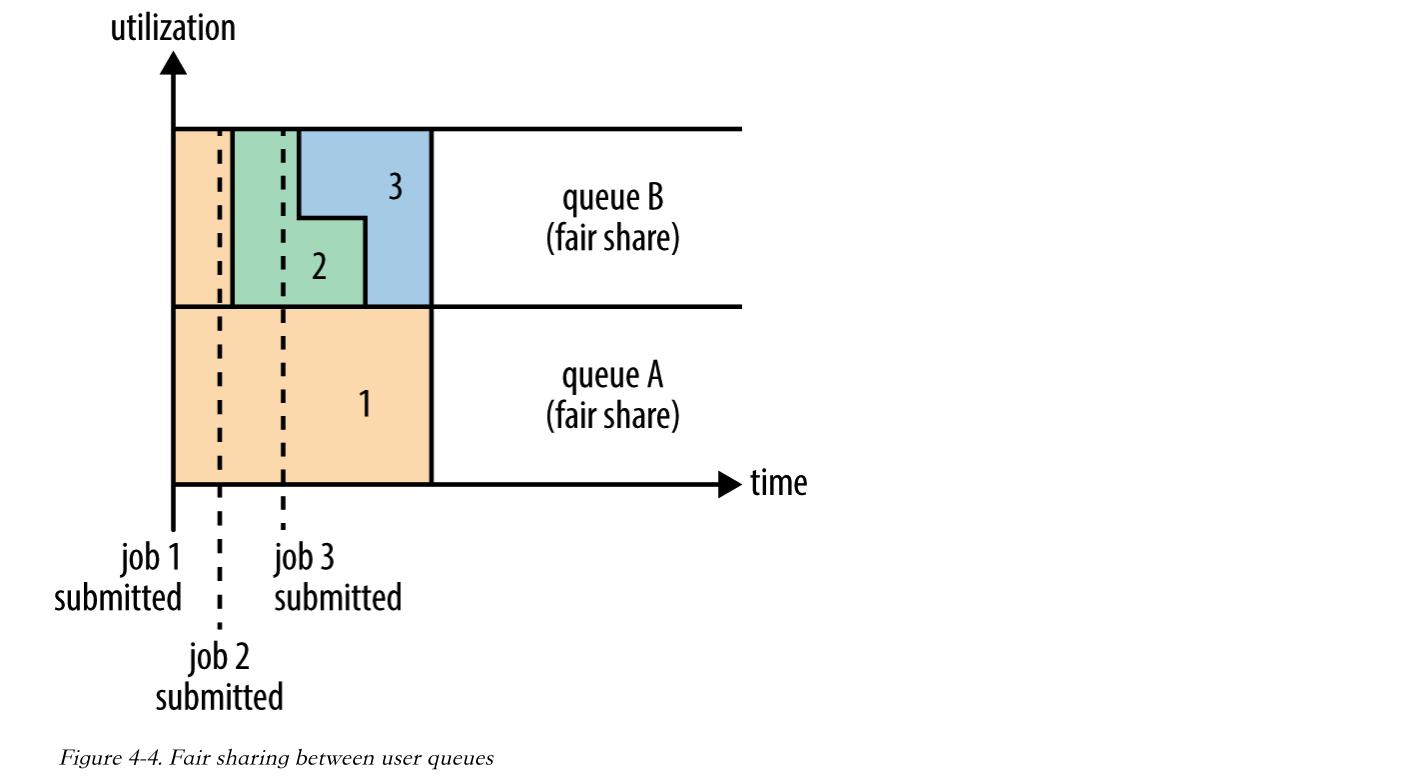
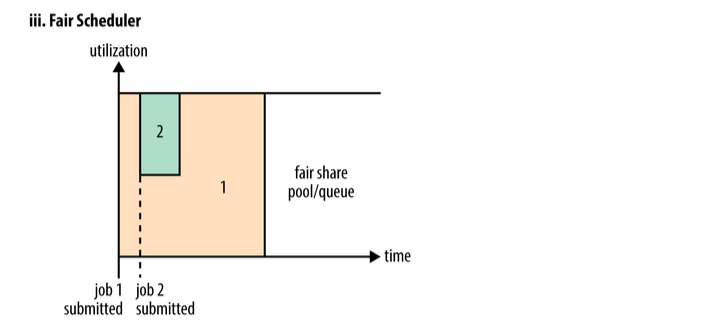 當然,公平排程在也可以在多個佇列間工作。舉個例子,假設有兩個使用者A和B,他們分別擁有一個佇列。當A啟動一個job而B沒有任務時,A會獲得全部叢集資源;當B啟動一個job後,A的job會繼續執行,不過一會兒之後兩個任務會各自獲得一半的叢集資源。如果此時B再啟動第二個job並且其它job還在執行,則它將會和B的第一個job共享B這個佇列的資源,也就是B的兩個job會用於四分之一的叢集資源,而A的job仍然用於叢集一半的資源,結果就是資源最終在兩個使用者之間平等的共享。
當然,公平排程在也可以在多個佇列間工作。舉個例子,假設有兩個使用者A和B,他們分別擁有一個佇列。當A啟動一個job而B沒有任務時,A會獲得全部叢集資源;當B啟動一個job後,A的job會繼續執行,不過一會兒之後兩個任務會各自獲得一半的叢集資源。如果此時B再啟動第二個job並且其它job還在執行,則它將會和B的第一個job共享B這個佇列的資源,也就是B的兩個job會用於四分之一的叢集資源,而A的job仍然用於叢集一半的資源,結果就是資源最終在兩個使用者之間平等的共享。
Capacity Scheduler(容量排程器)
Capacity Scheduler設計用於允許共享一個大型叢集,同時為每個組織提供容量保證。核心思想是Hadoop叢集中的可用資源在多個組織之間共享,這些組織根據計算需求共同為叢集提供資金。另一個好處是,一個組織可以訪問其他組織沒有使用的任何過剩容量。這以一種具有成本效益的方式為組織提供了彈性。 跨組織共享叢集需要對多租戶提供強有力的支援,因為每個組織都必須保證容量和安全,以確保共享叢集不受單個流氓應用程式或使用者或其集合的影響。Capacity Scheduler提供了一組嚴格的限制,以確保單個應用程式、使用者或佇列不能消耗叢集中不成比例的資源。此外,Capacity Scheduler對來自單個使用者和佇列的初始化和掛起應用程式提供了限制,以確保叢集的公平性和穩定性。 在容量排程中,建立的是佇列,每個佇列都會分配一個保證容量(叢集的總容量是每個佇列容量之和)。佇列處於監控之下;如果某個佇列未使用分配的容量,那麼這些多餘的容量會被臨時分配到其他佇列中。由於佇列可以表示一個人或大型組織,那麼所有的可用容量都可以由其他使用者重新分配使用。 為了對資源共享提供進一步的控制和可預見性,Capacity Scheduler支援分層佇列,確保在允許其他佇列使用免費資源之前,在組織的子佇列之間共享資源,從而為在給定組織的應用程式之間共享免費資源提供親和力。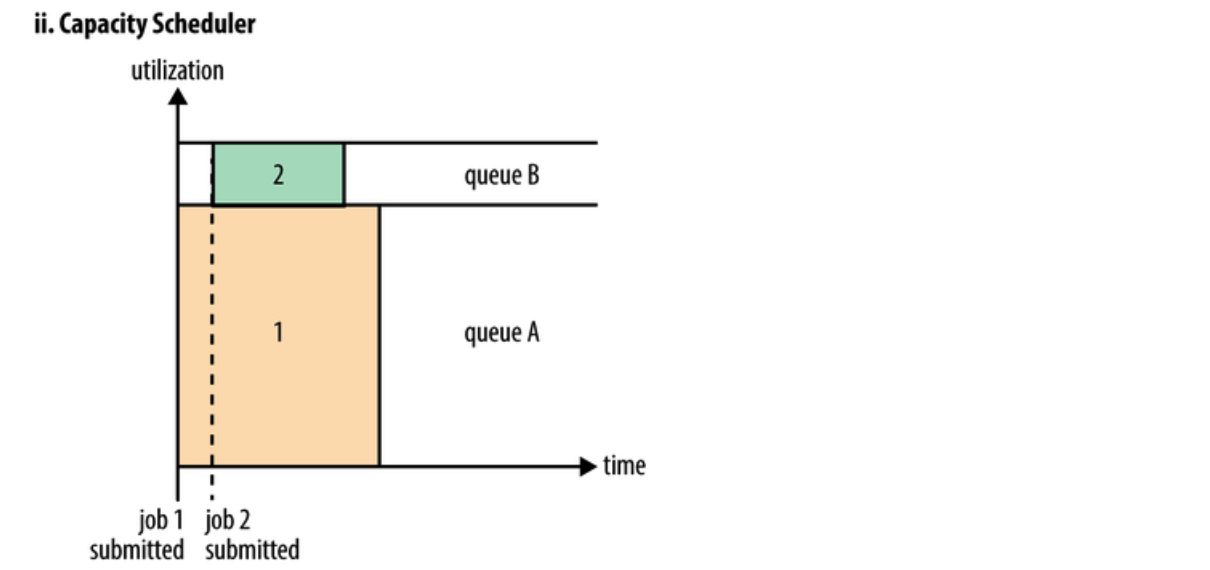
三、LVS的10種排程演算法
靜態演算法:
rr(round robin):輪詢排程演算法:
輪詢排程演算法的原理就是依次將使用者的訪問請求,平均的分配到每一臺web服務節點上,從1開始,到最後一臺伺服器節點結束,然後在開始新一輪的迴圈,這種演算法簡單,但是沒有考慮到每臺節點伺服器的具體效能wrr(weight):權重排程演算法
由於每臺伺服器的效能會高低不同,wrr將會根據管理員設定的權重值來分配訪問請求,權重值越大的,被分到的請求數也就越多,此種演算法有效的解決了rr輪詢演算法的缺點sh(source hashing)源地址雜湊:
主要實現會話繫結,解決session會話共享問題,源地址雜湊會根據請求的源ip地址,作為關鍵字,在靜態分配的hash表中找出對應的伺服器,若該伺服器沒有超過負荷,就將請求分配到該伺服器dh(destination hashing)目標地址雜湊,把同一個ip地址的請求,傳送給同一個server
目標地址雜湊排程演算法是針對目標ip地址的負載均衡,是一種靜態對映演算法,把目標ip地址作為關鍵字,在靜態分配的hash表中找到對應的伺服器,若該伺服器可用並沒有超過負荷,則將請求傳送到該伺服器動態排程演算法:
LC(least connection)最少連線:
當有使用者發起訪問請求時,lc演算法將會把請求分配到叢集中連線數最少的伺服器上wlc(weight least connection scheduling)加權最少連線:
加權最少連線演算法是最少連線的升級版,各個伺服器用想應的權重值表示其處理連線的效能,預設權重值為1,加權最少連線排程在排程訪問請求時,會盡量使伺服器的已建立連線和權重值成比例 也就是活動的連線數除以權重,誰小,挑誰sed(shortest expected)最短延遲排程:
在wlc基礎上進行改進,不在考慮非活動狀態,把當前處於活動狀態的數目+1,數目最小的,則接受下次訪問請求,+1的目的是為了考慮加權的時候,非活動連結過多,當權限過大,會導致非空閒的節點一直處於無連線狀態nq(nerver queue)永不排隊,改進的sed
無需佇列,如果有rs節點的連線數為0,那麼直接將訪問請求分配過去,不需要進行sed運算LBLC(locality based leastconnection)基於區域性性的最少連線
此演算法是根據請求報文的目標ip地址的負載均衡排程,目前主要用於cache集群系統,因為cache叢集中的客戶請求報文的目標ip地址是變化的,這裡假設任何後端伺服器都可以處理任何請求,演算法的設計目標在伺服器的負載劇本平衡的請求下,將相同的目標ip地址的請求排程到同一個伺服器,來提高整個web服務的訪問區域性性和主存cache的命中率,從而調整整個集群系統的處理能力 基於區域性性的最少連線排程演算法根據請求的目標ip地址找出該目標地址最近使用的rs,若該rs可用,將傳送請求,若該伺服器不可用,則用最少連線的原則選出一臺可用伺服器來進行匹配LBLCR(Locality-Based Least Connections withReplication)帶複製的基於區域性性最少連線
此種演算法是針對目標ip地址的負載均衡,該演算法根據請求的目標地址ip找出該地址對應的服務組,按最少連線的原則從服務組中選出一臺伺服器,若伺服器沒有超載,則傳送請求到該伺服器,若該伺服器超載或者不可用,則按照最小連線的原則從這個叢集中選出一臺伺服器,將該伺服器新增到服務組中,在將請求傳送到該伺服器,同時當該伺服器組中有一段時間沒有被修改,將最忙的伺服器從組中剔除,以降低複製的程度四、Nginx的五種排程演算法
rr輪詢演算法:
依次將使用者的訪問請求,平均的分配到後端的web叢集中每個節點,此種演算法不會考慮每個節點的效能,所以比較適用於所有節點的效能一致的情況wrr權重演算法:
根據設定的權重值,權重值越大,被配到的請求次數也就越多,有效的解決了rr演算法的缺點ip_hash演算法:
根據使用者訪問的真實ip生成一個hash表,此後,同一個ip地址的訪問請求都將會分配到這個節點上,可以解決session會話共享的問題url_hash:
根據使用者訪問的url的hash結果,使每個url定向到同一個後端伺服器上fair:
fair是更加智慧的負載均衡演算法,此種演算法可以根據頁面大小的和載入時間長短智慧的進行負載均衡,也就是根據後端節點的響應時間來分配請求,響應時間短的則優先分配,Nginx本身不支援fair,如果需要則必須下載nginx的upstream_fair模組五、gig:自帶負載均衡和降級功能的高可用RPC解決方案
gig的核心功能之一是解決包含網路異常在內的壞節點問題,而不同的系統對異常的定義不同,gig選擇了所有線上系統都有的一個核心指標"查詢延遲"作為節點好壞的評判標準,節點佇列堵塞、網路超時、作業系統負載高等異常情況均能在latency上反應出來。同樣,系統負載也能從latency上體現,因而gig的降級(限流)策略和負載均衡策略也是基於latency的。 如果將線上樹狀系統想象成一個大的水利灌溉系統(gig名字的由來),灌溉者的功能是將水導向系統中阻力最小的部分,既不能讓入口水流堵塞,也不能讓乾旱發生,到gig這裡,水即是流量,阻力則可以近似認為是latency,阻塞是系統吞吐量下跌,乾旱則是負載不均衡。所以gig會統計上圖中每一條邊的平均latency,並據此導流,更進一步,gig還通過控制流量高低來控制每一條邊的latency。 流量控制的目的是為了穩定每一個節點的latency,各個節點的latency差異控制在合理範圍內,對於高latency的節點應該予以遮蔽。為了穩定各個節點的latency,我們設計瞭如下圖所示的負反饋控制器: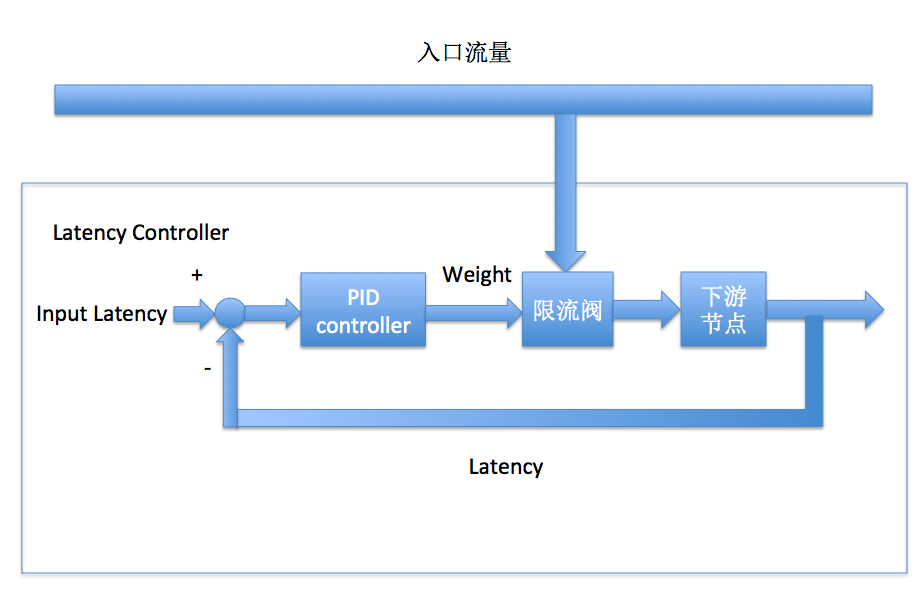 圖中的PID控制器實際上只使用了I(Integral)部分,即一個帶抗飽和功能的積分器,整體是一個過阻尼系統,這樣設計的原因是線上各個系統的Latency-qps關係變化很大,積分本身雖然相應速度慢,但由於線上系統的響應速度快(流量升高時latency會瞬間上升),latency達到預期值後積分器瞬間停止積分,不會超調導致下游節點CPU被打滿。
圖中的PID控制器實際上只使用了I(Integral)部分,即一個帶抗飽和功能的積分器,整體是一個過阻尼系統,這樣設計的原因是線上各個系統的Latency-qps關係變化很大,積分本身雖然相應速度慢,但由於線上系統的響應速度快(流量升高時latency會瞬間上升),latency達到預期值後積分器瞬間停止積分,不會超調導致下游節點CPU被打滿。
六、TPP的負載均衡(流量排程)
ps: 目前的資料僅有一份不太詳細的設計方案設計考慮點
- 機器上線/熱部署事件
- 效能波動
- 服務質量:latency/cpu/load
- 防止雪崩/優先保證不降級
- 單機cache命中率/uid
- 小流量叢集排程
- 叢集不同規格機器支援
權重計算和調節
w1,w2,......wn, 被選中的概率:w(i)/sum(w) 目標: cpu1, cpu2,..... cpun接近相等並保持穩定cpu為cpu_usage, 和ps結果接近,不超過100%. 若為load,則為單core的平均load,預設2已經無法正常服務
- 1/ 指標被歸一化到(0,100)區間
- 2/ 5%誤差, 指標都是週期統計結果,允許一定的波動範圍,避免反覆調節達不到穩定狀態。因此存在20個狀態, 由於cpu等限流因此部分狀態無效
- 3/ 預設權重w=20;若當前機器負載為: cpu1, cpu2,......cpun, 求平均數,按照cpu狀態排序,並按照和平均數的差距進行權重加減, 形成一輪新的w1,w2,.....wn, 而sum(w) 仍然為20*n
- 4/ 機器-1, 重新計算平均數,重複(3)步驟
- 5/ 機器+1, 漸進式擴流量,權重預設為1,重複步驟(3)
- 6/ 機器增減m,同(4),(5)
- 7/ 排程週期:需要根據流量和機器規模設定一個合理值,不能太快也不能太遲鈍,原則是:本地排程完幾乎所有router狀態達到一致,且當前權重下負載達到穩態。當然靈敏肯定沒問題,只要指標最好平滑即可,只是太頻繁調整會浪費效能